
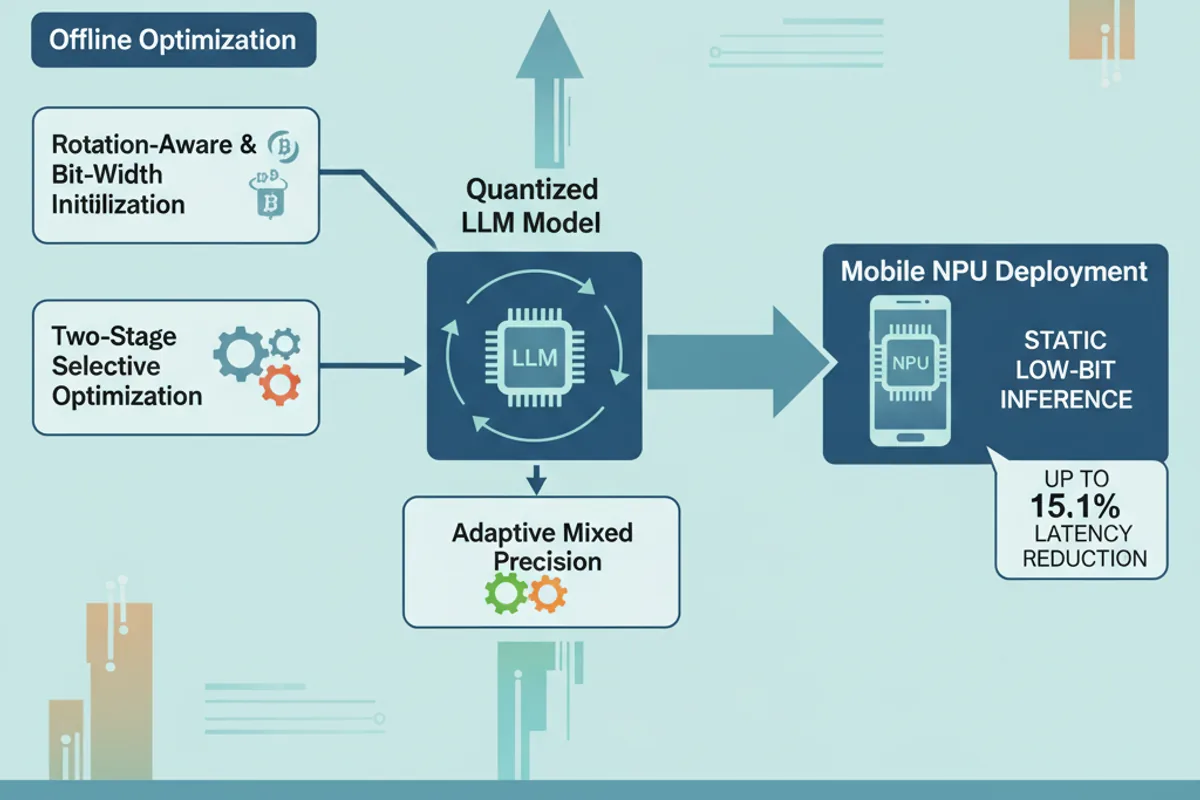
Wielkie modele językowe na smartfonach to nie mrzonka, ale do tej pory próby przenoszenia ich na mobilne układy NPU kończyły się fiaskiem - głównie przez konflikt między potrzebną im dynamiczną kwantyzacją a wymaganiami sprzętu. Zespół z Pekinu pokazał, że można to zrobić w pełni statycznie, bez utraty rozumu przez model, i przyśpieszyć inferencję o 15% względem rozwiązań producenckich.
NPU nie lubi niespodzianek - problem z dynamicznym skalowaniem
Nowoczesne telefony mają w sobie Neural Processing Unit (NPU) - wyspecjalizowane układy do szybkiego przetwarzania sieci neuronowych. Architektura NPU bardzo źle znosi liczby zmiennoprzecinkowe, za to świetnie radzi sobie z obliczeniami na liczbach całkowitych. Dlatego stosuje się kwantyzację, czyli zamianę wag i aktywacji z precyzyjnych floatów na ośmiobitowe inty.
Większość metod opartych na kwantyzacji po treningu (PTQ) używa wersji dynamicznej: skala i punkt zerowy wyliczane są na bieżąco, dla każdej partii danych. To wygodne dla badaczy, ale dla NPU to droga przez mękę. Układy te oczekują, że wszystkie parametry kwantyzacji będą raz ustalone, przed uruchomieniem. Gdy próbuje się zamrozić dynamiczne skale i zrobić z nich statyczne, precyzja modelu ostro spada. Autorzy Quant.npu podają przykład modelu SmolLM2-1.7B-Instruct, gdzie dokładność runęła o 15,61 punktu procentowego. Można to porównać do sytuacji, gdy kucharz musi gotować ściśle według przepisu, ale co chwilę ktoś zmienia mu miarki - efekt jest łatwy do przewidzenia.
Rotacje offline i dwuetapowa optymalizacja - przepis Quant.npu
Główny pomysł polega na tym, żeby nie walczyć z ograniczeniami NPU, tylko nauczyć model dobrych, stałych parametrów kwantyzacji jeszcze przed właściwą inferencją. Quant.npu robi to w dwóch etapach. W pierwszym, przy użyciu propagacji gradientu przez operację zaokrąglania (dzięki prostemu estymatorowi, STE), model uczy się parametrów skali i zera dla najbardziej wrażliwych aktywacji i wag, a także dwóch macierzy rotacji Hadamarda. Te macierze 'rozsmarowują' odstające wartości aktywacji na wiele kanałów, dzięki czemu rozkłady stają się bardziej gaussowskie i łatwiej je skwantować. Kluczowe: rotacje R1 i R2 zostają wtopione w wagi offline, więc podczas działania na NPU nie ma po nich śladu - żaden dodatkowy koszt.
Drugi etap to już prosta kalibracja statyczna pozostałych tensorów (wyjściowych, KV, funkcji aktywacji SiLU) - bez dalszego uczenia. To pozwala zachować szybkość bez degradacji jakości.
Istniejące metody kwantyzacji po treningu (PTQ) w przeważającej mierze polegają na dynamicznej kwantyzacji aktywacji, co czyni je niekompatybilnymi ze sprzętowymi ograniczeniami NPU.
Zhang i in.
abstrakt pracy
Inicjalizacja ma znaczenie - od złego startu do rozbieżności
Badacze odkryli, że nie każdy rozkład wartości można traktować tak samo przy ustalaniu początkowych skal. W warstwach, gdzie rotacja już zadziałała i rozkład przypomina dzwon Gaussa, najlepiej sprawdza się inicjalizacja oparta na średniej i odchyleniu standardowym (Mean-based). Tam, gdzie rotacji nie ma, a rozkład jest ciężkoogonowy (czyli garść bardzo dużych wartości odstających dominuje nad morzem zer), konieczna jest inicjalizacja Max-Min, która bierze pod uwagę absolutne minima i maksima. Eksperymenty pokazują, że zła inicjalizacja prowadzi do rozbieżności optymalizacji lub bardzo powolnej zbieżności - model zamiast się uczyć, błądzi po przestrzeni parametrów.
Równie istotna jest selektywność: optymalizowanie wszystkiego naraz (wszystkich parametrów kwantyzacji dla każdego tensora) okazało się przeciwskuteczne - pogarszało dokładność i wydłużało czas treningu. Lepiej skupić się tylko na aktywacjach wejściowych warstw liniowych i odpowiadających im wagach, poddanych wcześniej rotacji. Mniej znaczy więcej.
Mieszana precyzja adaptacyjna - 10% kompromisu, 100% korzyści
Mimo starań, całkowita rezygnacja z rotacji online i przejście na niskie precyzje (np. W4A8, czyli 4-bitowe wagi i 8-bitowe aktywacje) odbija się na dokładności w najgłębszych warstwach projekcyjnych (tzw. down_proj). Quant.npu radzi sobie z tym przez celowaną promocję precyzji. Mierzy się wrażliwość każdej aktywacji projekcji na kwantyzację za pomocą prostego wskaźnika błędu względnego. Tylko 10% najbardziej wrażliwych aktywacji podnosi się z 8 do 16 bitów. Efekt? Model odzyskuje prawie całą utraconą dokładność - dla Llama-3.2-3B-Instruct perplexity spada z 28,78 do 19,16, a średnia dokładność zero-shot rośnie o 12 punktów procentowych. A koszt czasowy jest minimalny, bo dotyczy tylko ułamka operacji.
Realne przyspieszenie na komercyjnym NPU
Testy przeprowadzono na rzeczywistym układzie SM8650 (znanym z flagowych smartfonów). Quant.npu w wariancie W4A8 przyśpiesza inferencję o 15,1% w porównaniu do ExecuTorch-W4A16, który używa 16-bitowych aktywacji. Wykresy opóźnienia end-to-end na zbiorach HellaSwag, Persona-Chat i DroidTask pokazują, że największe zyski są w fazie prefill, gdzie model musi przetworzyć cały prompt. Co ważne, metoda działa nie tylko na architekturze LLaMA, ale też na Qwen i SmolLM, i skaluje się do modeli 8-miliardowych.
To nie jest akademicki trik działający w symulatorze. Quant.npu generuje poprawne odpowiedzi na realnym sprzęcie, zachowując zrozumiałość i spójność tekstu przy mocno obniżonej precyzji numerycznej.
- Quant.npu umożliwia uruchamianie dużych modeli językowych na mobilnych NPU bez dynamicznego przeliczania parametrów kwantyzacji.
- Wykorzystuje rotacje offline wtopione w wagi i dwuetapową optymalizację, aby uniknąć narzutu obliczeniowego.
- Dzięki adaptacyjnej precyzji mieszanej tylko 10% aktywacji podnosi się do 16 bitów, odzyskując niemal całą utraconą dokładność.
- Na rzeczywistym układzie SM8650 inferencja jest szybsza o 15,1% niż w ExecuTorch-W4A16, przy marginalnym spadku jakości.
- Metoda działa na różnych architekturach (LLaMA, Qwen, SmolLM) i skaluje się do modeli 8-miliardowych.
Praktyczne zastosowania
Aby lepiej zrozumieć opisywaną innowację, przygotowaliśmy cztery przykłady praktycznego zastosowania tej technologii w różnych branżach:




Podsumowanie
Quant.npu pokazuje, że da się pogodzić apetyt dużych modeli z ciasnymi ograniczeniami pamięci i mocy w telefonach. W praktyce otwiera to drogę do naprawdę inteligentnych asystentów offline - tłumaczenie na żywo, podsumowywanie dokumentów czy analiza kontekstowa powiadomień - bez wysyłania danych do chmury. Dla producentów urządzeń i twórców aplikacji oznacza niższe opóźnienia i mniejsze zużycie baterii, bez kompromisu na jakości odpowiedzi.
Metryka artykułu źródłowego
Tytuł oryginalny: Quant.npu: Enabling Efficient Mobile NPU Inference for on-device LLMs via Fully Static Quantization
Autorzy: Jinghe Zhang, Daliang Xu, Chenghua Wang, Weikai Xie, Tao Qi, Yun Ma, Mengwei Xu, Gang Huang
Data publikacji: 21 maja 2026
arXiv: arxiv.org/abs/2605.20295
Napisanie tego artykułu zostało wspomagane przez sztuczną inteligencję. Treść opiera się na oryginalnym artykule naukowym, a jej dokładność została zweryfikowana automatycznie.
{kind=link}