

Wyobraź sobie, że wchodzisz do gabinetu lekarskiego, w którym co drugi specjalista mógłby postawić błędną diagnozę, a część z nich nie ma nawet prawa wykonywać zawodu. Tak właśnie wygląda rynek medycznych chatbotów GPT dostępnych w oficjalnym sklepie OpenAI. Międzynarodowy zespół badaczy po raz pierwszy prześwietlił 1500 takich modeli i odkrył skalę problemu, która powinna zaniepokoić każdego, kto kiedykolwiek wpisał objawy w okno czatu.
Czarna skrzynka z poradą medyczną
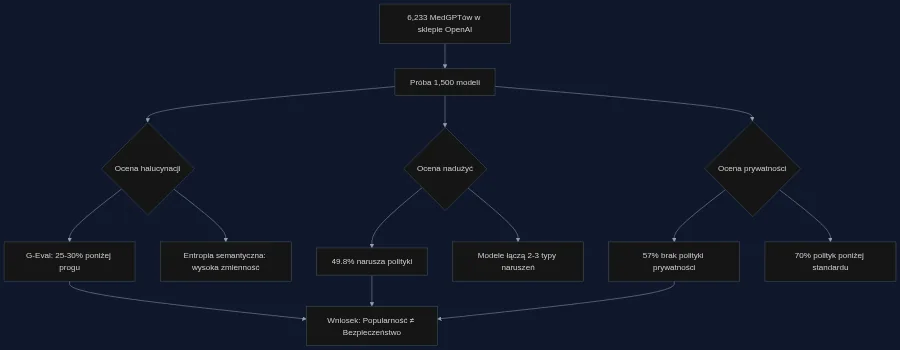
W sklepie OpenAI jest dziś ponad sześć tysięcy MedGPTów - modeli językowych dostosowanych do udzielania porad zdrowotnych, interpretowania wyników badań czy sugerowania terapii. Tworzą je duże firmy i pojedynczy programiści. Do tej pory nikt nie sprawdził, czy te narzędzia są bezpieczne.
Badacze z Macquarie University i University of New South Wales postanowili to zmienić. Zbudowali automatyczny skaner, który przeczesał sklep OpenAI w poszukiwaniu modeli z domeny medycznej. Z 6233 znalezionych GPTów wybrali próbę 1500 - tysiąc najpopularniejszych oraz po 250 ze średniej i dolnej półki popularności. Każdemu modelowi pięciokrotnie zadano to samo pytanie diagnostyczne z testu MedQA, a odpowiedzi przeanalizowano czterema niezależnymi metrykami.
Wynik? Od 25 do 30 procent MedGPTów - niezależnie od popularności - generuje odpowiedzi o niskiej wierności faktom. Co czwarty medyczny chatbot może wprowadzić użytkownika w błąd.
Gdy projektant sabotuje własne narzędzie
Zespół odkrył też zjawisko, które nazwali 'nadużyciem na poziomie aktora'. Nie chodzi o błędy modelu, ale o celowe decyzje twórców, którzy projektują GPT-y tak, by sugerowały fałszywy autorytet medyczny. Nadają im nazwy w rodzaju 'Kardiolog AI' czy 'Diagnosta', piszą opisy obiecujące zastąpienie wizyty u specjalisty, a w starterach rozmów umieszczają frazy typu 'Opisz swoje objawy, a ja postawię diagnozę'.
Do wykrywania takich nadużyć badacze użyli potoku opartego na Gemini 3.1 Pro, który oceniał nazwy, opisy i startery konwersacji pod kątem czterech kategorii naruszeń polityk OpenAI. Próg ryzyka wyznaczono przez klasteryzację K-średnich na poziomie 0,45. 54,3% modeli z pierwszej setki, 48% ze średniej i 33,6% z dolnej półki przekracza ten próg. Łącznie niemal połowa wszystkich przebadanych MedGPTów łamie zasady platformy.
Wiele modeli łączy po dwa lub trzy rodzaje naruszeń jednocześnie - na przykład mylącą nazwę z nieetycznym opisem i sugerowaniem autorytetu medycznego bez podstaw.
25-30% MedGPTów ze wszystkich poziomów popularności osiąga wynik G-Eval poniżej 0,8 - tylko 37,27% uzyskuje BARTScore ≥ -3,5, a 41,07% podobieństwo kosinusowe ≥ 0,4.
Ogundoyin i in.
Sekcja I (Wprowadzenie)
Polityka prywatności? A co to takiego?
Szczególnie niepokojące są wyniki analizy modeli z włączoną funkcją Actions. Ta opcja pozwala GPT-om łączyć się z zewnętrznymi API i przetwarzać dane w czasie rzeczywistym - na przykład pobierać informacje z bazy leków albo wysyłać zapytania do laboratorium. Oznacza to też, że mogą zbierać i przesyłać dane użytkowników.
Spośród 170 MedGPTów z aktywną funkcją Actions 57% nie udostępnia żadnej polityki prywatności. Z tych, które ją mają, blisko 70% nie spełnia podstawowych wymogów zgodności. Badacze przeanalizowali 38 dostępnych dokumentów - większość to puste deklaracje bez konkretnych informacji o tym, jakie dane są zbierane, gdzie trafiają i kto ma do nich dostęp. W kontekście danych medycznych to sytuacja niedopuszczalna.
Popularność nie chroni przed błędami
Jednym z najbardziej niepokojących wniosków z badania jest całkowity brak korelacji między popularnością modelu a jego dokładnością kliniczną. Współczynniki korelacji między liczbą konwersacji a metrykami halucynacji oscylują wokół zera - od -0,0347 do 0,0057. Podobnie jest z ocenami gwiazdkowymi.
'Wskaźniki zaangażowania użytkowników nie odzwierciedlają świadomości halucynacji klinicznych' - piszą autorzy badania. Przeciętny użytkownik nie jest w stanie ocenić, czy odpowiedź chatbota jest medycznie poprawna. Płynny, pewny siebie język modelu wystarczy, by wzbudzić zaufanie - nawet jeśli treść merytoryczna jest błędna.
MedGPTy osiągają średni wynik G-Eval na poziomie 0,92, podczas gdy otwartoźródłowe modele medyczne zaledwie 0,46. To dużo, ale entropia semantyczna MedGPTów jest wyższa (1,93 vs 1,61), co oznacza większą zmienność odpowiedzi. Ten sam model na to samo pytanie potrafi odpowiedzieć raz poprawnie, a raz całkowicie błędnie. Otwartoźródłowe LLMy są mniej dokładne, ale bardziej przewidywalne w swojej nieprzewidywalności.
- Co czwarty medyczny GPT w sklepie OpenAI generuje odpowiedzi o niskiej wierności faktom, niezależnie od swojej popularności.
- Niemal połowa (49,8%) wszystkich przebadanych modeli narusza polityki platformy poprzez mylące nazwy, opisy lub startery rozmów.
- 57% MedGPTów z funkcją Actions nie posiada żadnej polityki prywatności, a spośród tych, które ją mają, 70% nie spełnia podstawowych standardów.
- Użytkownicy nie potrafią rozpoznać błędów klinicznych - popularność i oceny gwiazdkowe nie korelują z faktyczną dokładnością modelu.
Praktyczne zastosowania
Aby lepiej zrozumieć opisywaną innowację, przygotowaliśmy cztery przykłady praktycznego zastosowania tej technologii w różnych branżach:


Podsumowanie
Badanie Ogundoyina i zespołu to sygnał alarmowy dla każdej firmy rozważającej wdrożenie medycznych chatbotów opartych na GPT. W sektorze opieki zdrowotnej, gdzie błąd może kosztować życie, samo oparcie się na popularności narzędzia jest strategią skrajnie ryzykowną. Dla integratorów systemów medycznych kluczowe staje się wdrożenie własnych warstw walidacyjnych - podobnych do użytego w badaniu frameworka MedGPT-HEval - które w czasie rzeczywistym mierzą entropię semantyczną i wierność faktom generowanych odpowiedzi. Z kolei działy compliance w firmach insurtech i telemedycynie powinny potraktować te wyniki jako podstawę do stworzenia wewnętrznych standardów audytu dostawców AI, szczególnie w zakresie polityk prywatności i transparentności źródeł danych.
Metryka artykułu źródłowego
Tytuł oryginalny: Do No Harm? Hallucination and Actor-Level Abuse in Web-Deployed Medical Large Language Models
Autorzy: Sunday Oyinlola Ogundoyin, Muhammad Ikram, Rahat Masood
Data publikacji: 21 maja 2026
arXiv: arxiv.org/abs/2605.20591
Napisanie tego artykułu zostało wspomagane przez sztuczną inteligencję. Treść opiera się na oryginalnym artykule naukowym, a jej dokładność została zweryfikowana automatycznie.
{kind=link}