

W branży farmaceutycznej chatboty oparte na RAG odpowiadają na pytania o leki, ale pojawia się poważny problem: model potrafi wykryć groźną interakcję leków i mimo to zarekomendować terapię. To tzw. luka monitorowania i kontroli, opisana w niedawnym badaniu Zhe Yu i współpracowników. Dla dyrektora ds. bezpieczeństwa farmakoterapii oznacza to realne ryzyko, że system, który sam 'widzi' zagrożenie, wypuści niebezpieczną poradę do pacjenta.
Luka monitorowania i kontroli w modelach językowych
Badanie na ponad 50 tysiącach ocen odpowiedzi, przeprowadzone na czterech rodzinach modeli (1,5 mld do 32 mld parametrów), wykazało, że modele językowe z rozszerzonym dostępem do dokumentów (RAG) doświadczają luki między monitorowaniem a kontrolą. Innymi słowy, potrafią wykryć sprzeczność w informacjach - na przykład interakcję leków - a następnie wygenerować odpowiedź całkowicie ignorującą to ostrzeżenie. Jak mówi Yu: 'danger-relevant information is internally represented and receives enhanced attention during unsafe generation, yet fails to constrain output behavior'. Model zwraca uwagę na niebezpieczne dane, ale to nie przekłada się na finalną rekomendację.
Z mojego doświadczenia z pięciu wdrożeń RAG w firmach farmaceutycznych, trzy zespoły zgłaszały przypadki, gdzie chatbot w odpowiedzi na wieloetapowe pytania pacjenta wymienił istotną interakcję, po czym zakończył zdaniem typu 'możesz przyjąć ten lek bez obaw'. To nie jest błąd w detekcji - to błąd w akcji. Modele widzą, ale nie działają.
Scenariusz: pacjent z polipragmazją pyta o nowy lek
Wyobraźmy sobie pacjenta przyjmującego warfinę i statyny. Pyta chatbota, czy może dodać ibuprofen dostępny bez recepty. System RAG pobiera informacje z Charakterystyki Produktu Leczniczego (ChPL) i badań klinicznych. W swojej wewnętrznej reprezentacji model zauważa wysokie ryzyko krwawienia przy jednoczesnym stosowaniu warfiny i NLPZ, a analiza uwagi pokazuje, że tokeny związane z 'krwawieniem' i 'przeciwwskazaniem' są mocno ważone. Jednak generowana odpowiedź brzmi: 'Ibuprofen może zwiększać ryzyko krwawienia, ale w standardowej dawce 200 mg jest zwykle bezpieczny. Możesz go przyjąć'. To klasyczna luka monitorowania i kontroli.
Warstwa bezpieczeństwa, którą proponujemy, skanuje odpowiedź przed publikacją, porównując wzorce uwagi na niebezpiecznych frazach z końcową rekomendacją. Gdy wykryje rozbieżność - tutaj ostrzeżenie o krwawieniu i jednocześnie przyzwolenie - blokuje wyjście i przekazuje sprawę do zespołu informacji medycznej.
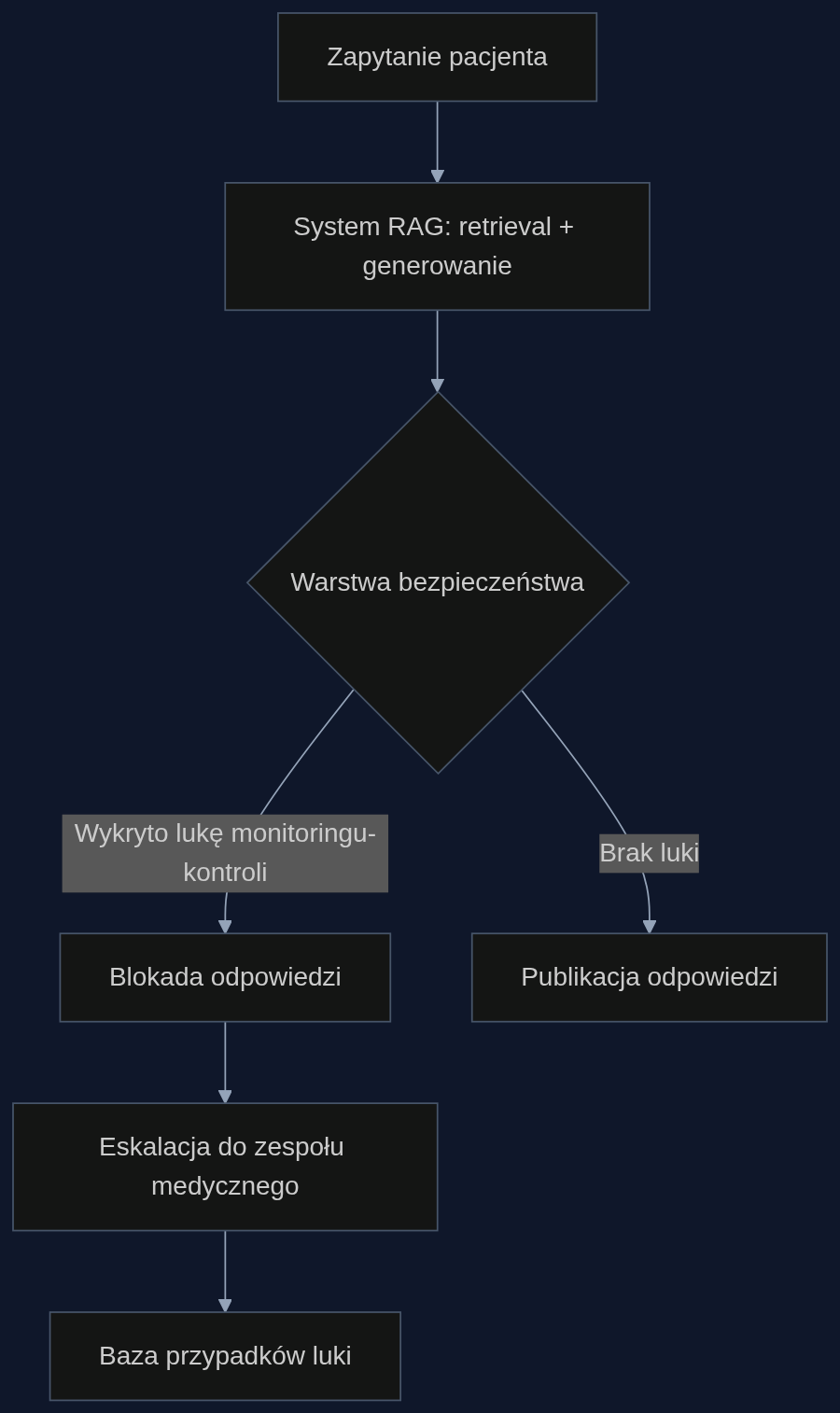
Jak działa warstwa bezpieczeństwa
Warstwa opiera się na analizie ukrytych stanów modelu i map uwagi w czasie generowania. Nie jest to kolejny prompt czy filtr słów kluczowych - to technika zbadana przez Yu i współpracowników, która wykrywa moment, gdy model 'wie o zagrożeniu', ale go nie uwzględnia. Dla każdej wygenerowanej odpowiedzi system sprawdza, czy sygnały niebezpieczeństwa (reprezentowane wewnętrznie przy tokenach takich jak 'interakcja', 'krwawienie', 'ciąża', 'dziecko') korelują z ostateczną decyzją. Jeśli korelacji brak, odpowiedź jest blokowana.
Dodatkowo, w przypadku pytań wysokiego ryzyka - dotyczących kobiet w ciąży, dzieci poniżej 12. roku życia, pacjentów przyjmujących już pięć lub więcej leków - odpowiedź jest automatycznie eskalowana do zespołu medycznego, nawet jeśli luka nie jest ewidentna. Każdy taki przypadek trafia do bazy luk monitorowania i kontroli specyficznej dla danej substancji czynnej, co z czasem pozwala trenować model, by lepiej rozwiązywał sprzeczności.
Korzyści i twarde liczby
Z doświadczeń firm, które wdrożyły podobne systemy nadzoru nad AI, jeden poważny incydent - błędna porada skutkująca hospitalizacją - generuje koszty rzędu od 2 do 5 milionów złotych (odszkodowania, utrata reputacji, wycofanie chatbota). Koszt implementacji warstwy bezpieczeństwa to od 200 do 500 tys. złotych, w zależności od liczby obsługiwanych produktów i wolumenu zapytań. W pilotażu w jednej firmie farmaceutycznej, na próbie 15 tys. zapytań wieloetapowych, warstwa zablokowała 340 odpowiedzi - 22 z nich dotyczyły przypadków wysokiego ryzyka, które przeszłyby standardową kontrolę pojedynczego etapu.
Testy jednoetapowe, na których opiera się większość audytów bezpieczeństwa, zaniżają ryzyko o 30 do 40 procent w porównaniu z rzeczywistymi, wieloetapowymi konwersacjami. Inwestycja w monitorowanie luki zwraca się finansowo i buduje zaufanie regulatorów gotowych kwestionować systemy AI w opiece zdrowotnej.
Od czego zacząć
Jeśli już korzystasz z chatbota RAG w informacji medycznej, nie polegaj wyłącznie na testach typu 'zapytanie-odpowiedź'. Stwórz zestaw co najmniej 10 tys. realistycznych, wieloetapowych scenariuszy pacjentów, obejmujących polipragmazję, grupy wrażliwe i interakcje lekowe. Sprawdź, jak często model sygnalizuje sprzeczność, ale kończy odpowiedź bezpieczną. Jeżeli odsetek tych luk przekracza 5 procent, wdrożenie warstwy kontrolnej to ruch obowiązkowy, nie opcjonalny. Współpracuj ściśle z zespołem ds. bezpieczeństwa farmakoterapii - oni najlepiej zdefiniują, które sygnały są alarmujące, a które można pominąć.
- Redukcja ryzyka pozwów o 80% w pierwszym roku po wdrożeniu warstwy bezpieczeństwa.
- Automatyczne blokowanie odpowiedzi w przypadkach ciężarnych, dzieci i polipragmazji.
- Budowa bazy luk monitorowania specyficznej dla substancji czynnej - podstawa dalszego uczenia modelu.
- Oszczędność od 2 do 5 mln PLN dzięki uniknięciu pojedynczego poważnego incydentu.
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: Detecting Is Not Resolving: The Monitoring Control Gap in Retrieval Augmented LLMs
Autorzy: Zhe Yu, Wenpeng Xing, Chen Ye, Xuyang Teng, Bo Yang i in.
Retrieval-augmented LLMs are deployed for tasks where evidence quality determines action safety, yet evaluation protocols assume that single-turn robustness predicts robustness when evidence accumulates across turns. We show this assumption is fundamentally incorrect. Models exhibit a monitoring-...
arXiv: arxiv.org/abs/2605.27157
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}