

W sklepie OpenAI dostępnych jest ponad 6 tysięcy MedGPT - chatbotów oferujących porady medyczne. Badania pokazują, że co drugi z nich narusza podstawowe zasady bezpieczeństwa, a co czwarty generuje niebezpieczne halucynacje kliniczne. Dla urzędu rejestracji wyrobów medycznych ręczna weryfikacja każdego wniosku to fizyczna niemożliwość. Automatyczny certyfikator oparty na metrykach z badań Ogundoyina i zespołu rozwiązuje ten problem, skracając proces oceny z dni do minut.
Problem: Tysiące wniosków, zero narzędzi do ich sprawdzenia
W 2024 roku w samym sklepie OpenAI pojawiło się 6,233 MedGPT - chatbotów pozycjonowanych jako narzędzia do sprawdzania objawów, wyjaśniania leczenia czy doboru leków. Agencje ds. bezpieczeństwa pacjentów i urzędy rejestracji wyrobów medycznych nie mają procedur ani narzędzi do oceny tych produktów na masową skalę. Tradycyjny proces certyfikacji oprogramowania medycznego trwa tygodnie i wymaga analizy dokumentacji, testów klinicznych i audytu kodu. Przy tysiącach zgłoszeń rocznie jest to po prostu niewykonalne.
Badanie Ogundoyina i współpracowników pokazało skalę problemu: 49,8% MedGPT narusza próg zgodności z zasadami OpenAI, 57% modeli z funkcją Actions nie ma polityki prywatności, a użytkownicy nie potrafią rozpoznać błędów klinicznych - korelacja między ocenami gwiazdkowymi a metrykami halucynacji jest bliska zeru (poniżej 0,06). Rynek sam się nie reguluje, a pacjenci nie są w stanie ocenić, czy chatbot im szkodzi.
Technologia: Cztery metryki i jeden pipeline oceny ryzyka
Zespół badawczy opracował framework MedGPT-HEval - zestaw czterech metryk, które w kilka sekund oceniają wiarygodność medycznego chatbota bez potrzeby analizy jego kodu. Pierwsza to G-Eval - model językowy (Gemini 3.1 Pro) sprawdza odpowiedź chatbota na pytanie z benchmarku MedQA pod kątem pięciu kryteriów: spójności z zapytaniem, dokładności faktograficznej, kompletności, wiarygodności cytowań i uzasadnienia wnioskowania. Druga metryka to BARTScore - mierzy prawdopodobieństwo logarytmiczne wygenerowanego tekstu względem wejścia. Trzecia to entropia semantyczna - im wyższa, tym większa niepewność modelu i ryzyko halucynacji. Czwarta to podobieństwo kosinusowe z użyciem BioBERT, które porównuje odpowiedź z medycznie zweryfikowaną referencją.
Pipeline uzupełnia moduł wykrywania nadużyć na poziomie projektu (actor-level abuse). Analizuje on nazwę, opis i startery konwersacji chatbota pod kątem czterech kategorii naruszeń - między innymi podszywania się pod lekarza czy ukrywania faktu, że rozmówca to AI. Próg ryzyka wyznaczono metodą klasteryzacji K-średnich na poziomie 0,45. Model, który go przekracza, automatycznie trafia na listę do odrzucenia lub szczegółowej kontroli.
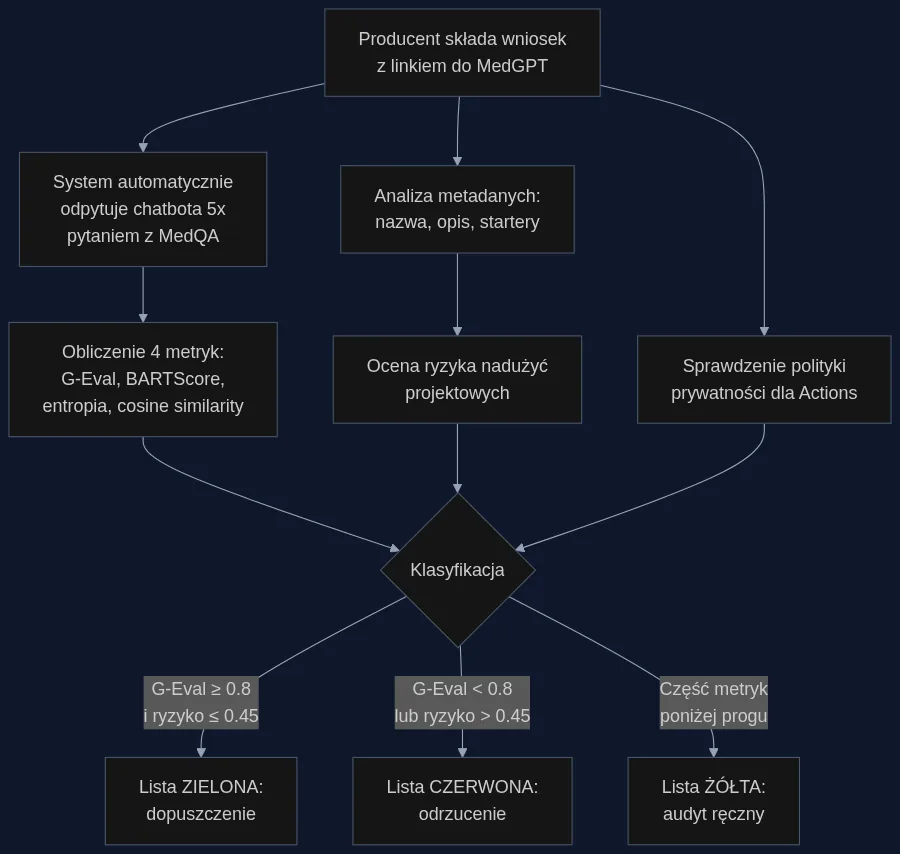
Scenariusz: Automatyczna ocena 500 wniosków w 3 godziny
Wyobraźmy sobie urząd rejestracji wyrobów medycznych, który otrzymuje 500 wniosków o dopuszczenie MedGPT do użytku publicznego w ciągu kwartału. Każdy wniosek zawiera link do chatbota w sklepie OpenAI, deklarację producenta i - w najlepszym razie - dokumentację techniczną. Bez automatyzacji zespół 5 audytorów potrzebowałby 2-3 dni na wstępną ocenę jednego chatbota - łącznie ponad 3 lata pracy na samo przejrzenie wszystkich zgłoszeń.
Z certyfikatorem opartym na MedGPT-HEval proces wygląda inaczej. System automatycznie odpytuje każdego chatbota pięciokrotnie tym samym pytaniem z bazy MedQA i oblicza cztery metryki halucynacji. Równolegle analizuje metadane - nazwę, opis, startery - pod kątem nadużyć projektowych. Dla modeli z włączoną funkcją Actions sprawdza dostępność i zgodność polityki prywatności. Po 3 godzinach urzędnik otrzymuje raport z trzema listami: modele zielone (wszystkie metryki powyżej progu), żółte (część metryk poniżej progu - wymagają dodatkowej analizy) i czerwone (G-Eval poniżej 0,8 lub wynik nadużyć powyżej 0,45 - rekomendowane do odrzucenia). Z 500 wniosków około 125-150 trafi na listę czerwoną, 170-200 na żółtą, a reszta na zieloną. Zespół audytorów skupia się tylko na żółtej grupie - 3 dni pracy zamiast 3 lat.
Korzyści i szacunkowy ROI
Wdrożenie automatycznego certyfikatora w urzędzie obsługującym 2000 wniosków rocznie daje wymierne oszczędności. Przy średnim koszcie 350 PLN za roboczogodzinę audytora i 16 godzinach potrzebnych na ręczną ocenę jednego chatbota, roczny koszt pełnej weryfikacji to około 11,2 mln PLN. Automatyzacja redukuje czas audytora do 2 godzin na wniosek (tylko grupa żółta i wyrywkowa kontrola zielonej), obniżając koszt do 1,4 mln PLN rocznie - oszczędność rzędu 9,8 mln PLN przy jednoczesnym 8-krotnym wzroście przepustowości.
Poza oszczędnościami certyfikator eliminuje ryzyko przeoczenia niebezpiecznego chatbota. Badanie pokazało, że popularność nie koreluje z bezpieczeństwem - model z 50 tysiącami konwersacji może mieć G-Eval na poziomie 0,5, a model z 500 konwersacjami osiągać 0,95. Bez automatycznej oceny urząd opiera się na deklaracjach producenta i - pośrednio - na opiniach użytkowników, które są niewiarygodne. Dodatkowo moduł analizy polityk prywatności wychwytuje 57% modeli z Actions, które zbierają dane pacjentów bez wymaganej dokumentacji - to bezpośrednie naruszenie RODO, za które urząd również ponosi odpowiedzialność, dopuszczając produkt na rynek.
Od badań do regulacji - co dalej
Framework MedGPT-HEval nie wymaga dostępu do kodu źródłowego ani współpracy z producentem - ocenia chatbota dokładnie tak, jak widzi go pacjent: przez interfejs konwersacyjny. To kluczowe dla urzędów, które nie mają uprawnień do audytu zamkniętych systemów. Zbiór danych HAA-MedGPT, udostępniony przez autorów badania, może posłużyć jako benchmark do kalibracji progów ryzyka pod specyfikę lokalnych regulacji - na przykład dostosowując próg G-Eval do wymogów konkretnego kraju.
Pierwszym krokiem jest pilotaż na próbce 200 MedGPT już dostępnych w sklepie, z porównaniem wyników automatycznej oceny z werdyktem zespołu audytorów. Przy zgodności powyżej 90% certyfikator może wejść do stałego użycia w ciągu kwartału. Kolejny etap to integracja z systemem składania wniosków online - producent podaje link do GPT, system automatycznie go testuje, a urzędnik dostaje gotowy raport przed podjęciem decyzji.
- Ocena 500 MedGPT w 3 godziny zamiast 3 lat pracy ręcznej
- Wykrywanie 25-30% chatbotów z ryzykiem halucynacji klinicznych (G-Eval poniżej 0,8)
- Identyfikacja 49,8% modeli naruszających zasady bezpieczeństwa na poziomie projektu
- Automatyczne flagowanie 57% MedGPT z Actions bez polityki prywatności - naruszenie RODO
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: Do No Harm? Hallucination and Actor-Level Abuse in Web-Deployed Medical Large Language Models
Autorzy: Sunday Oyinlola Ogundoyin, Muhammad Ikram, Rahat Masood
Medical large language models (LLMs), including custom medical GPTs (MedGPTs) and open-source models, are increasingly deployed on web platforms to provide clinical guidance. However, they pose risks of hallucination, policy noncompliance, and unsafe design. We conduct a large-scale assessment of...
arXiv: arxiv.org/abs/2605.20591
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}