
Wyobraź sobie, że prowadzisz zespół, który dostaje setki zadań na raz. Każde zadanie ma inny poziom trudności, a ty masz ograniczoną ilość czasu i energii całego zespołu. Wysyłasz wszystkich na każde zadanie równo, czy może szybko oceniasz, które zadania są warte zachodu, a które lepiej od razu odpuścić? Badacze z zespołu Xu Wana postawili na to drugie. Zaproponowali algorytm CLEAR, który traktuje budżet obliczeniowy dużych modeli językowych jak ekonomista zarządzający rzadkimi zasobami i osiąga nawet trzykrotnie lepszą celność w warunkach niedoboru.
Problem z równym traktowaniem wszystkich pytań
Duże modele językowe coraz częściej rozwiązują zadania wymagające rozumowania krok po kroku. Im więcej tokenów model może wygenerować, tym dłużej 'myśli' i tym większa szansa na poprawną odpowiedź. Tyle że w praktyce nikt nie ma nieskończonego budżetu. Serwerownie mają limity, użytkownicy oczekują odpowiedzi w rozsądnym czasie, a każdy token kosztuje.
Standardowe podejście jest proste: każdemu zapytaniu dajemy tyle samo zasobów. Działa to średnio, bo jedno pytanie może wymagać 200 tokenów żeby osiągnąć próg zrozumienia, a inne potrzebuje 2000. Dając każdemu po równo, niedoinwestowujesz trudne pytania i przeinwestowujesz łatwe. Efekt? Całkowita celność systemu spada, choć wydajesz tyle samo pieniędzy.
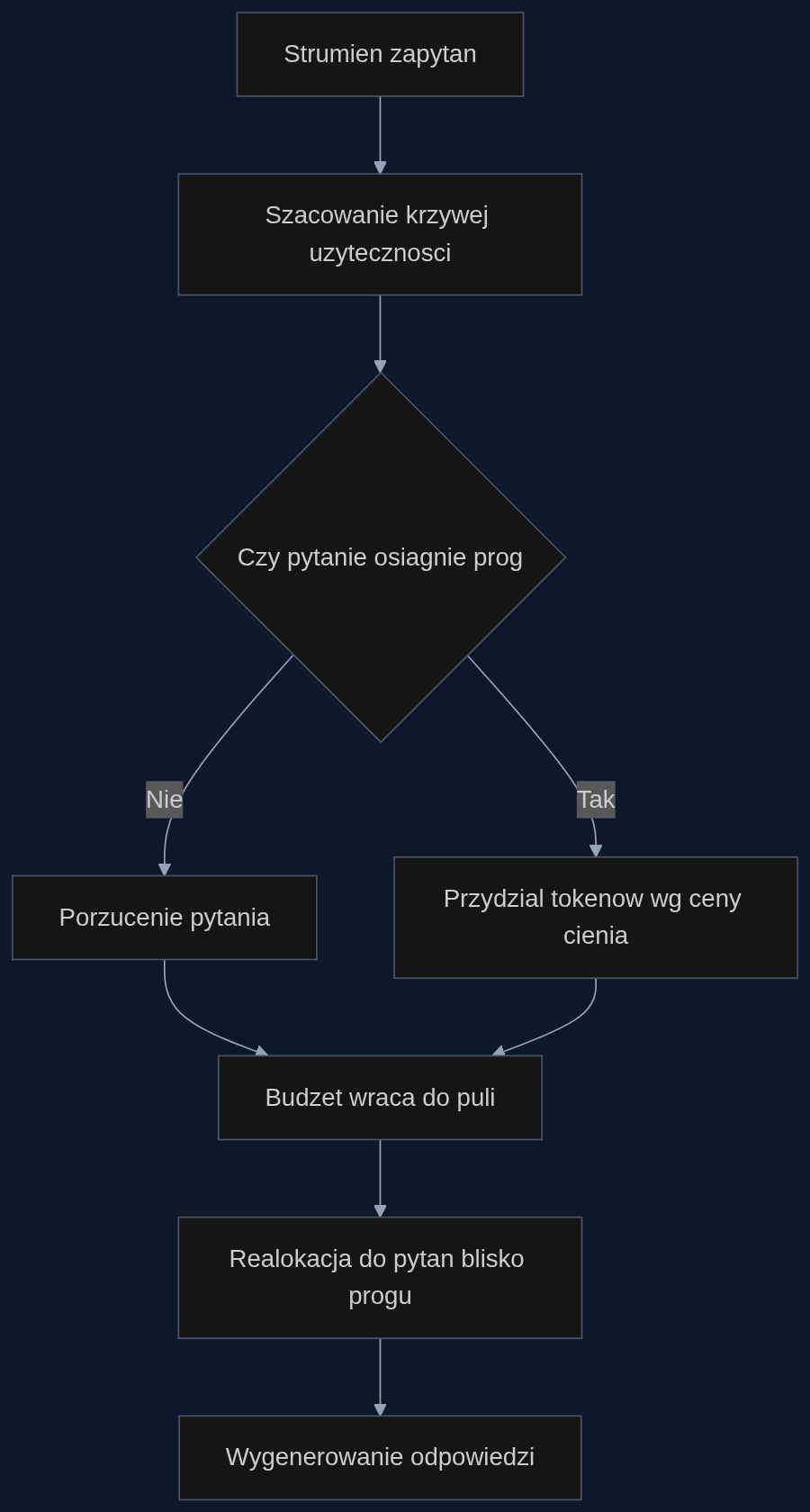
Autorzy badania nazywają to problemem alokacji pod presją budżetu. Zamiast rozdawać tokeny po równo, proponują podejście rodem z podręcznika mikroekonomii: każda wydana jednostka zasobu powinna przynosić taki sam przyrost użyteczności, niezależnie od tego, na które pytanie idzie.
Cena cienia i moment olśnienia
Kluczowym pomysłem jest tak zwana cena cienia (shadow price). To wartość, która mówi, o ile wzrośnie całkowita użyteczność systemu, jeśli dostaniesz jeden dodatkowy token do puli. W optimum, stosunek przyrostu jakości do przyrostu kosztu dla każdego pytania musi być równy tej cenie. Jeśli dla pytania A ten stosunek jest wyższy niż dla pytania B, opłaca się zabrać tokeny z B i dać je A. Proces trwa, aż wszystkie stosunki się wyrównają.
Żeby to zadziałało, trzeba wiedzieć, jak wygląda krzywa użyteczności pojedynczego pytania. Tutaj badacze wprowadzają funkcję 'przesuniętego przypływu' (shifted-surge). Wyobraź sobie, że do pewnego progu tokenów model praktycznie nie rozumie pytania i daje losowe odpowiedzi. Potem następuje gwałtowny skok jakości, jakby model nagle 'załapał', o co chodzi. Po tym skoku dalsze dokładanie tokenów już niewiele poprawia, a czasem nawet szkodzi, bo model zaczyna się zapętlać.
To zachowanie przypomina mi krzywą uczenia się w psychologii poznawczej: długo nic, potem nagły wgląd, potem plateau. Różnica jest taka, że u człowieka ten proces trwa minuty albo godziny, a u LLM-a realizuje się w setkach milisekund i setkach tokenów.
Skalowanie w czasie wnioskowania stało się kluczowym kierunkiem poprawy wydajności dużych modeli językowych, jednak wdrożenie w realnym świecie jest ograniczone przez ścisłe budżety obliczeniowe.
Xu Wan i współautorzy
Abstrakt badania
![]()
CLEAR: algorytm, który porzuca beznadziejne sprawy
Mając krzywą użyteczności i cenę cienia, można zbudować algorytm alokacji. CLEAR (Constrained Latent-utility Equilibrium Allocation for Reasoning) działa w dwóch krokach. Najpierw identyfikuje pytania 'niewypłacalne', czyli takie, które przy dostępnym budżecie nie mają szansy osiągnąć progu olśnienia. Te pytania są porzucane od razu, bez marnowania na nie ani jednego tokena.
Uwolnione zasoby trafiają do pytań, które są blisko swojego progu. To racjonalne porzucenie (rational abandonment) przypomina decyzję inwestora, który wycofuje się ze skazanej na porażkę inwestycji, żeby dołożyć do tych, które mają realną szansę. W warunkach niedoboru zasobów CLEAR osiąga nawet trzykrotnie wyższą globalną dokładność niż równomierny przydział tokenów.
Szczerze, jest w tym coś praktycznego i brutalnego zarazem. Algorytm nie udaje, że każde pytanie zasługuje na równe traktowanie. Patrzy na budżet, szacuje szanse i podejmuje decyzje, które maksymalizują całkowity wynik. To podejście bliższe zarządzaniu portfelem niż tradycyjnemu przetwarzaniu języka.
Front Pareto i co z tego wynika dla biznesu
Wyniki CLEAR-a najlepiej widać na wykresie frontu Pareto: im więcej tokenów wydajesz, tym lepsza średnia dokładność, ale krzywa dla CLEAR-a leży wyraźnie wyżej niż dla alokacji równomiernej. Przy tym samym koszcie dostajesz lepszą jakość. Albo odwrotnie: tę samą jakość osiągasz mniejszym kosztem.
W praktyce oznacza to, że systemy oparte na LLM-ach mogłyby dynamicznie decydować, które zapytania użytkowników zasługują na głębokie rozumowanie, a które lepiej obsłużyć szybką, tańszą odpowiedzią. Wyobrażam sobie helpdesk, gdzie proste pytanie o godziny otwarcia nie zjada budżetu, który mógłby pójść na analizę skomplikowanego problemu technicznego innego klienta.
Nie jest to rozwiązanie na każdą okazję. CLEAR wymaga oszacowania krzywych użyteczności dla różnych typów zadań, co samo w sobie kosztuje. Ale w scenariuszach, gdzie ruch jest duży, budżet napięty, a pytania bardzo zróżnicowane, ta ekonomiczna perspektywa może realnie obniżyć rachunki za API przy jednoczesnej poprawie doświadczenia użytkownika.
- Alokacja budżetu wnioskowania jako problem optymalizacyjny: każdy token powinien pracować tam, gdzie daje największy przyrost jakości odpowiedzi.
- Funkcja przesuniętego przypływu modeluje moment olśnienia modelu: poniżej progu tokenów odpowiedzi są losowe, powyżej następuje gwałtowny skok dokładności.
- Cena cienia wyznacza równowagę: stosunek przyrostu użyteczności do kosztu tokena musi być identyczny dla wszystkich obsługiwanych pytań.
- Racjonalne porzucenie: CLEAR rezygnuje z pytań bez szans na sukces i przekazuje ich budżet pytaniom blisko progu olśnienia.
- W warunkach ograniczonych zasobów CLEAR daje do trzech razy wyższą dokładność globalną niż równomierny przydział tokenów.
Praktyczne zastosowania
Aby lepiej zrozumieć opisywaną innowację, przygotowaliśmy cztery przykłady praktycznego zastosowania tej technologii w różnych branżach:




Podsumowanie
CLEAR to praktyczne narzedzie do zarzadzania kosztami duzych modeli jezykowych w warunkach ograniczonego budzetu. W systemach obslugi klienta moze automatycznie kierowac trudne sprawy do glebokiego rozumowania, a proste zapytania obslugiwac minimalnym kosztem. W analizie dokumentow prawnych lub medycznych algorytm pomoze skupic zasoby na tych fragmentach, ktore rzeczywiscie wymagaja zlozonego wnioskowania, zamiast rowno przeznaczac tokeny na caly tekst. Dla dostawcow API LLM-owych to szansa na oferowanie tanszych planow z dynamiczna alokacja, gdzie klient placi tylko za realnie potrzebne zasoby obliczeniowe.
Metryka artykułu źródłowego
Tytuł oryginalny: The Shadow Price of Reasoning: Economic Perspective on Optimal Budget Allocation for LLMs
Autorzy: Xu Wan, Speed Zhu, Jianwei Cai, Guang Chen, XiMing Huang, Wiggin Zhou, Mingyang Sun
Data publikacji: 3 czerwca 2026
arXiv: arxiv.org/abs/2606.03092
Napisanie tego artykułu zostało wspomagane przez sztuczną inteligencję. Treść opiera się na oryginalnym artykule naukowym, a jej dokładność została zweryfikowana automatycznie.
{kind=link}