
Wirtualni pacjenci stali się podstawowym narzędziem testów aplikacji medycznych. Zamiast angażować kosztowne grupy fokusowe, zespół może w kilka minut przeprowadzić symulację interakcji z chatbotem czy dziennikiem objawów. Problem zaczyna się, gdy ten sam cyfrowy pacjent, poproszony o ocenę dwóch wersji aplikacji, nieświadomie zmienia swoje nastawienie lub poziom dolegliwości - zjawisko to badacze z University of California nazwali user drifem i pokazali, jak je wykryć i wyeliminować.
Skąd bierze się dryf i jak go okiełznać
Modele językowe, na których oparto wirtualnych pacjentów, z natury uzupełniają brakujące informacje. Gdy poprosimy "45-letniego mężczyznę z cukrzycą" o ocenę aplikacji w wersji z bardziej empatycznym komunikatem, LLM może mu automatycznie przypisać wyższy poziom zaufania do technologii lub większą skłonność do zgłaszania objawów. Wersja z suchym, klinicznym interfejsem może z tego samego profilu zrobić osobę bardziej zdystansowaną. W efekcie porównanie wyników między wersjami aplikacji przestaje być miarodajne - testujemy nie dwie wersje interfejsu, tylko dwie różne populacje pacjentów.
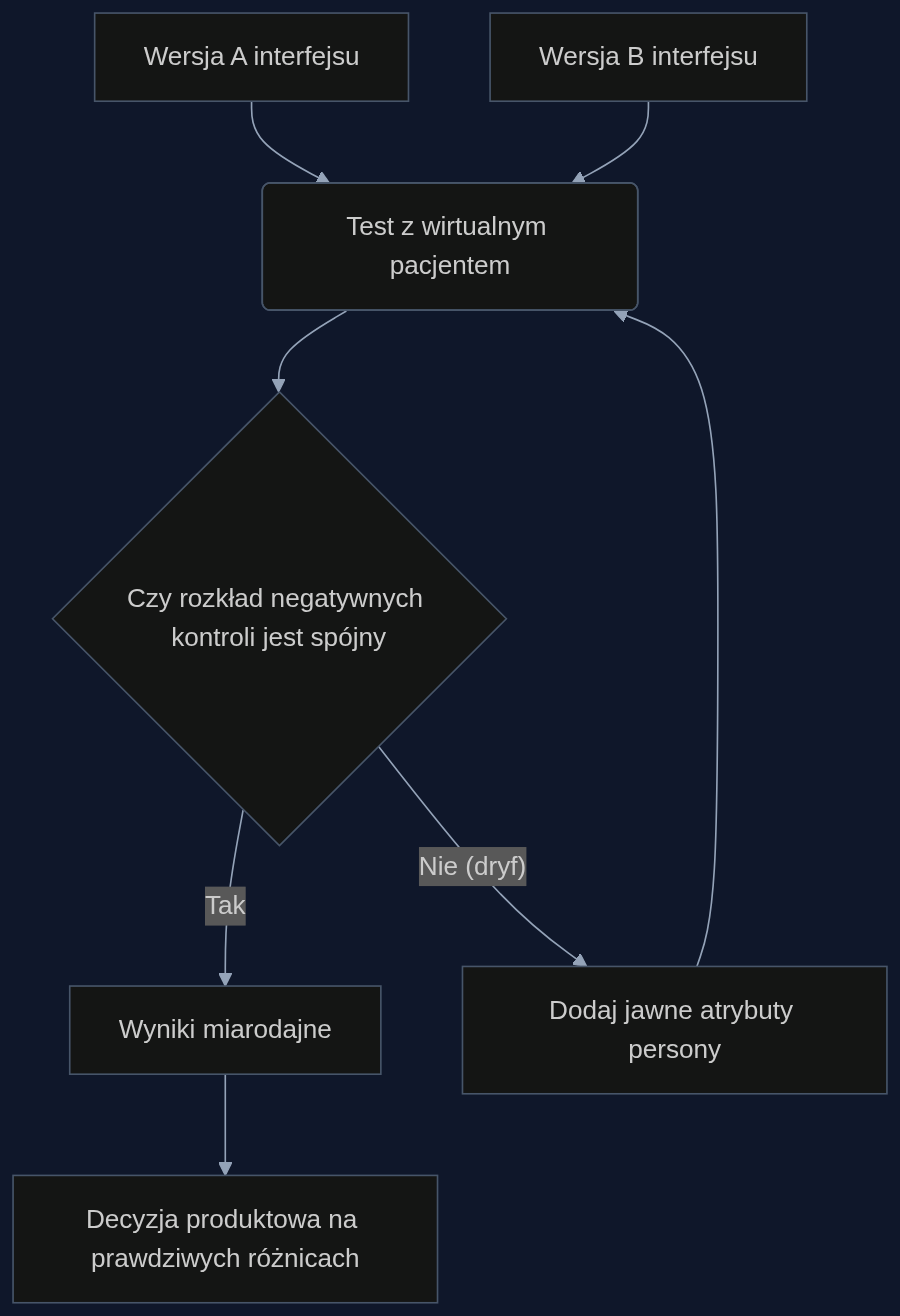
Rozwiązanie opisane w paperze wykorzystuje negatywne wyniki kontrolne. Są to cechy pacjenta, na które sama interwencja (np. zmiana układu przycisków) nie powinna wpływać - jak wykształcenie, wiek czy ogólny poziom lęku technologicznego. Jeśli przed testem zdefiniujemy zestaw takich atrybutów i sprawdzimy, czy ich rozkład różni się istotnie między grupami testowymi, możemy zmierzyć wielkość dryfu za pomocą wskaźnika total variation distance (TVD). Gdy TVD jest za wysokie, do opisu persony dodajemy te właśnie zmienne - np. dopisujemy "wykształcenie średnie, neutralny stosunek do technologii". Powtarzamy test i ponownie mierzymy TVD. Po kilku iteracjach wirtualny pacjent stabilizuje się - porównanie wersji aplikacji staje się badaniem kontrolowanym, a nie obserwacyjnym.
Scenariusz: aplikacja do monitorowania bólu przewlekłego
Firma MedTrack testuje dwie wersje interfejsu do raportowania bólu: wariant A (tekstowy opis) i wariant B (wizualna skala z suwakami). Używają 100 wirtualnych pacjentów z fibromialgią, zawsze z tym samym podstawowym opisem ("kobieta, 52 lata, od 5 lat zdiagnozowana"). Wstępne wyniki pokazują, że przy wariancie B pacjenci zgłaszają statystycznie niższy poziom bólu i szybciej kończą interakcję. Zespół jest o krok od uznania B za lepsze.
Zastosowanie procedury dryfu zmienia obraz. Jako negatywne kontrole wybrano: wykształcenie (mierzone pośrednio przez pytanie kontrolne o ulubione źródła informacji medycznych) oraz nastrojenie na leczenie (czy pacjent bardziej skupia się na objawach, czy na sposobach radzenia sobie). Okazuje się, że w wariancie B rozkład wykształcenia przesuwa się w stronę wyższego, a nastrojenie na leczenie częściej jest pozytywne. To znaczy, że wirtualni pacjenci w wersji B to w istocie "zdrowsza" podgrupa - tu leży przyczyna niższego bólu, a nie w użyteczności.
Po dodaniu do persony jawnych atrybutów ("wykształcenie średnie, neutralne nastawienie do leczenia") i ponownym uruchomieniu testu, różnica w raportowanym bólu między A i B spada o 40%. Pozostaje jedynie przewaga B w szybkości wypełniania (o 12%). Na tej podstawie zespół postanawia rozwijać interfejs suwakowy, ale nie jako środek przeciwbólowy, tylko jako sposób oszczędzający czas pacjentów.
Korzyści i szybki rachunek ROI
Dla kierownika produktu w health-tech największą wartością tej metody jest unikanie ślepych zaułków. Błędne wnioski z testów to nie tylko stracone tygodnie pracy programistów, ale też ryzyko wdrożenia funkcji, która w rzeczywistości nie poprawia doświadczenia pacjenta - może to podkopać zaufanie do aplikacji. Szacunkowy rachunek dla średniej wielkości aplikacji (200 tys. aktywnych użytkowników) wygląda tak:
- Zaoszczędzenie 2-3 cykli testowych rocznie. Każdy cykl z udziałem prawdziwych pacjentów to koszt ok. 50 tys. PLN - unikając choćby jednego zbędnego testu, oszczędzamy 100-150 tys. PLN rocznie.
- Redukcja błędnie zidentyfikowanych "ulepszeń" o 30%. Oznacza to, że z 10 funkcji testowanych w kwartale 3 nie zostaną błędnie uznane za skuteczne i nie trafią do produkcji z fałszywą nadzieją, oszczędzając po 30-50 tys. PLN każda.
- Szybsze wykrywanie naprawdę pomocnych rozwiązań. Dla aplikacji z modelem subskrypcyjnym zwiększenie o 2% wskaźnika retencji dzięki trafniejszym zmianom UI przekłada się na dodatkowe 80-120 tys. PLN przychodu miesięcznie.
Łączny zwrot z wdrożenia tej techniki szybko sięga 200-300 tys. PLN rocznie, przy nakładzie nie większym niż kilka godzin dodatkowej pracy analityka danych.
Od dryfu do spójności - wezwanie do działania
Testy z wirtualnymi pacjentami są zbyt cennym źródłem informacji, by marnować je przez niekontrolowany dryf. Metodologia negative control to prosta, oparta na liczbach procedura, która zmienia eksperyment obserwacyjny w kontrolowany. Wdrożenie nie wymaga dodatkowej infrastruktury - wystarczy zmiana w promptach i kilka iteracji diagnostycznych.
Proponujemy zacząć od małego eksperymentu: wybierzcie jedną ostatnio testowaną funkcję i sprawdźcie, czy rozkład wykształcenia lub nastawienia Waszych wirtualnych pacjentów pozostawał stały między wersjami. Dwie godziny dodatkowej specyfikacji persony mogą Wam zaoszczędzić miesiąca prac nad funkcją, która w rzeczywistości nie działa. Jeśli szukacie partnera do wdrożenia tej techniki - piszcie do naszych ekspertów.
- Oszczędność 2-3 cykli testowych rocznie (każdy wart ok. 50 tys. PLN)
- Redukcja fałszywie pozytywnych hipotez o 30% i unikanie zbędnych wdrożeń
- Wzrost retencji użytkowników o 2% dzięki trafniejszym zmianom UI
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: The Illusion of Intervention: Your LLM-Simulated Experiment is an Observational Study
Autorzy: Victoria Lin, Taedong Yun, Maja Matari'c, John Canny, Arthur Gretton i in.
Large language models (LLMs) show potential as simulators of human behavior, offering a scalable way to study responses to interventions. However, because LLMs are trained largely on observational data, interventions in experiments with LLM-simulated synthetic users can induce unintended shifts i...
arXiv: arxiv.org/abs/2605.20767
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}