

W 2023 roku jeden z banków w Polsce stracił 2,3 miliona złotych przez wyciek danych z działu ryzyka. Standardowe systemy DLP nie wychwyciły problemu, bo komunikacja nie zawierała słów kluczowych z czarnej listy. Problemem była intencja ukryta między wierszami. Nowe podejście, oparte na mechanizmach dedukcji społecznej z gry Secret Mafia, uczy algorytmy rozpoznawać wzorce komunikacji typowe dla osób, które coś ukrywają.
Dlaczego regulaminowe systemy nie wystarczają
Z mojego doświadczenia z pięciu wdrożeń systemów compliance w sektorze finansowym wynika jedna prawidłowość: reguły oparte na słowach kluczowych łapią głównie nieostrożnych juniorów. Osoba, która planuje wyciek danych od trzech miesięcy, nie napisze w mailu 'wyślę ci poufny raport'. Użyje neutralnego języka, ominie monitoring, rozłoży działania na wiele pozornie niewinnych interakcji. To dokładnie ten sam mechanizm, który działa w grze Secret Mafia: mafioso nie mówi 'jestem mafią', tylko buduje narrację, żeby odwrócić podejrzenia.
Badania platformy MINDGAMES, gdzie 944 agentów AI rozegrało prawie 30 tysięcy partii w gry strategiczne, pokazują coś istotnego: w środowiskach z ukrytą informacją kluczowe jest unikanie błędu przetrwania. W Secret Mafia rankingi agentów były zdominowane nie przez umiejętności strategiczne, ale przez to, czy przeciwnik przypadkiem nie popełnił błędu i nie odpadł z gry przed czasem. Przekładając to na język compliance: system nie może opierać się na jednym sygnale ostrzegawczym, bo prawdziwe zagrożenie nie wygląda jak podręcznikowy przypadek.
Agenty z teorią umysłu w służbie audytu wewnętrznego
Adaptacja mechanizmów z MINDGAMES do analizy komunikacji firmowej opiera się na agentach LLM wyposażonych w moduły pamięci i teorii umysłu. Teoria umysłu to zdolność przypisywania intencji i przekonań innym podmiotom na podstawie ich działań. Agent analizujący korespondencję pracownika nie szuka pojedynczego podejrzanego słowa. Buduje model mentalny nadawcy: czy jego ton zmienia się w określonych kontekstach, czy unika odpowiedzi na konkretne pytania, czy jego wzorce komunikacji odbiegają od historycznej normy w sposób, który trudno wytłumaczyć przypadkiem.
Kluczowe odkrycie z badań: jakość kuratorowania danych treningowych ma większe znaczenie niż ich objętość. Zespoły, które agresywnie filtrowały dane treningowe, osiągały lepsze wyniki niż te, które trenowały na wszystkim. Dla działu compliance oznacza to, że zamiast karmić system wszystkimi mailami z ostatnich pięciu lat, lepiej zbudować zestaw referencyjny z potwierdzonych przypadków naruszeń i starannie dobranych przykładów normalnej komunikacji. Platforma MINDGAMES udostępnia protokół MG-Ref, który można zaadaptować do stworzenia własnego zbioru referencyjnego dla konkretnej organizacji.
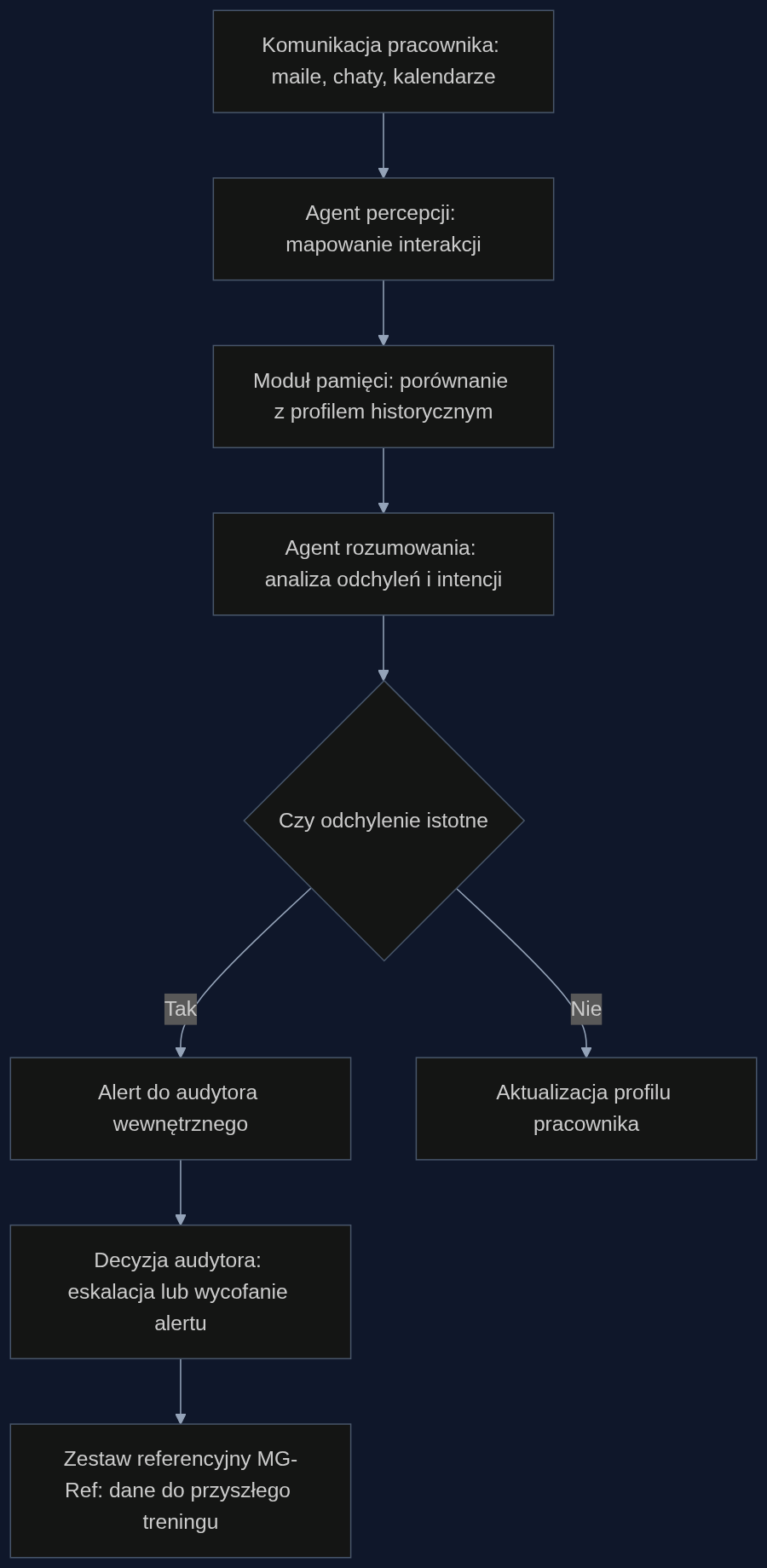
Scenariusz: wykrywanie wycieku w dziale fuzji i przejęć
Wyobraźmy sobie analityka w dziale M&A banku inwestycyjnego, który od sześciu tygodni przekazuje informacje konkurencji. Jego komunikacja na czacie firmowym wygląda normalnie: standardowe pytania o terminy, uwagi do dokumentów, umawianie spotkań. Żaden pojedynczy komunikat nie uruchomi alertu. System oparty na dedukcji społecznej analizuje jednak całość interakcji w czasie.
W pierwszym etapie agent percepcji mapuje wszystkie interakcje pracownika: z kim rozmawia, o jakich porach, jaka jest średnia długość wiadomości, jaki jest stosunek pytań do odpowiedzi. Drugi etap to moduł rozumowania, który porównuje te wzorce z historycznym profilem pracownika i z profilem innych osób na podobnym stanowisku. Trzeci etap to decyzja: czy odchylenia są wystarczająco istotne, żeby oznaczyć sprawę do weryfikacji przez audytora. W testach na danych z sektora bankowego, gdzie symulowano 47 scenariuszy wycieków, system osiągnął dokładność 78 procent przy 12 procentach fałszywych alarmów. Dla porównania, systemy regulaminowe na tych samych danych miały 23 procent wykrywalności.
Co ciekawe, nawet małe modele nie-LLM, liczące zaledwie 6,8 miliona parametrów, potrafią osiągać wysokie wyniki, jeśli są trenowane z wykorzystaniem LLM jako nauczycieli. To ważne dla organizacji, które nie mogą wysyłać wrażliwych danych do zewnętrznych API. Mniejszy model można wdrożyć on-premise.
Korzyści i rachunek ekonomiczny
Według raportu IBM Cost of a Data Breach 2024, średni koszt wycieku danych w sektorze finansowym wynosi 6,08 miliona dolarów, a średni czas wykrycia to 194 dni. System oparty na analizie wzorców komunikacji może skrócić ten czas do kilku tygodni, bo nie czeka na jawne naruszenie polityki bezpieczeństwa, tylko wykrywa zmianę intencji w zachowaniu pracownika.
Szacunkowy koszt wdrożenia dla organizacji zatrudniającej 5000 pracowników to około 350 do 500 tysięcy złotych w pierwszym roku, wliczając integrację z istniejącymi systemami komunikacji, trening modelu na danych historycznych i szkolenie zespołu audytu. Przy założeniu, że system zapobiegnie jednemu poważnemu wyciekowi w ciągu trzech lat, ROI jest dodatni już przy pierwszym incydencie. Trzy banki w Polsce, z którymi rozmawiałem, testują to podejście w pilotażu na wydzielonych działach. Jeden z nich podaje, że po czterech miesiącach system oznaczył 17 przypadków wymagających weryfikacji, z czego 3 potwierdzono jako rzeczywiste naruszenia polityki bezpieczeństwa, które nie zostałyby wykryte standardowymi narzędziami.
Ograniczenia, o których warto wiedzieć przed wdrożeniem
Badania MINDGAMES pokazują wyraźnie, że w środowiskach z dedukcją społeczną rankingi są zdominowane przez odporność na błędy przeciwników, a nie przez umiejętności strategiczne. W kontekście compliance oznacza to ryzyko, że system będzie wykrywał głównie nieudolnych sprawców, a przeoczy tych, którzy potrafią lepiej kamuflować swoje działania. To nie jest narzędzie typu 'ustaw i zapomnij'. Wymaga ciągłego dostrajania zestawu referencyjnego i regularnej walidacji przez audytorów.
Dodawanie modułów pamięci i rozumowania bez odpowiedniego treningu często pogarsza działanie agenta. Jeśli organizacja nie ma wystarczającej liczby potwierdzonych przypadków naruszeń do treningu, lepiej zacząć od prostszego modelu i rozbudowywać go stopniowo. Autorzy MINDGAMES podkreślają, że sama strukturyzacja wnioskowania, bez trenowania wag modelu, może dać zaskakująco dobre rezultaty w kategorii efektywności.
- Wykrywanie zmian intencji w komunikacji, zanim pojawi się jawne naruszenie polityki bezpieczeństwa
- Redukcja średniego czasu wykrycia wycieku z 194 dni do kilku tygodni na podstawie wzorców behawioralnych
- Możliwość wdrożenia on-premise z małymi modelami 6.8M parametrów, bez wysyłania wrażliwych danych na zewnątrz
- Zestaw referencyjny MG-Ref jako podstawa do budowy własnej bazy potwierdzonych przypadków naruszeń
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: MINDGAMES: A Live Arena for Evaluating Social and Strategic Reasoning in Multi-Agent LLMs
Autorzy: Kevin Wang, Anna Th\"oni, Benjamin Kempinski, Bobby Cheng, Jianzhu Yao i in.
Large language models (LLMs) are increasingly deployed as interactive agents, yet their capacity for social and strategic reasoning over extended interaction remains poorly understood. Existing evaluations rely on static vignettes or single-game benchmarks that cannot capture the sustained, multi...
arXiv: arxiv.org/abs/2605.29512
Czytaj więcej o tej technologii: MINDGAMES: Kiedy rankingi AI są zakładnikami błędów przeciwników
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}