
Dostrajanie modelu językowego do konkretnego zadania często przypomina operację na otwartym mózgu - poprawiamy jedną funkcję, niechcący uszkadzając kilka innych. Naukowcy odkryli, że to 'uszkodzenie' nie jest chaotyczną destrukcją, lecz przypomina szum nałożony na klarowny sygnał. Opracowali metodę DG-Hard, która działa jak precyzyjny filtr szumów, przywracając utracone zdolności modelu w kilka minut i bez użycia jakichkolwiek danych.
Cicha katastrofa podczas dostrajania
Wyobraź sobie, że wysyłasz swojego najlepszego pracownika na kurs z negocjacji. Wraca genialnie negocjujący, ale nagle zapomina, jak obsługiwać drukarkę, nie potrafi napisać prostego maila i ma problemy z dodawaniem. Tak właśnie zachowują się modele AI po standardowym dostrajaniu (fine-tuningu).
Zespół pod kierownictwem Aarasha Abro i Muhammada Tahira z MIT przeanalizował to zjawisko na 14 parach model-zadanie. W 13 z 14 przypadków dostrojenie modelu do nowego zadania poważnie uszkodziło przynajmniej jedną z jego wcześniejszych, nietrenowanych umiejętności. W skrajnym przypadku, po dostrojeniu modelu Qwen do egzaminu medycznego MedQA, jego zdolność rozwiązywania zadań matematycznych (test GSM8K) spadła z 93% do dramatycznego 1,1%. Model dosłownie zapomniał, jak się liczy.
To zjawisko, zwane w literaturze katastroficznym zapominaniem, jest zmorą inżynierów AI. Dotychczasowe metody naprawcze albo wymagały ponownego treningu z dostępem do oryginalnych danych, albo działały jak tępe narzędzia - cofając model do stanu pierwotnego i niwelując tym samym korzyści z dostrajania.
Sygnał i szum w delcie wag
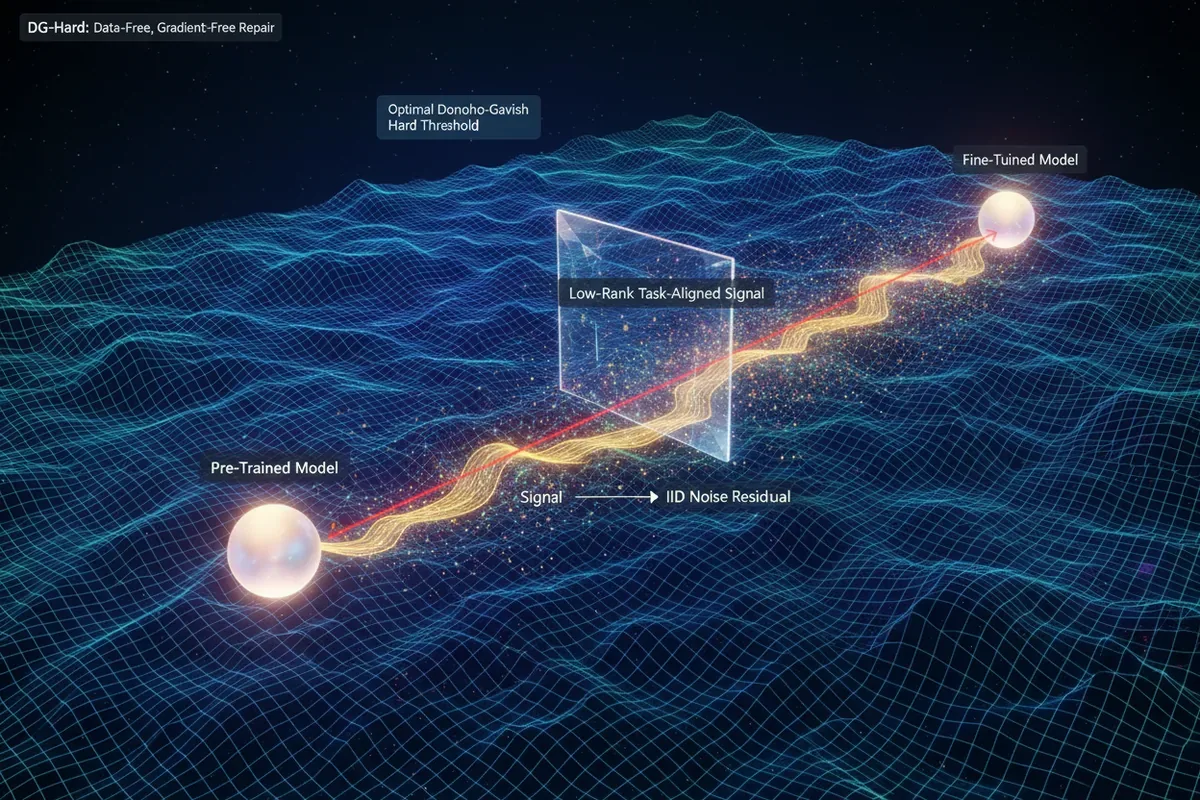
Kluczowa innowacja DG-Hard leży w świeżym spojrzeniu na to, czym właściwie jest zmiana w modelu po dostrojeniu. Naukowcy przyjrzeli się delcie (Δ) - czyli matematycznej różnicy między wagami modelu przed i po treningu. Ich hipoteza była zaskakująco elegancka: delta to nie jednolita aktualizacja, lecz suma dwóch składników.
Pierwszy to niskowymiarowy, uporządkowany sygnał - esencja nowo wyuczonego zadania. Drugi to reszta, która pod względem statystycznym zachowuje się jak czysty, losowy szum. Ten szum nie jest celowy - gradient descent, algorytm optymalizujący model, po prostu nie ma motywacji, by go usuwać. Nie przeszkadza w nauce nowego zadania, więc zostaje.
'Traktujemy Δ jako niskorzędowy sygnał zgodny z zadaniem, osadzony w reszcie szumu przypominającej IID, której gradient descent nie ma powodu usuwać' - piszą autorzy w publikacji. Mówiąc prościej: ucząc model nowej sztuczki, niechcący zaśmiecamy go losowymi błędami, które psują inne funkcje.
Dostrajanie modelu językowego do zadania docelowego rutynowo degraduje zdolności, których dane treningowe nigdy bezpośrednio nie zagroziły.
Aarash Abro i Muhammad Tahir
Abstrakt
Spektralna przepaść i próg Donoho-Gavisha
Jak oddzielić ten sygnał od szumu? Odpowiedź kryje się w widmie wartości osobliwych (singular values) macierzy delty. Gdy naukowcy rozłożyli deltę na składowe, zobaczyli coś niezwykłego - spektralną przepaść. Kilka pierwszych wartości osobliwych było gigantycznych, niosąc ze sobą uporządkowaną informację o nowym zadaniu. Cała reszta tworzyła gładki, przewidywalny rozkład, idealnie pasujący do prawa Marchenko-Pastura, które opisuje zachowanie macierzy czysto losowych.
To jak patrzenie na wykres dźwięku, gdzie kilka głośnych, czystych tonów wystaje ponad jednostajny szum tła. DG-Hard wykorzystuje matematycznie optymalny próg Donoho-Gavisha, by precyzyjnie odciąć wszystko, co znajduje się poniżej granicy szumu. Wartości osobliwe poniżej progu są zerowane, a z pozostałych rekonstruuje się 'oczyszczoną' deltę. Tę oczyszczoną wersję dodaje się z powrotem do bazowego modelu.
Metoda jest całkowicie bezdana (data-free) i nie wymaga obliczania gradientów. Wystarczy mieć zapisany model bazowy i dostrojony. Cały proces naprawy dla testowanych modeli trwał poniżej trzech minut na pojedynczym GPU.
Niespodziewany bonus: przywracanie bezpieczeństwa
Największym zaskoczeniem okazał się efekt uboczny działania DG-Hard. Modele dostrajane do całkowicie neutralnych, merytorycznych zadań często traciły swoje 'wbudowane' zabezpieczenia - zaczynały chętniej odpowiadać na szkodliwe pytania lub generować niebezpieczne treści. DG-Hard, mimo że nie dostał żadnych danych dotyczących bezpieczeństwa (alignment data), przywrócił te mechanizmy obronne.
'Wzorce zdolności i bezpieczeństwa wydają się wynikać z jednego mechanizmu, a nie trzech' - konkludują autorzy. Sugeruje to, że zarówno utrata wiedzy, jak i erozja zabezpieczeń mają wspólne źródło w tym samym szumie, który DG-Hard tak skutecznie usuwa. To eleganckie wyjaśnienie, dlaczego jedna, prosta operacja matematyczna potrafi naprawić tak różne aspekty działania modelu.
W testach na dziewięciu różnych benchmarkach, od rozumowania matematycznego (GSM8K, Math-500) przez wiedzę ogólną (MMLU, TriviaQA) po prawdomówność (TruthfulQA), DG-Hard osiągnął najlepszy bilans między przywracaniem utraconych zdolności a zachowaniem korzyści z dostrajania. Jako jedyna metoda przekroczył próg 80% zarówno w metryce 'Clean-up' (naprawa), jak i 'Retention' (zachowanie).
Dlaczego to działa lepiej niż konkurencja?
Dotychczasowe metody naprawy post-hoc działały w przestrzeni współrzędnych wag - próbowały interpolować między modelem bazowym a dostrojonym (jak WiSE-FT) lub losowo usuwać część zmian (jak DARE). Problem w tym, że w przestrzeni współrzędnych pożyteczne i szkodliwe zmiany są ze sobą całkowicie przemieszane - zarówno pod względem wielkości, jak i znaku.
DG-Hard przenosi problem do przestrzeni wartości osobliwych, gdzie sygnał i szum naturalnie się rozdzielają. To trochę jak różnica między próbą usunięcia szumu z nagrania audio poprzez ściszanie losowych fragmentów, a zastosowaniem korektora graficznego, który precyzyjnie wycina niepożądane częstotliwości.
Co więcej, im większy był początkowy zysk z dostrajania, tym lepiej DG-Hard go zachowywał - w przeciwieństwie do interpolacji liniowej, która proporcjonalnie osłabia wszystkie zmiany. Metoda selektywnie chroni kierunki o wysokich wartościach osobliwych, które niosą najwięcej informacji o nowym zadaniu.
- DG-Hard naprawia uszkodzone zdolności modelu w mniej niż 3 minuty na jednym GPU, bez potrzeby ponownego treningu czy dostępu do danych.
- Metoda opiera się na matematycznym rozdzieleniu sygnału od szumu w widmie wartości osobliwych delty wag, wykorzystując optymalny próg Donoho-Gavisha.
- W testach na 14 parach model-zadanie DG-Hard jako jedyny przekroczył 80% skuteczności zarówno w przywracaniu utraconych umiejętności, jak i zachowaniu nowo nabytych.
- Nieoczekiwanie, metoda przywraca również mechanizmy bezpieczeństwa modelu (np. odmowę odpowiedzi na szkodliwe pytania), które zostały osłabione przez neutralne dostrajanie.
Praktyczne zastosowania
Aby lepiej zrozumieć opisywaną innowację, przygotowaliśmy cztery przykłady praktycznego zastosowania tej technologii w różnych branżach:




Podsumowanie
DG-Hard to rzadki przypadek metody, która jest jednocześnie elegancka matematycznie i szalenie praktyczna. W produkcji modeli AI, gdzie każda iteracja dostrajania pod konkretnego klienta czy zadanie grozi regresją innych funkcji, DG-Hard może stać się standardowym, lekkim krokiem post-processingowym. Firmy wdrażające asystentów AI (obsługa klienta, analiza dokumentów) mogą używać go do bezpiecznego dostrajania modeli bez ryzyka utraty ogólnej wiedzy. W sektorze regulowanym, jak finanse czy medycyna, gdzie modele muszą przechodzić audyty bezpieczeństwa, zdolność DG-Hard do przywracania alignmentu bez dodatkowych danych jest szczególnie cenna. Wreszcie, dla badaczy AI, metoda ta otwiera nowy kierunek myślenia o dostrajaniu nie jako o monolitycznej zmianie, ale jako o problemie odszumiania sygnału.
Metryka artykułu źródłowego
Tytuł oryginalny: Spectral Unforgetting: Post-Hoc Recovery of Damaged Capabilities Without Retraining
Autorzy: Aarash Abro, Muhammad Tahir
Data publikacji: 21 maja 2026
arXiv: arxiv.org/abs/2605.20296
Napisanie tego artykułu zostało wspomagane przez sztuczną inteligencję. Treść opiera się na oryginalnym artykule naukowym, a jej dokładność została zweryfikowana automatycznie.
{kind=link}