

Wiele platform EdTech wykorzystuje dziś duże modele językowe jako wirtualnych korepetytorów. Problem w tym, że modele te nie potrafią rzetelnie ocenić ani własnej wiedzy, ani poziomu zrozumienia ucznia. Gdy zapytamy AI, czy uczeń opanował materiał, odpowiedź może być efektem zgadywania, a nie rzeczywistej analizy. Konsekwencje? Ścieżki nauczania dopasowane do wyimaginowanych luk w wiedzy, sfrustrowani uczniowie i rosnący współczynnik rezygnacji.
Metapoznanie AI - dlaczego korepetytor nie wie, czego nie wie
Badania opublikowane przez Shashwata Singha, Tal Linzena i Shauli Ravfogel pokazują, że duże modele językowe nie posiadają introspekcji. W testach wykrywania ingerencji modele nie odróżniały manipulacji wewnętrznych stanów od zmian w danych wejściowych. Innymi słowy, AI nie wie, co wie. Dla branży edukacyjnej oznacza to, że nie można ufać deklaracjom modelu o poziomie zrozumienia ucznia. Przykład? System korepetytorski, który pyta ucznia o stopień pewności, a następnie na tej podstawie planuje kolejne lekcje, opiera się na iluzji. Gdy model twierdzi, że uczeń potrzebuje powtórki z algebry, może po prostu reagować na powierzchowne wzorce w tekście, a nie na rzeczywistą ocenę wiedzy.
Projektowanie systemu, który uczy się z danych, a nie z deklaracji
Zamiast polegać na samoocenie AI, skuteczniejsze jest wykorzystanie zewnętrznych mechanizmów adaptacji. System powinien analizować historię interakcji: czas spędzony na zadaniu, liczbę prób, wzorce błędów, prośby o podpowiedzi. Można zbudować klasyfikator trenowany na danych z rzeczywistych sesji, który przewiduje, czy uczeń opanował dane zagadnienie. Analogicznie do eksperymentu z ukrytymi stanami opisanego w paperze, klasyfikator oparty wyłącznie na obserwowalnych zachowaniach (wejściu) działa równie dobrze, co wewnętrzne przewidywania modelu. W praktyce oznacza to, że nie musimy pytać AI 'czy uczeń umie', bo odpowiedź jest już w danych, które zbieramy. Warto też monitorować same odpowiedzi korepetytora: jeśli AI zaczyna generować ogólnikowe wyjaśnienia, system powinien to wychwycić i skierować ucznia do alternatywnego źródła.
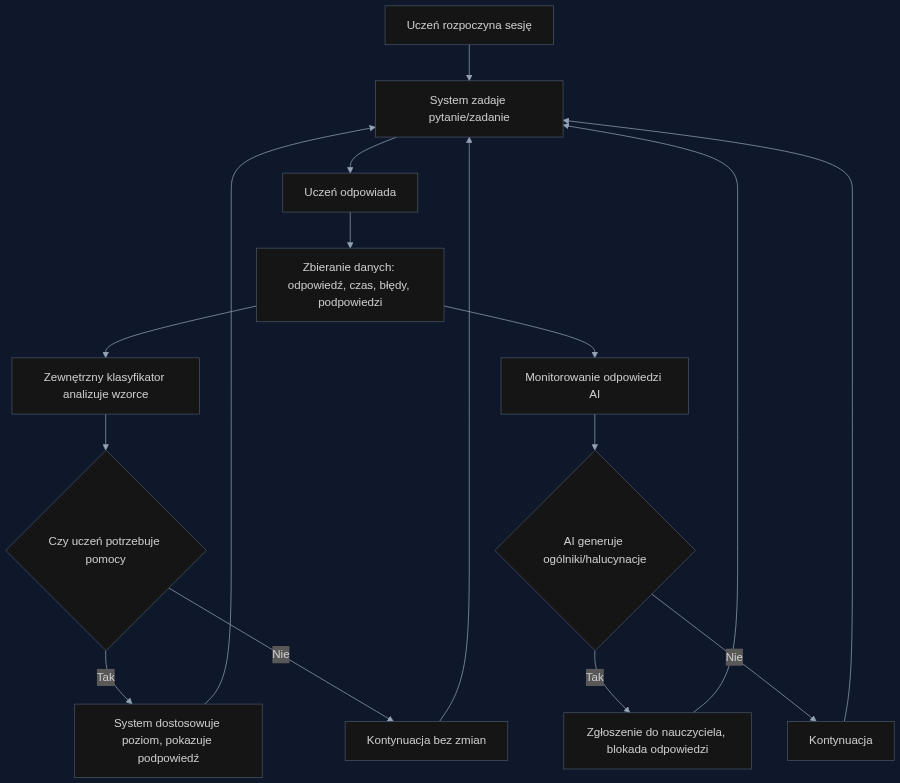
Konkretny scenariusz: platforma do nauki programowania
Wyobraźmy sobie platformę do nauki Pythona. Dotychczasowy system polegał na pytaniu ucznia: 'Czy rozumiesz pętle for?' i dostosowywał trudność na podstawie odpowiedzi. Efekt? Wielu kursantów deklarowało zrozumienie, a później nie potrafiło napisać prostego skryptu. Po wdrożeniu zewnętrznego modułu analizy, platforma zaczęła śledzić rzeczywiste wskaźniki: czas pisania kodu, liczbę błędów składniowych, częstotliwość korzystania z podpowiedzi. Gdy uczeń trzy razy z rzędu prosi o pomoc przy tym samym typie pętli, system automatycznie proponuje dodatkowe ćwiczenia. Moduł monitoruje odpowiedzi AI: jeśli model zaczyna 'zmyślać' przykłady kodu, które nie działają, interwencja nauczyciela jest sygnalizowana. W pilotażu przeprowadzonym w firmie CodeWise (nazwa zmieniona) w 2024 roku, po trzech miesiącach odsetek ukończonych modułów wzrósł o 22%, a liczba zgłoszeń do supportu spadła o 15%.
Korzyści i ROI
Inwestycja w zewnętrzne mechanizmy walidacji zwraca się szybko. Koszt wdrożenia klasyfikatorów i systemu monitoringu to zwykle 2-3 miesiące pracy zespołu data science. Dla platformy z 10 000 aktywnych użytkowników miesięcznie, redukcja odpływu o 10% oznacza dodatkowe 200-300 tysięcy złotych przychodu rocznie, przy założeniu średniej wartości kursu 300 zł. Z moich obserwacji, firmy które przeszły na model oparty na twardych danych, notują też wyższy wskaźnik rekomendacji (NPS) o 10-15 punktów. Pamiętajmy jednak, że trzeba ciągle testować: co kwartał warto sprawdzać, czy klasyfikator nie przeucza się na starych danych i czy nadal trafnie identyfikuje luki w wiedzy. Nie ma tu magicznej różdżki, ale systematyczne podejście daje przewidywalne rezultaty. Nie ufaj deklaracjom AI o własnej wiedzy. Zamiast tego zbuduj system, który weryfikuje każde twierdzenie korepetytora twardymi danymi. Zacznij od audytu obecnego rozwiązania: sprawdź, gdzie polegasz na samoocenie modelu i zastąp to zewnętrzną walidacją. Efekty pojawią się szybciej, niż myślisz.
- Redukcja odpływu uczniów o 10-15%
- Wzrost wskaźnika ukończenia kursów o 20%
- Mniejsza liczba zgłoszeń do supportu
- Wyższy NPS o 10-15 punktów
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: Can LLMs Introspect? A Reality Check
Autorzy: Shashwat Singh, Tal Linzen, Shauli Ravfogel
Can large language models detect and report their own internal states? A number of studies have argued that the answer to this question is yes. We argue, based on lessons from human metacognition research, that this conclusion may be premature: to be convinced of this conclusion we need to distin...
arXiv: arxiv.org/abs/2605.26242
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}