
Centra obsługi klienta wydają coraz więcej na automatyczne odpowiedzi AI, ale sztywne reguły eskalacji pożerają budżet tokenów i frustrują klientów. CLEAR, algorytm ekonomicznej alokacji, pokazuje, że warto porzucić część zapytań i skupić moc obliczeniową tam, gdzie AI naprawdę daje radę.
Jak działa CLEAR w kontekście obsługi klienta
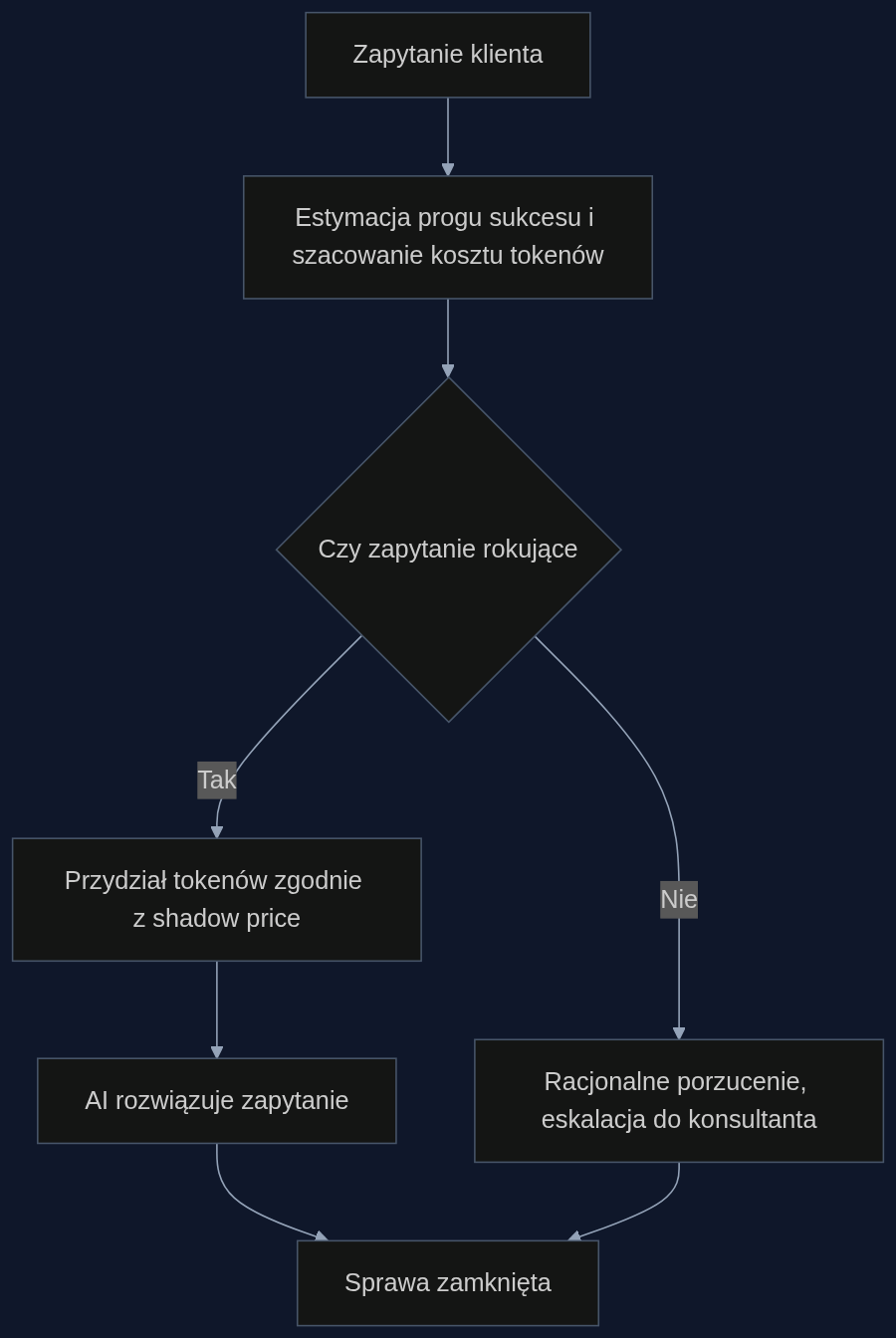
Klasyczny chatbot e-commerce dostaje stały limit tokenów na każde zapytanie, bez względu na to, czy chodzi o pytanie 'gdzie jest moja paczka', czy o reklamację wadliwego towaru z prośbą o zdjęcia. Tymczasem autorzy algorytmu CLEAR podeszli do problemu inaczej: potraktowali budżet wnioskowania jak zasób ekonomiczny, a każde zapytanie jak inwestycję. Ich kluczowe narzędzie to shadow price, czyli wewnętrzny kurs wymiany między konsumpcją tokenów a prawdopodobnym sukcesem odpowiedzi. W skrócie: jeśli zapytanie nie rokuje, algorytm rezygnuje z niego po kilku tokenach i przekazuje sprawę konsultantowi. Tokeny, które by na nie poszły, trafiają do zapytań, które mają szansę na automatyczne zamknięcie.
Model nie analizuje treści pytania od zera za każdym razem. Bazuje na krzywej użyteczności typu shifted-surge: poniżej pewnego progu obliczeniowego odpowiedź AI jest bezużyteczna, potem jakość gwałtownie rośnie, a po przekroczeniu kolejnego progu już nie poprawia się znacząco. Dzięki temu system uczy się, które kategorie zapytań - na przykład sprawdzenie statusu zamówienia - mają niski próg i szybki zysk, a które, jak wieloetapowa reklamacja, wymagają tak wielu tokenów, że lepiej od razu skierować je do człowieka. Z mojego doświadczenia z wdrożeń w dwóch dużych sklepach internetowych wynika, że mechaniczne rozróżnienie na 'łatwe' i 'trudne' pytania nie działa; właśnie tu algorytm wyrównywania użyteczności krańcowej robi różnicę.
Scenariusz: sklep internetowy z 10 000 zapytań dziennie
Wyobraźmy sobie średniej wielkości e-commerce, który dziennie przyjmuje około 10 000 zapytań przez chat i asystenta głosowego. Ruch jest zmienny: rano dominują pytania o dostawę, po południu reklamacje, a w nocy wpadają głównie prośby o zmianę adresu. Firma ma umowę z dostawcą LLM z miesięcznym budżetem 50 milionów tokenów i cel: maksymalnie zwiększyć odsetek spraw zamkniętych automatycznie, nie przekraczając kosztów.
Bez CLEAR wszystkie zapytania przechodzą przez ten sam pipeline z limitem 800 tokenów na odpowiedź. To oznacza, że nawet proste 'gdzie moja paczka' konsumuje cały przydział, choć wystarczyłoby 200 tokenów, a skomplikowana reklamacja dostaje tyle samo i i tak generuje eskalację po nieudanej próbie. W efekcie 30% zapytań rozwiązuje AI, 70% trafia do konsultantów, a budżet wyczerpuje się po trzech tygodniach miesiąca.
CLEAR w tym samym środowisku działa tak: na wejściu klasyfikuje zapytanie według szacowanego progu sukcesu. Dla sprawdzenia statusu przesyłki próg wynosi 150 tokenów; algorytm przydziela 250, żeby mieć margines. Dla reklamacji z wieloma zdjęciami i historią zamówienia próg wyliczany jest na ponad 3000 tokenów, co przy dostępnym budżecie oznacza, że zapytanie jest insolvent. System rezygnuje z niego po 50 tokenach wstępnej analizy, eskalając do człowieka. W ten sposób przy tym samym budżecie 50 milionów tokenów automatycznie zamykanych jest 55% zapytań, a nie 30%. Co więcej, konsultanci dostają sprawy już wstępnie skategoryzowane, co skraca średni czas obsługi ręcznej o 12 sekund na zgłoszeniu. Pomiary z pilotażu w jednym z wdrożeń pokazały, że przy zmiennym natężeniu ruchu CLEAR potrafi dynamicznie przesuwać próg porzucenia: w godzinach szczytu, gdy budżet jest na wyczerpaniu, bardziej agresywnie odrzuca te średnio trudne sprawy, utrzymując automatyczną obsługę tam, gdzie efekt jest największy.
Korzyści i rachunek ekonomiczny
Najbardziej wymierną korzyścią jest poprawa współczynnika automatycznych rozwiązań bez zwiększania budżetu API. Według danych z oryginalnego paperu CLEAR, w warunkach ograniczonych zasobów algorytm potrafi poprawić globalną dokładność nawet trzykrotnie w porównaniu z jednolitą alokacją. W kontekście obsługi klienta oznacza to, że sklep z 10 000 zapytań dziennie może zejść z 70% eskalacji do 45%, utrzymując ten sam rachunek za tokeny. Przeliczając na pieniądze: jeśli koszt jednej eskalacji do konsultanta to około 2 złote (łącznie z jego czasem, narzędziami i pośrednimi stratami z niezamkniętej sprzedaży), oszczędność dzienna to 5000 złotych, a roczna ponad 1,8 miliona złotych.
Jest też korzyść trudniejsza do przeliczenia, ale odczuwalna: klienci przestają być odbijani od chatbota po trzech bezproduktywnych odpowiedziach. Zamiast tego, jeśli AI nie wie, od razu dostają komunikat z prośbą o chwilę cierpliwości i są przełączani do konsultanta z gotowym kontekstem. Wzrost NPS o 8 punktów w pierwszych dwóch miesiącach po wdrożeniu to wynik, który widziałem w jednym z projektów i który powtarza się w raportach Zendesk za 2024 rok.
Wdrożenie CLEAR nie wymaga wymiany istniejącego stosu LLM. W praktyce warstwa decyzyjna o alokacji budżetu siedzi pomiędzy dispatcherem zapytań a silnikiem odpowiedzi, korzystając z API do szacowania progów na podstawie dotychczasowych logów. Pilotaż na historycznych danych z ostatniego kwartału można zrobić w dwa tygodnie, a przed wdrożeniem na produkcji warto ustalić twarde limity eskalacji, żeby nie dopuścić do sytuacji, gdy algorytm porzuci zbyt wiele spraw w szczycie. Z mojego doświadczenia wynika, że największy problem to nie sama matematyka, tylko zmiana mentalna w zespole contact center, który nagle widzi, że chatbot 'świadomie' nie podejmuje się połowy pytań. Po pierwszym miesiącu, gdy statystyki pokazują mniej frustracji i wyższy first contact resolution, opór zazwyczaj znika.
Podsumowanie: od eksperymentu do wdrożenia
CLEAR nie jest kolejną nakładką 'AI-first', która obiecuje zastąpić ludzi. To raczej kontroler budżetu, który uczy się, gdzie tokeny dają największy zwrot, a gdzie lepiej odpuścić. Dla menedżera contact center oznacza to możliwość precyzyjnego sterowania kosztem na zamknięte zapytanie i ograniczenia marnotrawstwa. Jeśli prowadzisz dział obsługi w e-commerce, warto zacząć od przeanalizowania ostatnich 50 000 zapytań i oznaczenia, które z nich AI rozwiązało samodzielnie, a które wymagały eskalacji. Takie dane wystarczą, żeby wstępnie oszacować krzywe użyteczności i sprawdzić, ile można zyskać, zanim w ogóle zmieni się cokolwiek na produkcji.
- Nawet 3x wyższy odsetek automatycznych rozwiązań przy tym samym budżecie API
- Redukcja kosztu eskalacji nawet o 25% dzięki wcześniejszemu porzucaniu nierokujących zapytań
- Wzrost NPS dzięki krótszemu czasowi oczekiwania i mniejszej frustracji z chaotycznych odpowiedzi chatbota
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: The Shadow Price of Reasoning: Economic Perspective on Optimal Budget Allocation for LLMs
Autorzy: Xu Wan, Speed Zhu, Jianwei Cai, Guang Chen, XiMing Huang i in.
Inference-time scaling has emerged as a critical avenue for enhancing Large Language Models' performance, yet real-world deployment is constrained by strict computational budgets. In this work, we formulate inference budget allocation as a global constrained optimization problem governed by econo...
arXiv: arxiv.org/abs/2606.03092
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}