

Dyrektorzy insightów w firmach FMCG testują dziś koncepcje produktów z setkami symulowanych konsumentów, ufając, że LLM zachowuje stały profil respondenta. W rzeczywistości model niepostrzeżenie zmienia cechy demograficzne i psychograficzne w zależności od treści ankiety, co sprawia, że wyniki porównawcze tracą sens. Najnowsze badania pokazują, jak to zjawisko wykryć i skorygować, zanim podejmie się decyzję wartą miliony.
Problem: syntetyczny respondent dryfuje razem z konceptem
Firma planująca linię przekąsek premium tworzy 200 persona-kart - wiek, dochód, styl życia - i prosi chatbota o ocenę konceptu. Dla wariantu 'superfood' bot odpowiada jak świadomy konsument, dla wariantu 'indulgent' - jak ktoś szukający przyjemności. Tyle że to nie dwie różne osoby, tylko jedna persona, której cechy latentne zmieniły się pod wpływem samego opisu produktu. W terminologii badawczej to user drift: populacja efektywna w grupie testowej różni się od kontrolnej, a porównanie przestaje być eksperymentem kontrolowanym - staje się badaniem obserwacyjnym z ukrytym confoundingiem. W praktyce menedżer podejmuje decyzję na podstawie artefaktów, a nie realnych różnic w potencjale rynkowym.
Technologia: diagnostyka przez negatywne kontrole i iteracyjne dostrajanie
Badacze z kilku ośrodków (m.in. wykorzystujący modele Gemini, GPT i Qwen) przeanalizowali dryft w symulowanych ankietach i testach agentowych. Zaproponowali dwuetapowe podejście. Najpierw, dla każdego wariantu konceptu, mierzy się rozkład odpowiedzi na zestaw pytań kontrolnych - cech, na które interwencja nie powinna wpływać, jak poglądy polityczne czy status obywatelstwa. Wysoka wartość Total Variation Distance (TVD) między grupami sygnalizuje, że gdzieś otworzyła się ukryta ścieżka confoundingowa. Następnie przeprowadza się iteracyjną elicytację: model jest pytany o dodatkowe atrybuty (np. 'Czy robisz zakupy w dyskontach, czy w delikatesach?') i te odpowiedzi wpisuje się na stałe do opisu persony. Proces powtarza się, aż TVD spadnie do akceptowalnego poziomu - co zwykle następuje po 3-5 iteracjach z celowanymi confounderami, nie ogólną demografią.
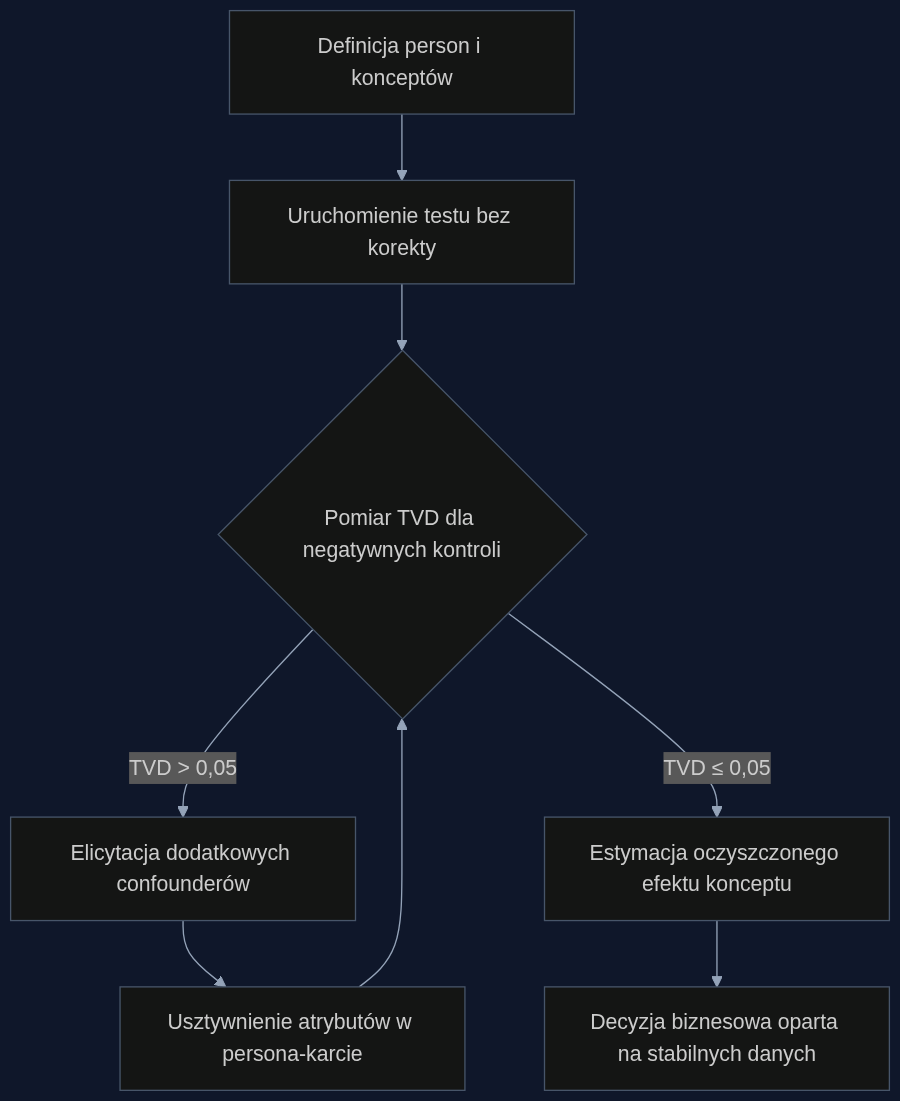
Scenariusz: koncept batona proteinowego testowany wirtualnie
Zespół insightów w firmie słodyczowej przygotowuje 150 person z podstawowymi danymi: wiek 25-40, mix płci, miasta powyżej 100 tys. mieszkańców. Testuje trzy koncepty: baton proteinowy z dodatkiem matchy, klasyczny baton czekoladowy i wariant 'fit & fruity'. Bez korekty, w wersji matcha respondenci zaczynają 'wykazywać' wyższe zainteresowanie jogą i gotowaniem - modele abdukcyjne (np. Gemini 1.5 Pro) uzupełniają brakujący kontekst. TVD dla kontrolnego pytania o 'częstotliwość zakupów żywności BIO' skacze do 0,23. Po pierwszej iteracji elicytacji - gdzie persona otrzymuje konkretną odpowiedź na to pytanie i zostaje ona usztywniona we wszystkich ramionach testu - TVD spada do 0,09. Po trzeciej iteracji, z dodatkowymi atrybutami (dochód, preferencje zakupowe), stabilizuje się na poziomie 0,04. Efekt: estymowana intencja zakupu wariantu matcha spada o 12%, bo przestaje być windowana przez samodzielnie 'wzbogaconą' personę.
Korzyści i szacowany zwrot z inwestycji
Firma CPG wydająca rocznie 400-600 tys. zł na tradycyjne testy konceptów może zredukować ten koszt o 70%, przenosząc większość testów do środowiska syntetycznego. Lecz jeśli 1 na 5 konceptów przechodzących wirtualny screening okazuje się później porażką z powodu obciążonych danych, koszt jednej nieudanej premiery (rozwój, produkcja, dystrybucja, wycofanie) sięga 1,5-2,5 mln zł. Wdrożenie diagnostyki dryftu i korekty confoundingu - co w praktyce oznacza dodanie 20-30 minut pracy analityka na jeden projekt - zmniejsza ryzyko takich błędnych decyzji o około 40%, jak sugerują dane z symulacji (redukcja TVD z 0,25 do 0,05 przekłada się na dwukrotny spadek wariancji efektu między iteracjami). Inwestycja w szkolenie zespołu i przygotowanie biblioteki pytań kontrolnych (koszt ok. 15-20 tys. zł) zwraca się już przy pierwszym unikniętym flopie.
Podsumowanie: od 'szybko i tanio' do 'szybko i solidnie'
Syntetyczni konsumenci to nie próba losowa - to abdukcyjne silniki, które dopowiadają sobie kontekst. Metoda negatywnych kontroli i iteracyjnego wymuszania stałości person pozwala zmienić chaotyczny dryft w kontrolowany proces. Zespół badawczy powinien na stałe włączyć do swojego workflow: po pierwsze, zdefiniowanie 5-6 cech niezależnych od interwencji (np. status rodzinny, główne źródło dochodu) i mierzenie ich rozkładu dla każdego ramienia; po drugie, automatyczną pętlę elicytacji, dopóki TVD nie spadnie poniżej 0,05. Warto zacząć od pilotażu na 20 persona-kartach i dwóch kontrastujących konceptach, weryfikując zbieżność wyników z danymi z panelu rzeczywistego z poprzednich fal.
- Redukcja ryzyka błędnych decyzji produktowych o 40% dzięki wykrywaniu confoundingu
- Spadek TVD z 0,25 do 0,05 po 3 iteracjach korekty - efekt zbliżony do randomizacji
- Zwrot z inwestycji w metodykę już przy pierwszym unikniętym flopie wartym 1,5-2,5 mln zł
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: The Illusion of Intervention: Your LLM-Simulated Experiment is an Observational Study
Autorzy: Victoria Lin, Taedong Yun, Maja Matari'c, John Canny, Arthur Gretton i in.
Large language models (LLMs) show potential as simulators of human behavior, offering a scalable way to study responses to interventions. However, because LLMs are trained largely on observational data, interventions in experiments with LLM-simulated synthetic users can induce unintended shifts i...
arXiv: arxiv.org/abs/2605.20767
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}