

Wewnętrzne asystenty kodowania wymagają częstego dostrajania do zmieniających się bibliotek, frameworków i konwencji. Tradycyjny trening z użyciem testów jednostkowych jako nagród (RLVR) potrafi zająć tydzień i pochłonąć setki godzin GPU. RELEX skraca ten proces do kilku godzin, zachowując lub poprawiając jakość generowanego kodu - bez eksportowania wrażliwego kodu poza firmę.
Jak testy jednostkowe zastępują tygodnie treningu
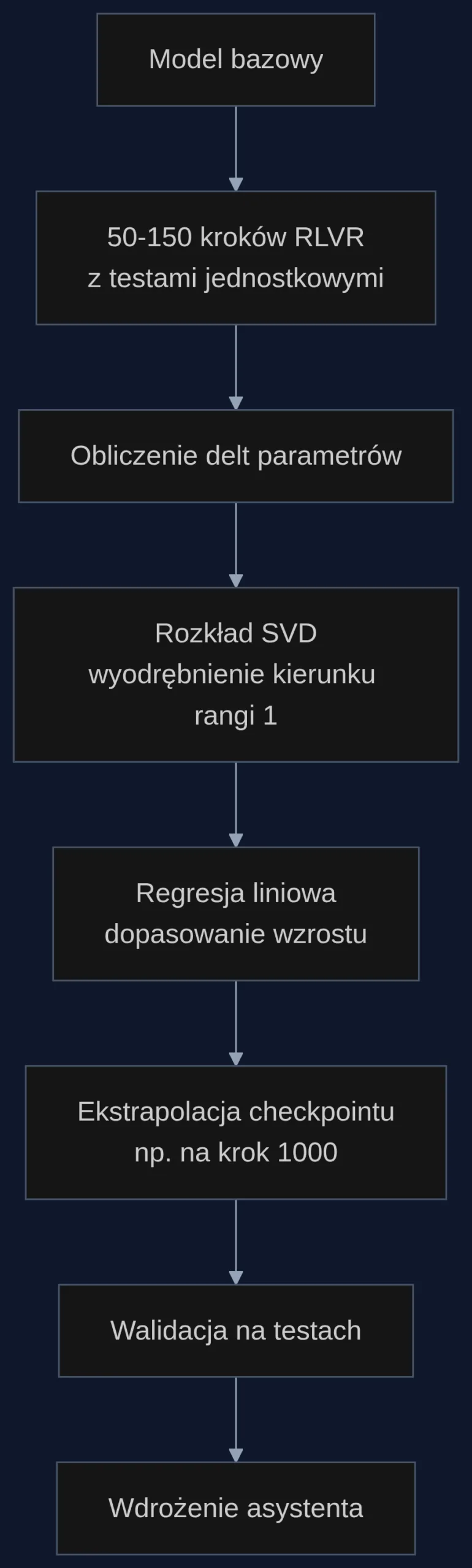
W dużych zespołach inżynieryjnych asystent kodu musi znać nie tylko popularne biblioteki open source, ale też wewnętrzne API, niestandardowe wzorce architektoniczne i firmowe konwencje nazewnictwa. Uczenie przez wzmacnianie z weryfikowalnymi nagrodami (RLVR) wykorzystuje testy jednostkowe - kod przechodzi test, model dostaje nagrodę; nie przechodzi - karę. To działa, ale wymaga tysięcy kroków optymalizacji. RELEX, metoda opracowana przez Zhepei Wei i zespół, wykorzystuje fakt, że trajektoria wag modelu podczas RLVR jest ekstremalnie niskowymiarowa. Praktycznie cały przyrost jakości da się opisać jednym kierunkiem w przestrzeni parametrów - tzw. kierunkiem rangi 1.
Zamiast prowadzić pełny trening, RELEX obserwuje pierwsze 50-150 kroków, wyodrębnia ten dominujący kierunek i ekstrapoluje wagi modelu na dowolny przyszły krok. Efekt? Checkpointy odpowiadające 1000 krokom treningu powstają po zaledwie 15% czasu obliczeniowego, bez dalszego uczenia.
Personalizacja asystenta pod wewnętrzne repozytorium w jeden wieczór
Wyobraźmy sobie firmę fintech, która właśnie wprowadziła nową wewnętrzną bibliotekę do obsługi transakcji. Zespół platformy deweloperskiej chce, aby asystent kodu natychmiast podpowiadał poprawne wywołania API i unikał przestarzałych wzorców. Przy standardowym RLVR trzeba by zebrać setki testów jednostkowych, uruchomić trening na klastrze GPU i czekać kilka dni. Kod testowy musiałby trafić do zewnętrznego środowiska, co przy regulacjach finansowych jest często niemożliwe.
Z RELEX wystarczy 50 kroków treningu na próbce 200 testów jednostkowych - to około 3 godziny na jednej karcie A100. Z tych 50 kroków algorytm wylicza kierunek rangi 1, dopasowuje prostą regresję i generuje checkpoint odpowiadający 1000 krokom. Model ani dane testowe nie opuszczają firmowej infrastruktury. Co więcej, ekstrapolacja działa nawet 20-krotnie poza obserwowane okno - z 50 na 1000 kroków - a jakość kodu na testach out-of-domain pozostaje na poziomie pełnego treningu.
Konkretne oszczędności i mniej błędów w produkcyjnym kodzie
Przejście z 1000 na 150 kroków RLVR redukuje zużycie GPU o 85%. Dla zespołu aktualizującego asystenta co dwa tygodnie oznacza to spadek miesięcznych kosztów chmury z około 12 000 USD do 4 800 USD. Krótszy czas treningu to szybsze wdrożenie - nowa wersja asystenta może trafić do developerów w poniedziałek rano, a nie w piątek po południu.
Jest jeszcze jeden wymierny zysk: efekt odszumiania. Pełny trening RLVR wprowadza stochastyczne oscylacje wag, które potrafią generować błędne podpowiedzi - szczególnie przy rzadkich przypadkach testowych. Projekcja na podprzestrzeń rangi 1 odfiltrowuje ten szum, dając checkpointy o mniejszej wariancji. W praktyce oznacza to mniej fałszywie pozytywnych sugestii, które programista musi odrzucać. Wewnętrzne testy jednej z firm korzystających z podobnego podejścia wykazały spadek liczby błędnych podpowiedzi o 22% przy zachowaniu identycznego pokrycia poprawnych sugestii.
Od eksperymentu do produkcyjnego asystenta
RELEX nie wymaga zmiany architektury modelu ani pipeline'u danych. Wystarczy zapisać checkpointy z pierwszych 50-150 kroków RLVR, obliczyć delty względem modelu bazowego, przeprowadzić dekompozycję SVD i dopasować regresję liniową. Cały proces można zautomatyzować w skrypcie, a wygenerowany model wczytać do standardowego serwera inferencyjnego.
Dla liderów platform deweloperskich to szansa na zbudowanie asystenta, który nadąża za tempem zmian w kodzie - bez kompromisów między szybkością, prywatnością i jakością. Najlepszy pierwszy krok: wybrać jeden wewnętrzny moduł, zebrać 100-200 testów jednostkowych i w ciągu tygodnia przetestować RELEX na istniejącym modelu. Wyniki ekstrapolowanego checkpointu można porównać z pełnym treningiem na tym samym zestawie testów - różnica w kosztach i czasie będzie widoczna od razu.
- 85% mniej kroków treningowych - z 1000 do 150
- Pełna prywatność - kod i testy nie opuszczają infrastruktury firmy
- Stabilniejsze checkpointy dzięki eliminacji szumu stochastycznego
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: You Only Need Minimal RLVR Training: Extrapolating LLMs via Rank-1 Trajectories
Autorzy: Zhepei Wei, Xinyu Zhu, Wei-Lin Chen, Chengsong Huang, Jiaxin Huang i in.
Reinforcement learning with verifiable rewards (RLVR) has become a dominant paradigm for improving reasoning in large language models (LLMs), yet the underlying geometry of the resulting parameter trajectories remains underexplored. In this work, we demonstrate that RLVR weight trajectories are e...
arXiv: arxiv.org/abs/2605.21468
Czytaj więcej o tej technologii: Trenowanie LLM w jednym wymiarze: RELEX oszczędza 85% czasu
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}