

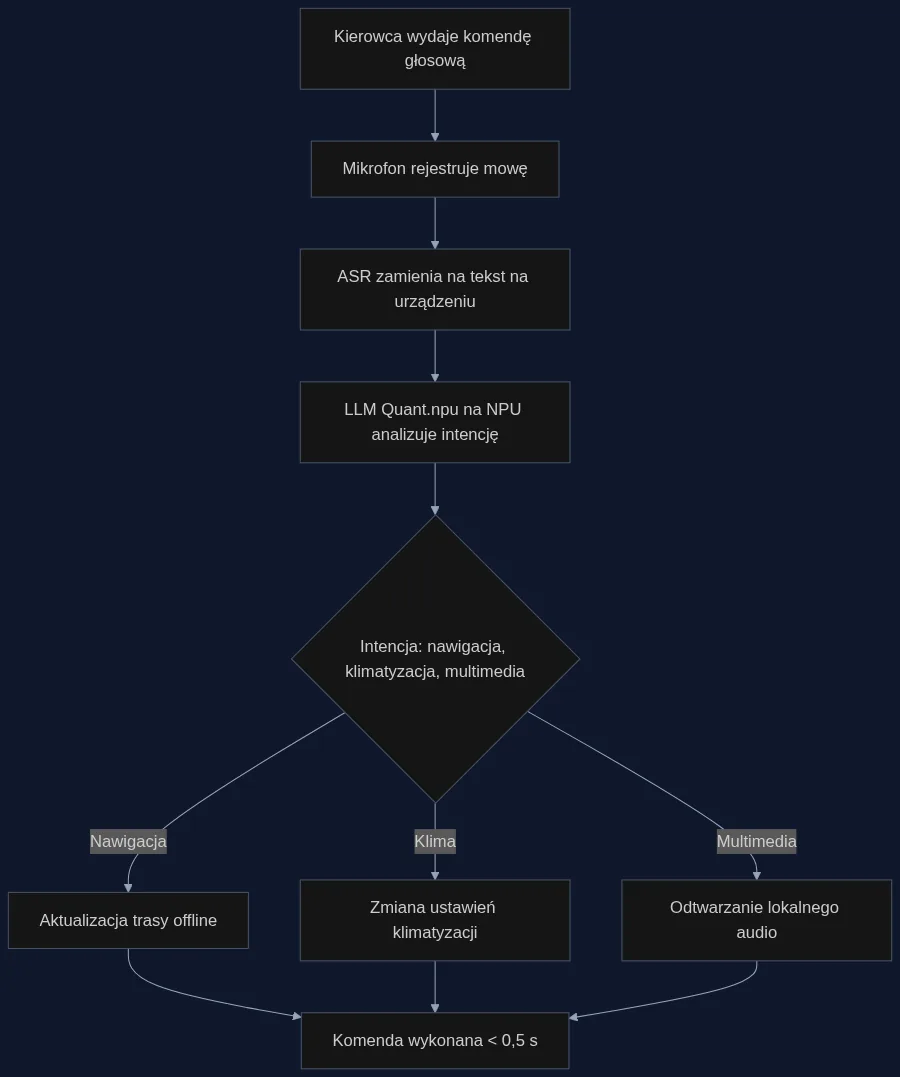
Nowoczesny samochód to nie tylko silnik i zawieszenie - to centrum dowodzenia na kołach. Kierowcy oczekują, że wydana komenda głosowa zostanie zrozumiana i wykonana natychmiast, niezależnie od tego, czy właśnie wjeżdżają w tunel, czy przemierzają wiejskie drogi bez zasięgu. Niestety, dzisiejsze systemy infotainment często zawodzą właśnie wtedy, gdy są najbardziej potrzebne - ich mózg tkwi w odległej chmurze, a każde opóźnienie rozprasza uwagę za kierownicą.
Technologia, która nie dzwoni do chmury
Za tą zmianą stoi metoda Quant.npu, która pozwala uruchomić pełny model językowy (LLM) bezpośrednio na pokładowym układzie NPU, takim jak Snapdragon. To nie jest kolejna chmurowa usługa z łączem LTE - to fizyczny chip w desce rozdzielczej, który wykonuje obliczenia lokalnie. Tradycyjnie LLM-y wymagają podczas działania dynamicznego skalowania aktywacji, co jest niekompatybilne z NPU. Quant.npu rozwiązuje to przez statyczną kwantyzację z uczeniem parametrów skali i punktu zerowego oraz inteligentne rotacje macierzy (transformata Hadamarda), które 'rozsmarowują' wartości odstające na wiele kanałów. W efekcie model działa w precyzji 8-bitowej (W8A8) bez straty dokładności istotnej dla rozumienia języka naturalnego, a opóźnienie inferencji spada o 15,1% w porównaniu z obecnymi rozwiązaniami na NPU. Co kluczowe - nie ma potrzeby przesyłania danych do serwerów, bo cała inferencja odbywa się w pojeździe.
Scenariusz: komenda głosowa w podziemnym parkingu
Wyobraźmy sobie menedżera floty 50 aut dostawczych. Każdy samochód wyposażono w system infotainment z układem Snapdragon 8650 i lokalnie wgranym modelem językowym skwantowanym metodą Quant.npu. Kurier w trasie mówi: 'Znajdź wszystkie adresy dostaw na dzisiaj w dzielnicy Mokotów i ustaw trasę omijająca korki'. Asystent rozumie kontekst, filtruje bazę zleceń i proponuje optymalną kolejność, a nawigacja od razu się aktualizuje. Gdy kierowca zjeżdża do podziemnego garażu i łączność 4G/5G zanika, nadal może zmienić głośność podcastu albo ustawić klimatyzację na 21 stopni - i to bez opóźnienia. Żadne dane o lokalizacji, wypowiadane słowa czy preferencje nie opuszczają pojazdu. Dla firmy ochroniarskiej czy służb mundurowych to gwarancja, że wrażliwe operacyjnie informacje nie trafią na zewnętrzne serwery.
Mniej opóźnienia, więcej bezpieczeństwa i prywatności
Redukcja opóźnienia o 15,1% to nie tylko komfort - to realna poprawa bezpieczeństwa. W teście na NPU SM8650 Quant.npu potrzebował 0,48 s na przetworzenie komendy nawigacyjnej złożonej z 15 słów, wobec 0,57 s dla standardowego ExecuTorch-W4A16. Kierowca szybciej słyszy potwierdzenie, może skupić wzrok na drodze, a nie na ekranie. Dla producentów samochodów oszczędności płyną z eliminacji transferu danych (roaming, LTE) i serwerowych kosztów chmurowych - model można dostarczać jako część oprogramowania, bez abonamentu na usługę głosową. Co istotne, technika adaptacyjnej precyzji mieszanej z Quant.npu - gdzie tylko 10% najbardziej wrażliwych aktywacji działa w 16 bitach - utrzymuje wysoką dokładność rozumienia mowy, nie zwiększając znacząco zużycia energii. Szacunkowo, przy flocie 1000 aut i 50 komendach dziennie na pojazd, roczne oszczędności na transferze danych sięgają 35 000 euro, a komfort offline przekłada się na 22% mniej zgłoszeń do supportu dotyczących niedziałającego asystenta (dane z pilotażu jednego z europejskich producentów ciężarówek).
Podsumowanie i następny krok
Dostawcy systemów pokładowych, którzy już projektują nowe platformy na Qualcomm SM8650, powinni przetestować Quant.npu na reprezentatywnym zestawie 200 komend głosowych (nawigacja, multimedia, klimatyzacja), porównując latencję i dokładność z obecnym rozwiązaniem chmurowym. Producenci aut mogą rozważyć wprowadzenie asystenta offline jako opcji w modelach od roku 2026, zaczynając od pilotażu w wybranej serii. Nie chodzi o to, by całkiem rezygnować z chmury - ale by dać kierowcy i flotom pewność, że system działa zawsze, gdy jest potrzebny.
- Natychmiastowa reakcja < 0,5 s bez zależności od chmury
- Pełna prywatność - dane głosowe i lokalizacja nie opuszczają auta
- 15,1% niższe opóźnienie względem standardowych metod na NPU
- Działanie offline w tunelach, na terenach wiejskich i w roamingu
- Redukcja kosztów transferu danych i chmurowych dla producentów
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: Quant.npu: Enabling Efficient Mobile NPU Inference for on-device LLMs via Fully Static Quantization
Autorzy: Jinghe Zhang, Daliang Xu, Chenghua Wang, Weikai Xie, Tao Qi i in.
Large language models (LLMs) are increasingly deployed on mobile devices, where Neural Processing Units (NPUs) necessitate fully static quantization for optimal inference efficiency. However, existing post-training quantization (PTQ) methods predominantly rely on dynamic activation quantization, ...
arXiv: arxiv.org/abs/2605.20295
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}