

Każda zmiana przepisów AML czy wytycznych ESG wymusza na bankach ponowne dostrojenie modeli AI. Dziś to proces trwający tygodnie i kosztujący setki tysięcy złotych. Metoda RELEX skraca go do kilku dni, redukując koszty obliczeniowe o 85% - bez utraty jakości predykcji.
Problem: regulacje zmieniają się szybciej niż modele
W 2024 roku Komisja Europejska opublikowała 47 stron poprawek do wytycznych AML. Podobne aktualizacje dotyczące raportowania ESG wchodzą w życie średnio co 8 miesięcy. Dla zespołów data science w bankach i ubezpieczycielach oznacza to jedno: kolejny pełny cykl trenowania modelu.
Dostrojenie dużego modelu językowego (LLM) do konkretnego zadania - oceny zdolności kredytowej, wykrywania transakcji wyłudzeniowych czy scoringu zgodności z ESG - zajmuje od dwóch do czterech tygodni na klastrze 64 GPU A100. Przy stawce chmurowej rzędu 3-4 dolarów za GPU/h daje to rachunek na 150-300 tysięcy złotych za jeden cykl. A banki mają takich modeli kilkanaście.
Zespół Zhepei Wei z kilku czołowych instytucji badawczych odkrył, że cały ten proces można zredukować do obserwacji zaledwie 15% pierwotnego czasu treningu. Resztę da się wyliczyć matematycznie, bez dodatkowego zużycia mocy obliczeniowej.
RELEX: jeden kierunek zamiast chaosu
Metoda RELEX (Reinforcement Learning Extrapolation) opiera się na obserwacji, że podczas trenowania LLM metodą RLVR (reinforcement learning z weryfikowalnymi nagrodami) zmiany wag modelu układają się wzdłuż jednego dominującego kierunku. Mówiąc prościej: miliardy parametrów nie aktualizują się chaotycznie - poruszają się jak jeden organizm w jednym wymiarze.
Badacze udowodnili, że rozkładając macierz zmian parametrów (delta wag) za pomocą SVD, można wyizolować pojedynczy komponent rangi-1, który odpowiada za większość przyrostu dokładności. Co więcej, długość wektora w tym kierunku rośnie niemal idealnie liniowo z krokami treningu.
Praktycznie wygląda to tak: trenujesz model przez 50 pierwszych kroków (okno obserwacyjne), wyciągasz dominujący kierunek zmian, dopasowujesz prostą regresję liniową do tempa wzrostu i - gotowe. Checkpointy dla kroku 100, 500 czy 1000 generujesz matematycznie, bez uruchamiania kolejnych epok treningu. Eksperymenty na modelach 1.5B, 4B i 8B parametrów potwierdziły, że tak wyekstrapolowane checkpointy osiągają wyniki równe lub lepsze od pełnego treningu RLVR - zarówno na zadaniach w domenie treningowej, jak i poza nią.
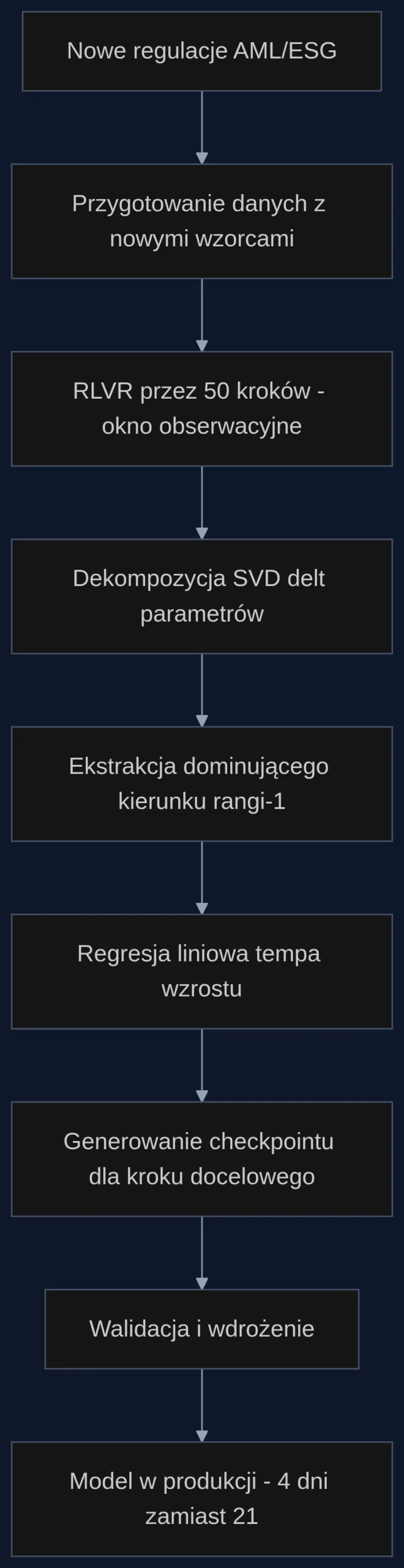
Scenariusz: nowe przepisy AML w poniedziałek, model gotowy w czwartek
Wyobraźmy sobie bank komercyjny z 12 milionami klientów detalicznych. Dział compliance otrzymuje w poniedziałek rano zaktualizowane wytyczne KNF dotyczące klasyfikacji transakcji wysokiego ryzyka - pojawiają się nowe wzorce prania pieniędzy związane z mikropłatnościami w grach mobilnych i obrotem wirtualnymi walutami w platformach gamingowych.
Model flagujący podejrzane transakcje, dotychczas trenowany na danych historycznych z lat 2022-2023, nie rozpoznaje tych wzorców. Zespół AI ma dwa wyjścia: uruchomić pełen cykl RLVR (3 tygodnie, ~220 tys. zł kosztów GPU) albo zastosować RELEX.
W wariancie RELEX proces wygląda następująco:
- Poniedziałek-wtorek: trening na oknie 50 kroków z danymi zawierającymi nowe wzorce (koszt: ~17 tys. zł)
- Środa: dekompozycja SVD delt parametrów, ekstrakcja kierunku rangi-1, dopasowanie regresji liniowej
- Czwartek rano: wygenerowanie checkpointu dla kroku 350 (odpowiednik pełnego treningu) i walidacja na zbiorze testowym
Model osiąga F1-score 0.89 na nowych wzorcach - tyle samo, co model po pełnym, trzytygodniowym treningu. Koszt całkowity: 21 tys. zł. Oszczędność: 199 tys. zł i 17 dni roboczych.
Dlaczego ranga-1 wystarcza - i co to znaczy dla budżetu
Zespół Wei przeprowadził serię ablacji, które rozwiewają naturalną wątpliwość: 'a może trzeba jednak użyć rangi-2 albo rangi-3, żeby nie stracić istotnych niuansów?' Odpowiedź brzmi: nie trzeba. Zwiększanie rangi podprzestrzeni nie poprawiało ekstrapolacji. Modele nieliniowe (wielomiany, małe sieci neuronowe) też nie dawały lepszych wyników niż prosta regresja liniowa.
Przyczyna tkwi w efekcie 'odszumiania'. Pełen proces RLVR zawiera stochastyczne oscylacje - szum optymalizacyjny z mini-batchy - który przy standardowym treningu jest po prostu ignorowany (model i tak zmierza w dobrym kierunku). Ale przy próbie ekstrapolacji ten szum wprowadza błędy. Projekcja na podprzestrzeń rangi-1 odfiltrowuje go, zostawiając czysty sygnał kierunkowy.
Dla dyrektora ds. analityki oznacza to konkretną liczbę w budżecie: przy 12 cyklach dostrajania modeli rocznie (typowa liczba dla średniego banku uwzględniająca zmiany regulacyjne, sezonowość i nowe produkty), przejście z pełnego RLVR na RELEX daje oszczędność rzędu 2.1-2.5 mln zł rocznie na samych kosztach obliczeniowych. Do tego dochodzi wartość szybszego czasu reakcji - model gotowy w 4 dni zamiast 21 to mniejsze ryzyko kar regulacyjnych i strat z tytułu nie wykrytych nadużyć.
Od ryzyka kredytowego po ESG - gdzie RELEX sprawdzi się najszybciej
Metoda nie jest ograniczona do AML. W scoringu kredytowym, gdzie modele muszą uwzględniać nowe dane makroekonomiczne (stopy procentowe, bezrobocie) z opóźnieniem nie większym niż kwartał, RELEX pozwala na comiesięczne odświeżanie modeli bez przekraczania budżetu. W analizie zgodności ESG - gdzie taksonomia unijna jest aktualizowana co kilka miesięcy, a modele klasyfikują aktywa na podstawie setek stron dokumentacji - cykl dostrajania można skrócić z dwóch tygodni do trzech dni.
Największy potencjał RELEX ma tam, gdzie etykiety są weryfikowalne: transakcja jest fraudem albo nie, kredytobiorca spłacił albo nie, firma spełnia kryteria ESG albo nie. To dokładnie domena RLVR - a zatem dokładnie tam, gdzie metoda Wei działa najlepiej.
- Redukcja czasu treningu z 3 tygodni do 4 dni
- Oszczędność 85% kosztów obliczeniowych - ok. 200 tys. zł na cykl
- Roczny saving 2.1-2.5 mln zł przy 12 cyklach dostrajania
- Model gotowy przed upływem deadline'u regulacyjnego
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: You Only Need Minimal RLVR Training: Extrapolating LLMs via Rank-1 Trajectories
Autorzy: Zhepei Wei, Xinyu Zhu, Wei-Lin Chen, Chengsong Huang, Jiaxin Huang i in.
Reinforcement learning with verifiable rewards (RLVR) has become a dominant paradigm for improving reasoning in large language models (LLMs), yet the underlying geometry of the resulting parameter trajectories remains underexplored. In this work, we demonstrate that RLVR weight trajectories are e...
arXiv: arxiv.org/abs/2605.21468
Czytaj więcej o tej technologii: Trenowanie LLM w jednym wymiarze: RELEX oszczędza 85% czasu
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}