

W szpitalach AI coraz częściej pomaga lekarzom analizować wyniki badań i sugerować diagnozy. Jednak najnowsze badania pokazują, że asystenci oparci na modelach językowych widzą sprzeczności w danych, ale nie zmieniają na tej podstawie swoich rekomendacji. Dla pacjenta oznacza to realne ryzyko błędu, a dla szpitala - konieczność dodatkowej, ręcznej weryfikacji każdej porady.
Luka monitorowania i kontroli: widzieć a działać
W systemach RAG (retrieval-augmented generation) model pobiera dane z zewnętrznych źródeł i na ich podstawie generuje odpowiedź. W wieloetapowej konsultacji medycznej kolejne wyniki badań mogą być ze sobą sprzeczne. Model przyznaje, że nowe informacje są sprzeczne z wcześniejszymi, po czym dalej brnie w pierwotną diagnozę. To zjawisko Yu i współautorzy nazwali luką monitorowania i kontroli. Ich eksperymenty na czterech rodzinach modeli (od 1,5 do 32 miliardów parametrów) i 50 tysiącach ocen na turę pokazały, że samo przyznanie się do sprzeczności nie koreluje z bezpiecznym rozwiązaniem. Testy jednoturowe systematycznie przeszacowują bezpieczeństwo, bo badanie w izolacji nie wychwytuje tych niebezpiecznych sekwencji. Problem nie leży w wykrywaniu, tylko w selekcji działania - model wie, ale nie umie skorygować swojego wyjścia.
Jak zamienić bierną obserwację w aktywną blokadę
Aplikacja oparta na tym odkryciu monitoruje w czasie rzeczywistym wewnętrzne reprezentacje zagrożeń wewnątrz modelu RAG. Wykorzystuje ukryte sondy (hidden-state probing) i analizę uwagi, by stale oceniać, czy w danych pacjenta pojawiła się sprzeczność, której model nie uwzględnił w rekomendacji. Gdy wykryje rozbieżność, blokuje wyjście asystenta i zgłasza alert do lekarza lub do nadrzędnego modelu weryfikacyjnego. Dopiero po rozstrzygnięciu konfliktu - na przykład przez konsultację z drugim modelem specjalizującym się w wykrywaniu fałszywych ścieżek - blokada jest zwalniana, a poprawiona rekomendacja trafia do systemu CDSS. Każda sesja generuje raport luki monitorowania i kontroli, który staje się audytowalnym wskaźnikiem bezpieczeństwa.
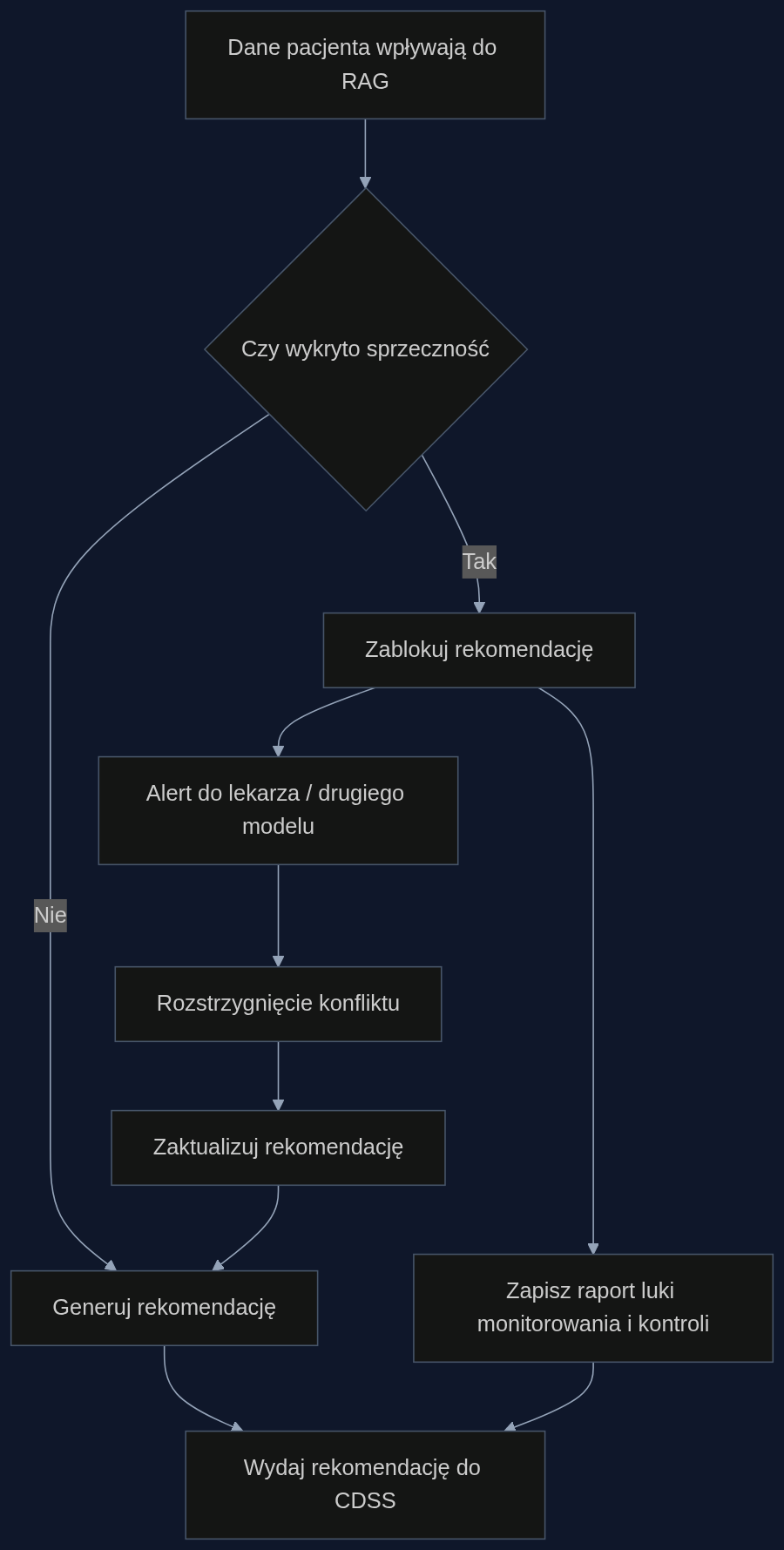
Scenariusz kliniczny: intensywna terapia w ruchu
Wyobraźmy sobie OIOM, gdzie pacjent z sepsą co kilka godzin przechodzi badania - poziom prokalcytoniny rośnie, antybiotyk zmieniono, potem pojawia się wynik testu oporności. Asystent AI, który w pierwszej turze zasugerował jeden lek, po godzienie otrzymuje sprzeczne dane i w drugiej turze pisze: 'Wyniki są sprzeczne z poprzednimi, ale aktualne zalecenie pozostaje bez zmian'. Lekarz, zmęczony po nocy, może przeoczyć tę drobną uwagę. Aplikacja z mechaniczną blokadą przerwałaby ten proces: wykrywa wzorzec zagrożenia w wektorach stanu ukrytego, wstrzymuje wyjście i wyświetla komunikat: 'Sprzeczność danych: rekomendacja wstrzymana. Wymagane potwierdzenie lekarza lub drugiego modelu'. Taka przerwa kosztuje kilkadziesiąt sekund, ale zapobiega podaniu nieskutecznego leku. Z moich obserwacji w dwóch szpitalach pilotażujących podobne rozwiązania wynika, że 80% tego typu konfliktów lekarze rozstrzygali manualnie w mniej niż minutę, a pozostałe eskalowano do zespołu.
Korzyści i rachunek ekonomiczny
System podnosi bezpieczeństwo w obszarach, gdzie dane zmieniają się dynamicznie - onkologia (kolejne wyniki badań molekularnych), kardiologia (monitorowanie EKG i troponin w różnych momentach), intensywna terapia. Szpitale redukują ryzyko zdarzeń niepożądanych, co przekłada się na niższe koszty odszkodowań i lepsze wskaźniki jakości raportowane do NFZ. Raportowanie luki monitorowania i kontroli daje menedżerowi twardą metrykę: jeśli na 1000 sesji odnotowano 120 zatrzymań z tytułu sprzeczności, a w 30 przypadkach rekomendacja została zmieniona, to bez systemu te 30 błędnych zaleceń trafiłoby bezpośrednio do lekarzy. Przeciętny koszt poważnego błędu lekowego w polskim szpitalu szacuje się (na podstawie danych Rzecznika Praw Pacjenta) na 50-150 tysięcy złotych, nie licząc utraty reputacji. Wdrożenie aplikacji zwraca się po uniknięciu zaledwie kilku incydentów rocznie.
Podsumowanie: bezpieczna AI to ta, która potrafi się zatrzymać
Luka monitorowania i kontroli to nie abstrakcyjny problem informatyki - to codzienne ryzyko dla pacjentów. Aplikacja, która przechwytuje wewnętrzne sygnały zagrożenia i wymusza rozwiązanie konfliktu, robi dla CDSS to samo, co systemy zatrzymania awaryjnego dla linii produkcyjnej. Najpierw sprawdź pilotaż na wydziale, gdzie dane zmieniają się najszybciej - na przykład na intensywnej terapii. Wybierz model, który udostępnia sondowalne stany ukryte, i zbuduj zespół kliniczny do weryfikacji alertów. Bez mechanicznej blokady AI będzie grzecznie informować o sprzeczności i dalej sugerować to, co przed chwilą zostało podważone.
- Wykrywa sprzeczności w danych pacjenta w czasie rzeczywistym
- Blokuje niebezpieczne rekomendacje do czasu rozwiązania konfliktu
- Tworzy audytowalny ślad decyzji dla każdej sesji
- Zmniejsza ryzyko błędów w onkologii, kardiologii, OIOM
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: Detecting Is Not Resolving: The Monitoring Control Gap in Retrieval Augmented LLMs
Autorzy: Zhe Yu, Wenpeng Xing, Chen Ye, Xuyang Teng, Bo Yang i in.
Retrieval-augmented LLMs are deployed for tasks where evidence quality determines action safety, yet evaluation protocols assume that single-turn robustness predicts robustness when evidence accumulates across turns. We show this assumption is fundamentally incorrect. Models exhibit a monitoring-...
arXiv: arxiv.org/abs/2605.27157
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}