
Firma farmaceutyczna wypuszcza na rynek własnego asystenta AI do informowania o lekach. Pacjenci chwalą szybkość odpowiedzi, ale nikt nie sprawdza, czy model nie zmyśla przeciwwskazań. Badanie 1500 medycznych GPT pokazuje, że popularność nie gwarantuje bezpieczeństwa - a błędy są niewidoczne dla użytkownika.
Problem, którego nie widać w pięciogwiazdkowych recenzjach
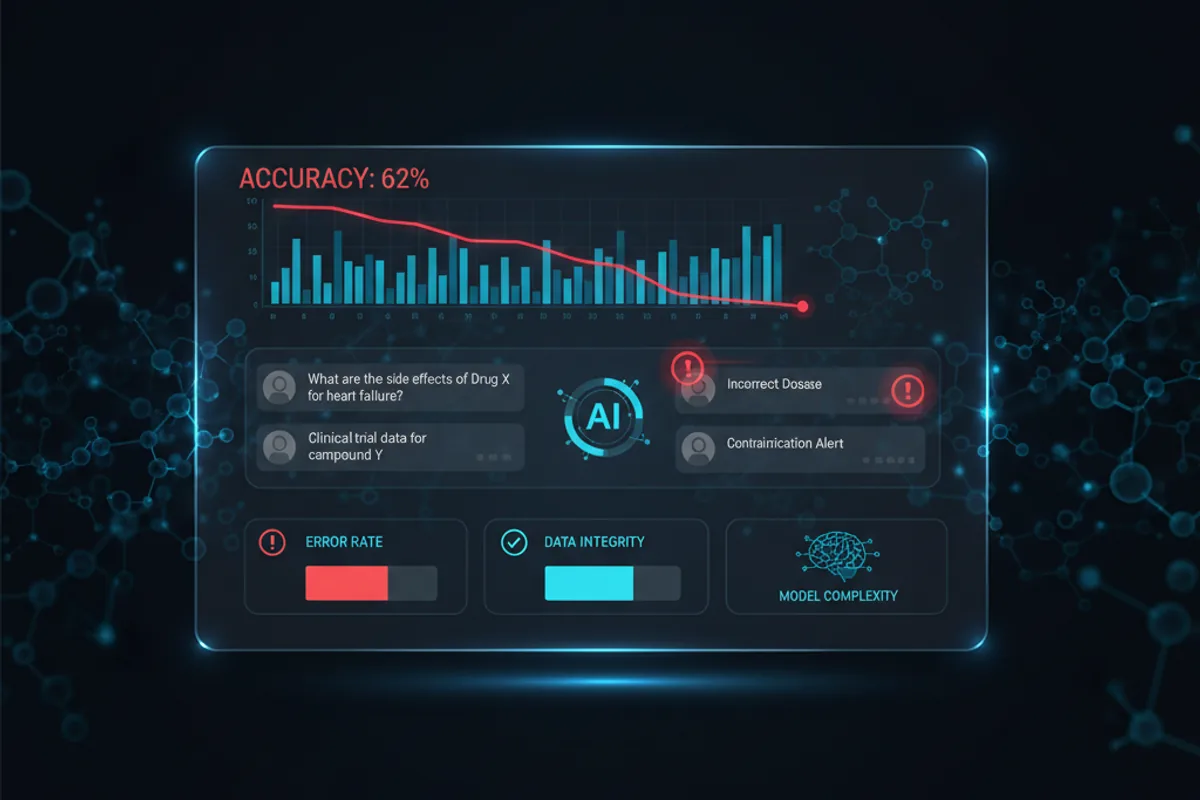
W sklepie OpenAI działa dziś ponad 6200 chatbotów oznaczonych jako medyczne. Część z nich tworzą firmy farmaceutyczne - jako asystentów wyjaśniających działanie substancji czynnych, interakcje z innymi lekami czy schematy dawkowania. Zespół Ogundoyina przebadał 1500 takich modeli i odkrył coś, co powinno zaniepokoić każdego compliance officera w branży: korelacja między ocenami użytkowników a faktyczną poprawnością odpowiedzi wynosi poniżej 0,06. Czyli żadna. Pacjent daje pięć gwiazdek, bo odpowiedź brzmi profesjonalnie - ale nie ma pojęcia, że model właśnie pominął krytyczne ostrzeżenie o interakcji z lekiem przeciwzakrzepowym.
Co dokładnie zmierzono - i dlaczego to ma znaczenie dla producenta leku
Autorzy badania zastosowali cztery metryki oceny halucynacji klinicznych. G-Eval (ocena wierności faktom przez Gemini 3.1 Pro) wypadł średnio na poziomie 0,9238 dla MedGPT - znacznie lepiej niż modele open-source (0,4558). To dobra wiadomość: komercyjne wdrożenia radzą sobie z faktami. Zła wiadomość: entropia semantyczna MedGPT jest wyższa (1,9272 vs 1,6129), co oznacza większą zmienność odpowiedzi. Ten sam prompt zadany pięciokrotnie może dać wyniki od poprawnego po niebezpieczny. Dla farmaceutycznego chatbota opisującego działania niepożądane to ryzyko, którego nie można bagatelizować.
Równolegle sprawdzono 'actor-level abuse' - celowe lub nieświadome projektowanie modelu pod kątem wywoływania wrażenia autorytetu medycznego. 54,3% chatbotów z czołówki popularności przekroczyło próg ryzyka 0,45. W praktyce oznacza to GPT nazwane 'Dr Pharma Assistant', sugerujące lekarską wiarygodność bez żadnych kwalifikacji.
Scenariusz: audyt przed premierą asystenta lekowego
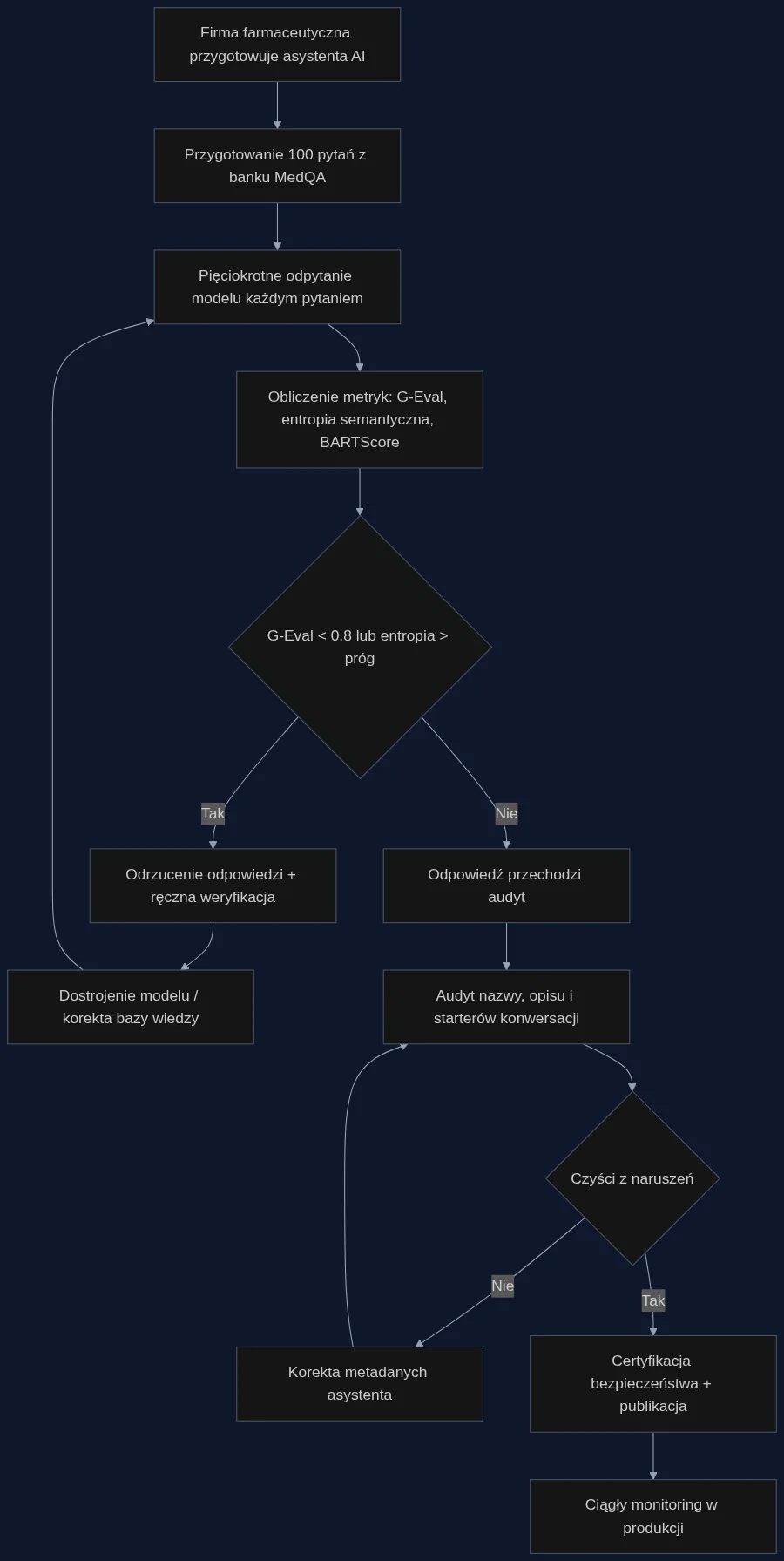
Weźmy konkretny przypadek. Producent wprowadza na rynek nowy lek biologiczny i chce udostępnić lekarzom asystenta AI odpowiadającego na pytania o mechanizm działania, interakcje i profile pacjentów. Zamiast wrzucać chatbota do publicznego sklepu i liczyć na brak skarg, firma przeprowadza audyt oparty o metodologię z badania.
Proces jest prosty: 100 pytań z banku MedQA (dostosowanych do charakterystyki leku) zadawanych jest pięciokrotnie. Odpowiedzi przechodzą przez G-Eval z progiem 0,8 - wszystko poniżej trafia do ręcznej weryfikacji. Równolegle sprawdzana jest entropia semantyczna: jeśli dla tego samego pytania model raz podaje prawidłową interakcję z metotreksatem, a raz ją pomija, system to wychwytuje. Na koniec audytor sprawdza nazwę, opis i startery konwersacji pod kątem zgodności z wytycznymi regulatora - żaden 'Dr' w nazwie, żadne sformułowania sugerujące diagnozę.
Korzyści i rachunek ekonomiczny
Koszt takiego audytu dla pojedynczego asystenta to wydatek rzędu 15-25 tysięcy złotych przy wykorzystaniu narzędzi automatycznych i kilku godzin pracy farmaceuty-weryfikatora. Dla porównania: jedno zgłoszenie działania niepożądanego wynikającego z błędnej informacji chatbota to potencjalna kara od GIF rzędu 50-500 tysięcy złotych, nie licząc kosztów reputacyjnych i pozwów cywilnych.
Dodatkowe korzyści: skrócenie czasu wdrożenia o 3-4 tygodnie (bo audyt wyłapuje problemy przed premierą, a nie po pierwszych skargach), spełnienie wymogów należytej staranności przy audycie PV (pharmacovigilance), oraz materiał do szkolenia zespołów medycznych - lista najczęstszych halucynacji modelu pokazuje, gdzie wiedza asystenta wymaga uzupełnienia.
Podsumowanie: bezpieczeństwo jako przewaga konkurencyjna
Badanie Ogundoyina pokazuje skalę problemu, ale daje też gotowy framework do jego rozwiązania. Firmy farmaceutyczne, które jako pierwsze wdrożą systematyczny audyt swoich asystentów AI, zyskają coś więcej niż zgodność z regulacjami - certyfikat bezpieczeństwa staje się argumentem sprzedażowym. Lekarz przepisujący lek i korzystający z asystenta producenta musi wiedzieć, że model przeszedł testy na halucynacje kliniczne. Pacjent czytający ulotkę generowaną przez AI musi mieć pewność, że każda odpowiedź została zweryfikowana. W branży, gdzie błąd kosztuje zdrowie, audyt przed premierą nie jest opcją - jest standardem, który dopiero się rodzi. Warto go zbudować, zanim regulator napisze go za nas.
- Wykrycie 25-30% błędnych odpowiedzi przed publikacją asystenta
- Uniknięcie kar PV od 50 do 500 tys. zł za pojedyncze zgłoszenie
- Skrócenie czasu wdrożenia o 3-4 tygodnie
- Certyfikat bezpieczeństwa jako przewaga konkurencyjna
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: Do No Harm? Hallucination and Actor-Level Abuse in Web-Deployed Medical Large Language Models
Autorzy: Sunday Oyinlola Ogundoyin, Muhammad Ikram, Rahat Masood
Medical large language models (LLMs), including custom medical GPTs (MedGPTs) and open-source models, are increasingly deployed on web platforms to provide clinical guidance. However, they pose risks of hallucination, policy noncompliance, and unsafe design. We conduct a large-scale assessment of...
arXiv: arxiv.org/abs/2605.20591
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}