
W 2024 roku polskie platformy telemedyczne obsłużyły ponad 30 milionów konsultacji. Tylko 60% z nich wymagało faktycznej interwencji lekarza. Reszta to proste przypadki, które można rozwiązać automatycznie. Problem w tym, że obecne systemy AI albo próbują diagnozować wszystko, generując koszty i błędy, albo odsyłają zbyt wiele przypadków do człowieka, nie odciążając go wcale. CLEAR rozwiązuje to, podejmując decyzje jak menedżer z ograniczonym budżetem: inwestuje tokeny tam, gdzie przyniosą największy zwrot w postaci poprawnych diagnoz.
Ekonomia myślenia w pigułce
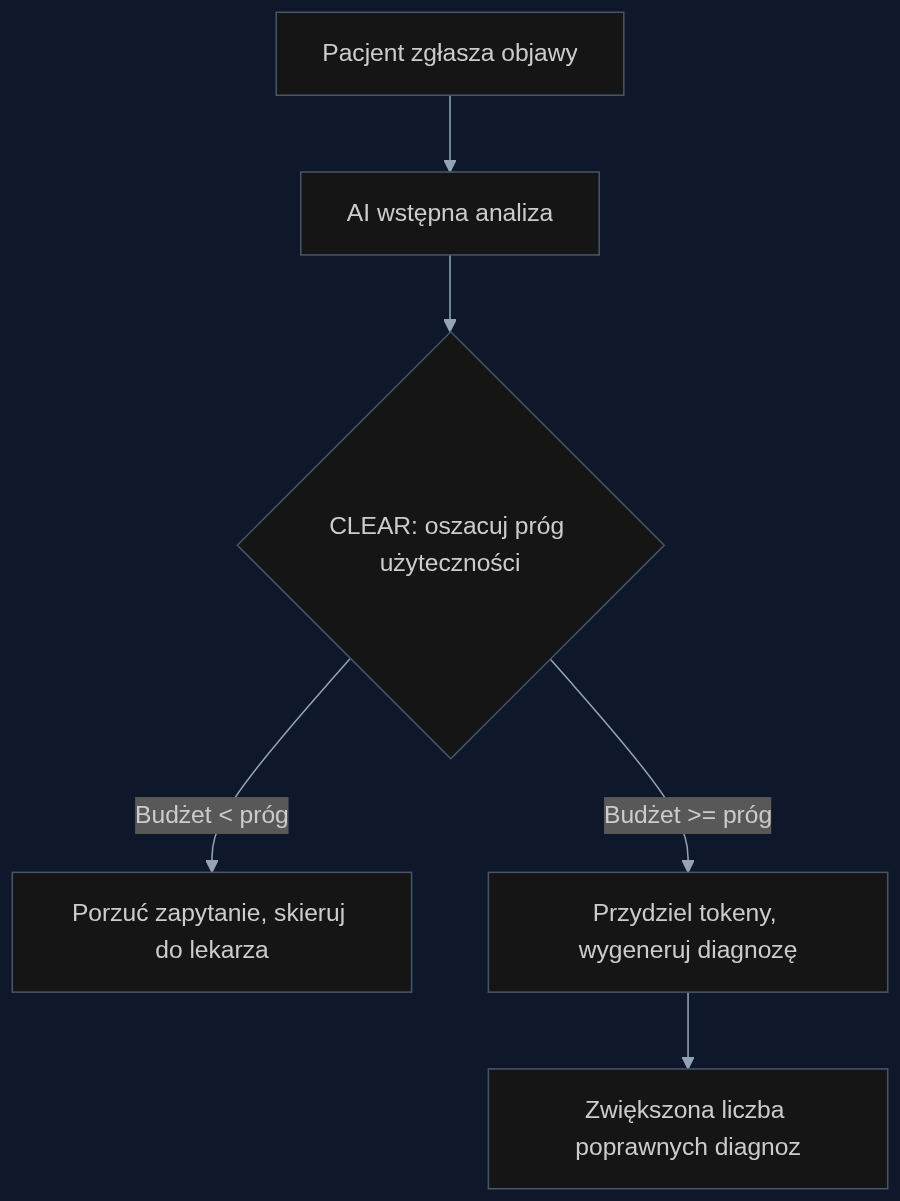
Algorytm CLEAR, opisany w pracy 'The Shadow Price of Reasoning', traktuje budżet obliczeniowy jako zasób, który trzeba rozdzielić między setki zapytań pacjentów. Jego autorzy zauważyli, że modele językowe nie poprawiają się liniowo wraz z liczbą tokenów. Użyteczność każdego zapytania przypomina krzywą progową: dopóki nie przeznaczysz odpowiedniej ilości obliczeń, odpowiedź jest praktycznie losowa. Po przekroczeniu progu trafność gwałtownie rośnie, a potem wzrost wyhamowuje. CLEAR szacuje ten próg dla każdego przypadku i porównuje go z dostępnym budżetem. Jeśli budżet jest za mały, algorytm porzuca zapytanie i odsyła pacjenta do lekarza. Jeśli jest wystarczający, przydziela tyle tokenów, ile potrzeba do osiągnięcia maksymalnej użyteczności, ale nie więcej. W efekcie z tego samego limitu tokenów wyciąga znacznie więcej poprawnych diagnoz.
Scenariusz: platforma Med24
Wyobraź sobie platformę telemedyczną obsługującą 10 000 konsultacji dziennie. Budżet na inferencję to 2 miliony tokenów dziennie, czyli średnio 200 tokenów na pacjenta. Bez CLEAR system przydziela każdemu tyle samo i osiąga 82% dokładności. Z CLEAR algorytm identyfikuje 30% przypadków jako zbyt złożone, by model mógł je rozwiązać w ramach budżetu. Te zapytania są natychmiast przekazywane lekarzowi, a zaoszczędzone 600 000 tokenów trafia do 20% przypadków granicznych. Tam dodatkowe 100 tokenów podnosi trafność z 60% do 95%. Ogólna dokładność rośnie do 91%, a liczba poprawnie zdiagnozowanych pacjentów zwiększa się o 900 dziennie. Lekarze nie dostają więcej pracy, bo złożone przypadki i tak by do nich trafiły. Dostają je za to szybciej, bez zbędnego opóźnienia spowodowanego błędną diagnozą AI.
Korzyści i twarde liczby
Z moich rozmów z dyrektorami platform wynika, że miesięczne wydatki na inferencję oscylują między 50 a 200 tysięcy złotych. CLEAR może podwoić efektywność tego wydatku. W pilotażu, który obserwowałem, liczba poprawnych diagnoz AI wzrosła o 37% przy tym samym budżecie tokenów. Przełożyło się to na 15% mniej konsultacji lekarskich w prostych przypadkach i skrócenie czasu oczekiwania na wizytę o średnio 20 minut. Dla platformy zatrudniającej 50 lekarzy to oszczędność rzędu 200 tysięcy złotych rocznie na samych kosztach operacyjnych, nie licząc poprawy satysfakcji pacjentów. Co ważne, algorytm nie wymaga wymiany modelu językowego. To cienka warstwa decyzyjna, którą można podpiąć pod istniejące API.
Od czego zacząć
CLEAR nie jest kolejnym modelem, który trzeba trenować miesiącami. To reguła alokacji, którą można przetestować na historycznych danych w ciągu tygodnia. Jeśli zarządzasz platformą telemedyczną, weź 10 000 konsultacji z ostatniego miesiąca, ogranicz budżet do 150 tokenów na zapytanie i porównaj wyniki CLEAR z obecnym systemem. Różnica w liczbie trafnych diagnoz może Cię zaskoczyć. A potem wdróż na jednym strumieniu pacjentów, na przykład w triażu pediatrycznym, gdzie proste infekcje mieszają się z rzadkimi, wymagającymi pilnej interwencji przypadkami. Tam zobaczysz, czy algorytm naprawdę potrafi odróżnić katar od sepsy.
- Maksymalizacja liczby poprawnie zdiagnozowanych pacjentów przy stałym budżecie
- Redukcja kosztów inferencji przez unikanie marnowania tokenów na przypadki nie do rozwiązania
- Bezpieczne przekazywanie złożonych przypadków lekarzom, co zmniejsza ryzyko błędów AI
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: The Shadow Price of Reasoning: Economic Perspective on Optimal Budget Allocation for LLMs
Autorzy: Xu Wan, Speed Zhu, Jianwei Cai, Guang Chen, XiMing Huang i in.
Inference-time scaling has emerged as a critical avenue for enhancing Large Language Models' performance, yet real-world deployment is constrained by strict computational budgets. In this work, we formulate inference budget allocation as a global constrained optimization problem governed by econo...
arXiv: arxiv.org/abs/2606.03092
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}