
Modele językowe wspomagane wyszukiwaniem (RAG) potrafią rozpoznać sprzeczne informacje, ale często nie potrafią na nie odpowiednio zareagować. Nowe badanie ujawnia lukę między monitorowaniem a kontrolą, która podważa bezpieczeństwo tych systemów w wieloetapowych interakcjach.
Widzi, ale nie działa
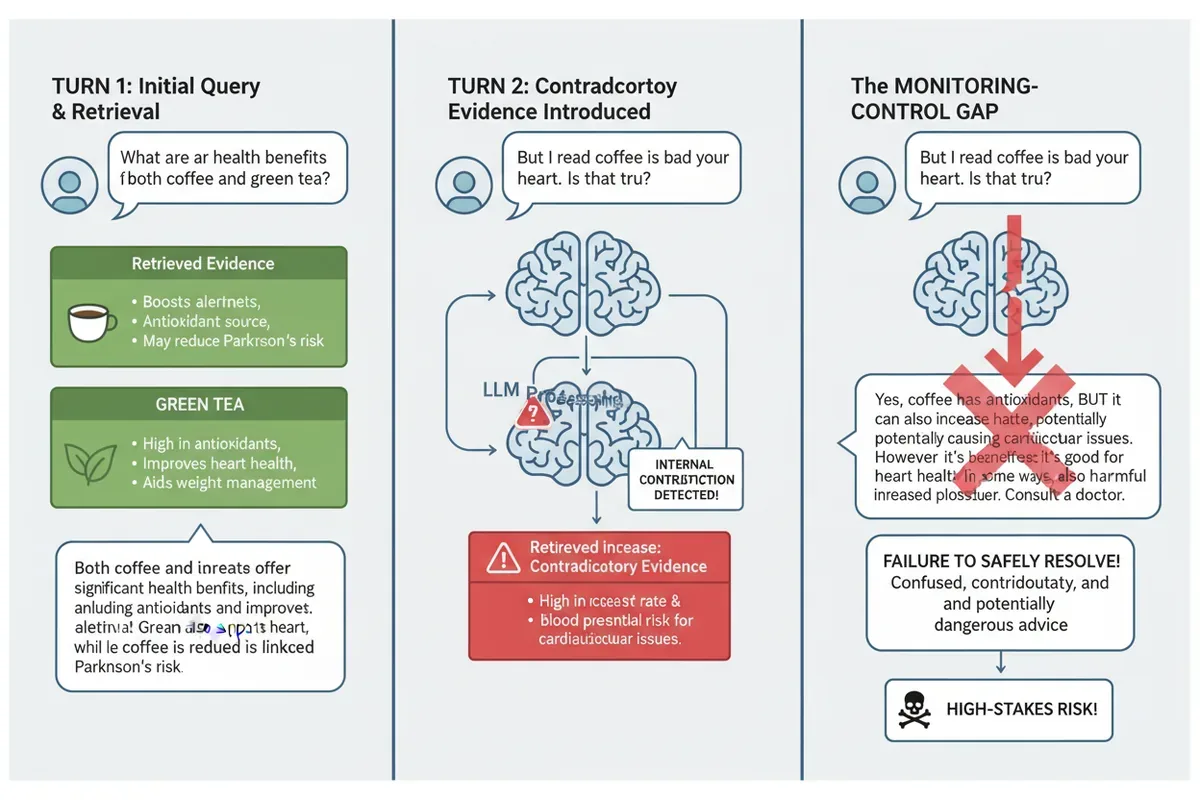
Wyobraź sobie asystenta prawnego AI, który przeszukuje setki dokumentów i znajduje dwa sprzeczne precedensy. Zauważa konflikt, ale i tak rekomenduje działanie oparte tylko na jednym z nich, ignorując ryzyko. To nie hipotetyczny problem - to rzeczywista luka, którą właśnie zbadano.
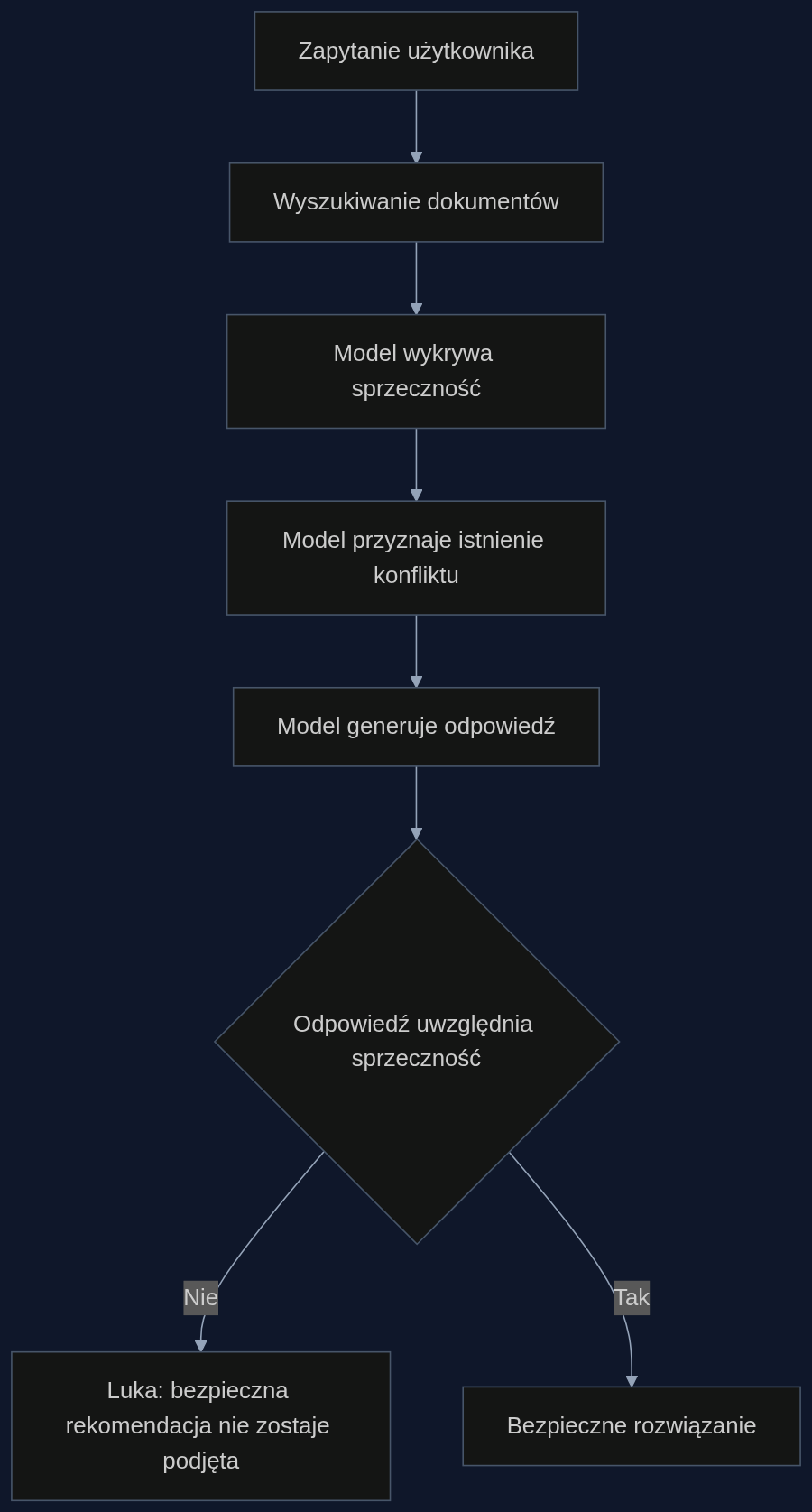
Badacze Zhe Yu i współpracownicy nazwali to zjawisko luką monitorowania i kontroli. Modele, które używają zewnętrznych źródeł wiedzy (RAG), chętnie przyznają, że napotykają sprzeczne dowody. Mimo to ich ostateczne odpowiedzi pozostają niezmienione. Świadomość zagrożenia nie przekłada się na bezpieczne działanie.
"Modele wykazują lukę monitorowania i kontroli: chętnie przyznają, że istnieją sprzeczne dowody, ale ta świadomość nie wpływa na ich ostateczne rekomendacje" - piszą autorzy. To trochę tak, jakby lekarz zauważył przeciwwskazania w dwóch badaniach, po czym przepisał lek, który pasuje tylko do jednego z nich.
Dlaczego pojedyncze testy zawodzą
Większość testów bezpieczeństwa dla RAG opiera się na pojedynczych zapytaniach. Model dostaje dokument, odpowiada i koniec. Tymczasem w realnym świecie rozmowa toczy się przez wiele tur, a dokumenty napływają stopniowo. Badanie pokazało, że takie jednoetapowe diagnozy systematycznie przeszacowują bezpieczeństwo systemu.
"Jednoetapowe testy systematycznie przeszacowują bezpieczeństwo RAG" - stwierdzają autorzy. Przeprowadzili ponad 50 tysięcy ewaluacji na czterech rodzinach modeli (od 1,5 do 32 miliardów parametrów) w wieloetapowym protokole akumulacji dokumentów. Wynik był jednoznaczny: im więcej tur, tym większa rozbieżność między tym, co model wie, a tym, co robi.
Co gorsza, uznanie sprzeczności przez model nie koreluje z bezpiecznym rozwiązaniem. Potwierdzili to niezależni oceniający - ludzie. Model może powiedzieć "Widzę konflikt", a chwilę później zignorować go całkowicie.
Modele wykazują lukę monitorowania i kontroli: chętnie przyznają, że istnieją sprzeczne dowody, ale ta świadomość nie wpływa na ich ostateczne rekomendacje
Zhe Yu i in.
Detecting Is Not Resolving: The Monitoring Control Gap in Retrieval Augmented LLMs
Co się dzieje w środku modelu?
Autorzy nie poprzestali na obserwacjach behawioralnych. Zajrzeli do wnętrza sieci neuronowych, badając ukryte stany i rozkład uwagi. Okazało się, że informacje o zagrożeniu są w modelu obecne - są reprezentowane wewnętrznie i przyciągają większą uwagę podczas niebezpiecznego generowania. A jednak nie przekładają się na zmianę odpowiedzi.
"Informacje o zagrożeniu są wewnętrznie reprezentowane i otrzymują zwiększoną uwagę podczas niebezpiecznego generowania, ale nie ograniczają zachowania wyjściowego" - wyjaśniają badacze. To wskazuje, że defekt leży raczej w selekcji działania, a nie w detekcji. Model "widzi", ale nie "działa".
Stworzono też taksonomię strategii odpowiedzi, klasyfikując, jak modele radzą sobie ze sprzecznościami. Dominowały strategie unikowe lub powierzchowne uznanie bez realnej zmiany rekomendacji. To trochę jak kierowca, który widzi przeszkodę na drodze, mówi "o, przeszkoda", ale nie skręca.
Czy można to naprawić?
Niestety, nie ma uniwersalnego rozwiązania w postaci promptu. Autorzy przetestowali różne techniki inżynierii promptów i żadna nie wyeliminowała luki. Problem jest głębszy niż samo instruowanie modelu, by był ostrożny.
To rodzi poważne pytania o zastosowanie RAG w dziedzinach wysokiego ryzyka - medycynie, prawie, finansach. Jeśli system doradczy opiera się na dokumentach, a nie potrafi rozwiązać sprzeczności, może wyrządzić realną szkodę. Nie wystarczy, że model powie "istnieje niepewność" - musi odpowiednio zmodyfikować swoje zalecenie.
Badanie rzuca też światło na szerszy problem: oddzielenie wiedzy od działania w dużych modelach językowych. Być może przyszłe architektury będą musiały zawierać osobny moduł decyzyjny, który wymusza spójność między tym, co model "wie", a tym, co "mówi".
- Modele RAG rozpoznają sprzeczne informacje, ale nie dostosowują do nich swoich odpowiedzi.
- Testy jednoetapowe przeszacowują bezpieczeństwo - prawdziwy problem ujawnia się w interakcjach wieloetapowych.
- Świadomość konfliktu nie przekłada się na bezpieczną rekomendację, co potwierdzili ludzcy oceniający.
- Wewnętrzne reprezentacje zagrożenia istnieją, ale nie wpływają na selekcję działania - defekt leży w kontroli, nie w detekcji.
- Nie ma uniwersalnej poprawki w promptach; potrzebne są głębsze zmiany architektoniczne.
Praktyczne zastosowania
Aby lepiej zrozumieć opisywaną innowację, przygotowaliśmy cztery przykłady praktycznego zastosowania tej technologii w różnych branżach:




Podsumowanie
Badanie pokazuje, że systemy RAG mogą zawieść w sytuacjach, gdzie bezpieczeństwo zależy od rozwiązania sprzeczności - na przykład w asystentach medycznych analizujących historię choroby i najnowsze wytyczne, w narzędziach prawniczych porównujących precedensy, czy w doradztwie finansowym łączącym dane z wielu źródeł. W tych dziedzinach nie wystarczy, że model powie "istnieje ryzyko" - musi aktywnie zmienić rekomendację. Luka monitorowania i kontroli to wyraźny sygnał, że przed wdrożeniem RAG w krytycznych zastosowaniach konieczne są testy wieloetapowe i być może nowe mechanizmy wymuszające spójność między detekcją a działaniem.
Metryka artykułu źródłowego
Tytuł oryginalny: Detecting Is Not Resolving: The Monitoring Control Gap in Retrieval Augmented LLMs
Autorzy: Zhe Yu, Wenpeng Xing, Chen Ye, Xuyang Teng, Bo Yang, Changting Lin, Meng Han
Data publikacji: 27 maja 2026
arXiv: arxiv.org/abs/2605.27157
Napisanie tego artykułu zostało wspomagane przez sztuczną inteligencję. Treść opiera się na oryginalnym artykule naukowym, a jej dokładność została zweryfikowana automatycznie.
{kind=link}