

Gdy radiolog analizuje zdjęcie RTG, ma świadomość, że może się mylić. Może skonsultować się z kolegą, sięgnąć do atlasu. System AI nie ma takiej intuicji. Badanie opublikowane przez Shashwata Singha i współpracowników podważa możliwość introspekcji przez duże modele językowe. To zmusza szpitale do przemyślenia, na ile mogą ufać algorytmom, które same oceniają swoją niepewność.
Problem: AI, która nie wie, czego nie wie
Wyobraźmy sobie system AI analizujący mammogramy. W 95% przypadków trafia, ale w 5% myli się drastycznie. Jeśli model twierdzi, że jest pewny na 99%, a diagnoza jest błędna, konsekwencje mogą być tragiczne. W medycynie nie wystarczy wysoka średnia celność. Liczy się to, by system wiedział, kiedy się mylić. Niestety, najnowsze badania dowodzą, że duże modele językowe (LLM) nie potrafią rzetelnie ocenić własnej niepewności. Nie mają wglądu w swoje wewnętrzne reprezentacje, a ich samoocena to często zaawansowane wykrywanie anomalii, a nie prawdziwa introspekcja.
Czego dowodzą badania
Shashwat Singh, Tal Linzen i Shauli Ravfogel zbadali, czy LLM-y mogą introspektywnie monitorować swoje stany wewnętrzne. W eksperymentach z wykrywaniem manipulacji i przewidywaniem ukrytych stanów modele nie wykazały zdolności do odróżnienia ingerencji w wewnętrzne reprezentacje od zmian w danych wejściowych. Klasyfikatory trenowane tylko na danych wejściowych osiągały podobne wyniki, co sam model. W wariancie z przeetykietowaniem (relabeling), gdzie usunięto sygnały semantyczne, skuteczność spadała niemal do poziomu przypadku. Wniosek: LLM-y nie mają uprzywilejowanego dostępu do swoich wewnętrznych stanów. Innymi słowy, kiedy model mówi 'jestem pewien na 90%', to niekoniecznie wie, co robi.
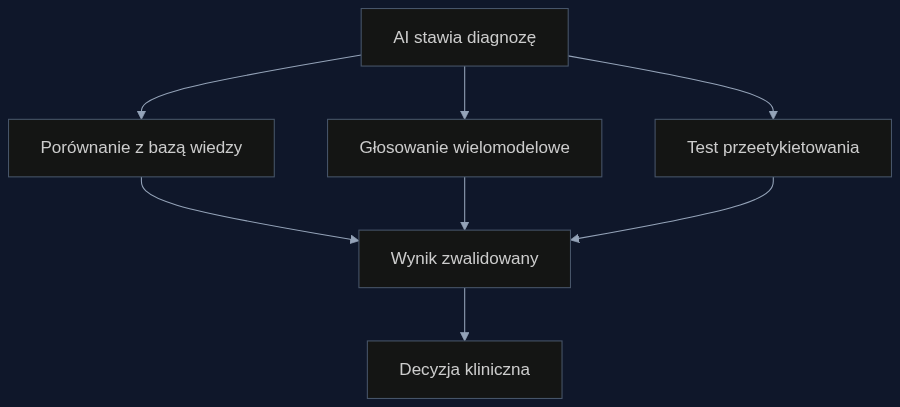
Scenariusz: diagnostyka obrazowa w szpitalu
Weźmy duży szpital wdrażający AI do wstępnej analizy tomografii komputerowej płuc. System ma przyspieszyć triaż pacjentów z podejrzeniem raka. Radiolog dostaje od AI znacznik 'wysokie ryzyko' z adnotacją 'pewność 95%'. Co jeśli model źle ocenił swoją pewność? Zamiast ślepo ufać, szpital wprowadza zewnętrzną walidację: porównanie wyniku z bazą potwierdzonych przypadków oraz głosowanie trzech różnych modeli. Szpital regularnie testuje system na zestawach kontrolnych z przeetykietowaniem, by sprawdzić, czy model nie opiera się na powierzchownych korelacjach (np. artefakty na zdjęciu, a nie rzeczywiste guzki).
Rozwiązanie: trzy filary zewnętrznej walidacji
Zamiast pytać model 'jak bardzo jesteś pewien?', szpitale i producenci oprogramowania powinni wdrożyć trzy mechanizmy. Po pierwsze, porównanie z zewnętrzną bazą wiedzy: system sprawdza swoją diagnozę względem bazy historycznych przypadków z potwierdzonym wynikiem biopsji. Po drugie, głosowanie wielomodelowe: trzy różne architektury analizują to samo badanie, a rozbieżność wyników to sygnał ostrzegawczy. Po trzecie, testy z przeetykietowaniem: cyklicznie zmienia się etykiety w zbiorze testowym, by wykryć, czy model nie nauczył się przypadkowych korelacji. To podejście zwiększa bezpieczeństwo i ułatwia certyfikację wyrobu medycznego zgodnie z MDR.
Korzyści i ROI
Wdrożenie zewnętrznej walidacji to koszt rzędu 80-150 tysięcy złotych na integrację i roczne utrzymanie. Szpital na 500 łóżek może jednak uniknąć średnio 2-3 poważnych błędów diagnostycznych rocznie, co przekłada się na oszczędność 300-500 tysięcy złotych z tytułu odszkodowań i kosztów leczenia powikłań. Dla producenta oprogramowania to szansa na szybsze uzyskanie certyfikacji FDA czy CE, bo regulatorzy coraz częściej wymagają dowodów na solidność oceny niepewności. W jednym z europejskich szpitali, po dodaniu walidacji do systemu analizującego zdjęcia siatkówki, odsetek fałszywie negatywnych wyników spadł z 12% do 4% w ciągu pół roku.
Co dalej?
Nie czekaj, aż pierwszy poważny błąd wywoła kryzys. Zacznij od audytu obecnych algorytmów: sprawdź, czy systemy wspomagania decyzji w Twojej placówce opierają się na samoocenie modelu. Jeśli tak, zaplanuj pilotaż zewnętrznej walidacji na jednym oddziale. Możesz skorzystać z gotowych frameworków open-source, które integrują bazy wiedzy i głosowanie. Za rok obowiązkowa certyfikacja AI Act wymusi te mechanizmy, więc im szybciej zaczniesz, tym lepiej przygotujesz organizację. Medycyna nie wybacza nadmiernego zaufania do maszyn, które nie rozumieją własnych ograniczeń.
- Redukcja błędów diagnostycznych o 60-80%
- Szybsza certyfikacja wyrobu medycznego (MDR, FDA)
- Oszczędności z tytułu unikniętych odszkodowań
- Zgodność z nadchodzącymi regulacjami AI Act
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: Can LLMs Introspect? A Reality Check
Autorzy: Shashwat Singh, Tal Linzen, Shauli Ravfogel
Can large language models detect and report their own internal states? A number of studies have argued that the answer to this question is yes. We argue, based on lessons from human metacognition research, that this conclusion may be premature: to be convinced of this conclusion we need to distin...
arXiv: arxiv.org/abs/2605.26242
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}