
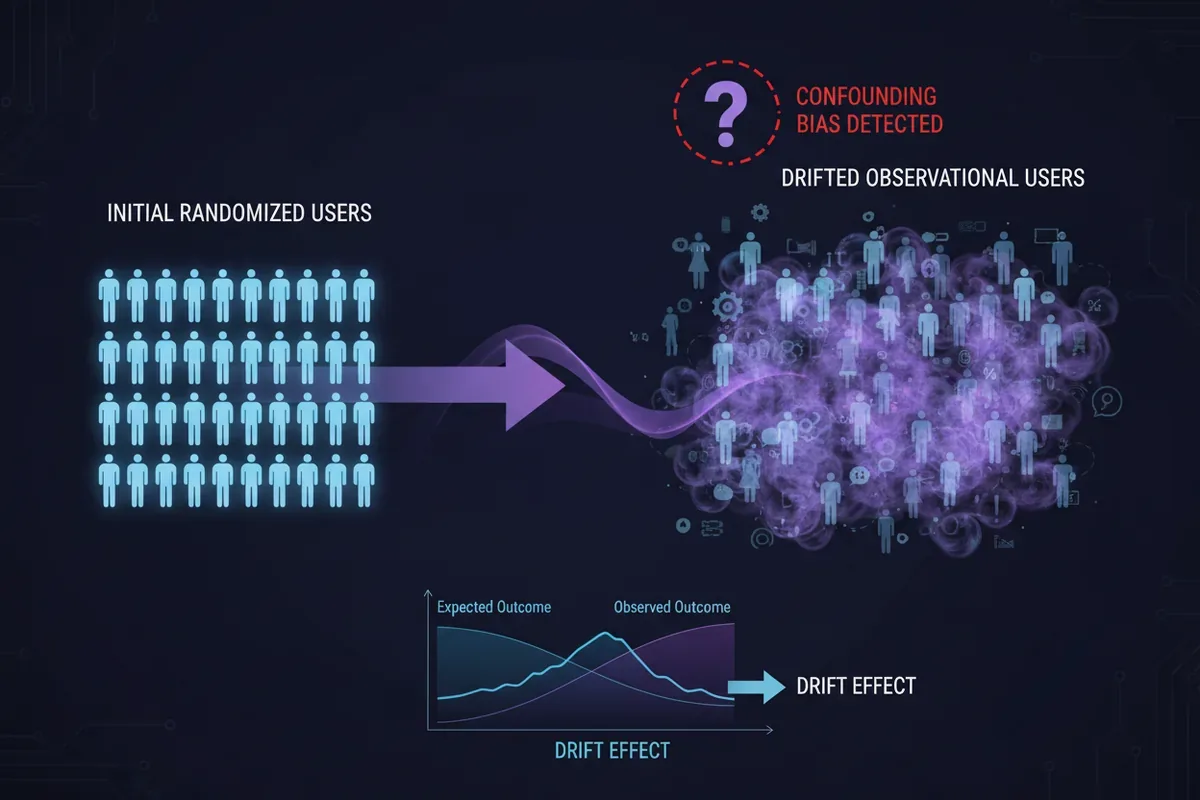
Wyobraź sobie, że testujesz dwa interfejsy aplikacji. Rekrutujesz grupę '30-letnich mężczyzn', każdemu pokazujesz inną wersję i mierzysz zadowolenie. Problem? Twoi testerzy nie są prawdziwi - to modele językowe. I właśnie okazuje się, że w zależności od tego, co im pokażesz, LLM po cichu zmienia ich profil, rujnując porównanie. Zespół Lina z Google DeepMind i UCL udowodnił, że symulacje na dużych modelach językowych to nie kontrolowane eksperymenty, a badania obserwacyjne z ukrytym błędem selekcji.
Dryf, którego nie widać na pierwszy rzut oka
Wiele zespołów produktowych sięga po LLM-y jak po tanią podróbkę grupy fokusowej. Definiują persony - '35-latka z dwójką dzieci', 'studentka informatyki' - i symulują ich reakcje na nowy komunikat czy funkcję. Logika jest prosta: skoro persona startowa jest taka sama dla wariantu A i B, to wszelkie różnice w wynikach można przypisać testowanej zmianie. Tak działa randomizowane badanie kontrolowane (RCT) - złoty standard wnioskowania przyczynowego.
Autorzy pracy 'The Illusion of Intervention' pokazują, że ta analogia się sypie. Modele językowe operują w trybie rozumowania abdukcyjnego: kiedy dostają niekompletny opis, uzupełniają go o najbardziej prawdopodobny brakujący kontekst. Dla badacza oznacza to katastrofę metodologiczną. 'Gdy dwóm syntetycznym użytkownikom dajemy tę samą personę startową, ale różne warunki interwencji, LLM wywnioskuje różne cechy latentne dla każdego z nich' - tłumaczą badacze. W jednym wariancie '30-latek' stanie się zapalonym biegaczem, w drugim kanapowcem - a badacz nawet o tym nie wie.
To zjawisko nazwali dryfem użytkownika (user drift). I nie jest to drobna niedogodność - to systematyczny błąd, który może zawyżać lub zaniżać szacowany efekt interwencji. W świecie, gdzie firmy coraz częściej testują produkty na syntetycznych użytkownikach przed wdrożeniem, konsekwencje są realne: można postawić na funkcję, która w rzeczywistości nie działa, albo porzucić obiecujący kierunek.
Dlaczego twój eksperyment to badanie obserwacyjne
Zespół formalizuje problem w języku wnioskowania przyczynowego. W prawdziwym świecie badacz nie widzi wszystkich cech uczestnika (X) - te ukryte atrybuty wpływają zarówno na to, jaką interwencję (A) ktoś otrzyma, jak i na wynik (Y). Randomizacja zrywa tę zależność, więc porównanie grup jest uczciwe.
W symulacji LLM sytuacja jest gorsza. Model dostaje na wejściu personę (L) - to, co badacz jawnie specyfikuje - i interwencję (A). Ale generując odpowiedź, sięga po bogatszy, niejawny profil użytkownika (X), który sam sobie dobudował. Co gorsza, to, co sobie dobuduje, zależy od A. Efekt? 'Obserwowany efekt nie odpowiada prawdziwemu efektowi przyczynowemu leczenia' - piszą autorzy. Pojawia się błąd selekcji (δ_SB), czyli różnica między grupami, która nie wynika z interwencji, tylko z tego, że grupy są po prostu różne.
W praktyce oznacza to, że badacz myśli, iż uruchomił RCT, a tak naprawdę prowadzi badanie obserwacyjne - tyle że bez możliwości zmierzenia confounderów w tradycyjny sposób. 'Choć syntetyczne eksperymenty mają naśladować randomizowane badania kontrolowane, LLM-y są trenowane do rozumowania abdukcyjnego: mając niedookreślone prompty, wnioskują tyle nieokreślonego kontekstu, ile są w stanie' - podkreślają Lin i współpracownicy.
W tej pracy argumentujemy, że ta wizja jest zbyt optymistyczna z powodu dryfu użytkownika w symulacjach LLM.
Lin et al.
Google DeepMind / UCL
Negatywna kontrola: test na chorobę, której nie widać
Jak zdiagnozować dryf, skoro nie widzimy ukrytych cech użytkownika? Autorzy proponują sprytny test oparty na negatywnych wynikach kontrolnych (negative control outcomes). To zmienne, na które interwencja nie powinna mieć wpływu - na przykład poglądy polityczne czy obywatelstwo - ale które są czułe na te same ukryte atrybuty, które powodują dryf.
Jeśli przy interwencji A=1 syntetyczni użytkownicy nagle zaczynają deklarować inne poglądy polityczne niż przy A=0, to znak, że populacja się zmieniła - mimo identycznych person startowych. Do pomiaru tego przesunięcia badacze używają całkowitej odległości wariacyjnej (TVD). Im wyższa wartość, tym większy dryf, a więc i większe ryzyko, że obserwowany efekt interwencji jest skażony.
W testach na danych OpinionQA, Book Opinions i MovieLens metoda działała. Rozkłady negatywnych kontroli różniły się wyraźnie między ramionami eksperymentu - zwłaszcza w początkowych iteracjach, gdy persona była uboga. Na przykład w symulacji z modelem Qwen3-30B preferencje polityczne syntetycznych użytkowników przesuwały się w zależności od tego, jaką książkę im 'polecono'. To nie interwencja zmieniła ich poglądy - to LLM wygenerował inną grupę ludzi.

Iteracyjne łatanie persony - i dlaczego demografia nie wystarczy
Skoro da się dryf zmierzyć, można go też redukować. Strategia autorów jest prosta: dodać do persony tyle confounderów, by model nie miał już miejsca na domysły. W każdej iteracji proszą syntetycznego użytkownika (przy mieszaninie obu interwencji) o ujawnienie dodatkowych cech - i doklejają je do specyfikacji. Potem mierzą TVD. Cykl się powtarza, aż odległość między rozkładami negatywnych kontroli przestanie maleć.
Wyniki eksperymentów pokazują dwa ważne zjawiska. Po pierwsze, samo dodanie ogólnych zmiennych demograficznych (wiek, płeć, dochód) może początkowo pogorszyć sytuację - TVD rośnie. Dopiero ukierunkowane confoundery, specyficzne dla domeny (np. preferencje czytelnicze w eksperymencie o książkach), konsekwentnie zmniejszają dryf. Po drugie, gdy dryf spada, szacowany efekt interwencji stabilizuje się - to znak, że wcześniejsze estymacje były zafałszowane przez błąd selekcji.
Co ciekawe, modele z silniejszym rozumowaniem abdukcyjnym (jak GPT-4) wykazywały większy dryf początkowy, ale też lepiej reagowały na ukierunkowaną korektę. Mniejsze modele (GPT-OSS-20B) pozostawały odporne na poprawki - TVD nie spadało mimo dodawania confounderów. 'Nasze ustalenia sugerują, że ewaluacje z syntetycznymi użytkownikami muszą być traktowane z ostrożnością' - konkludują autorzy.
- LLM-y uzupełniają niekompletne persony o własne domysły, a kierunek tych domysłów zależy od testowanej interwencji - to dryf użytkownika.
- Negatywne wyniki kontrolne (np. poglądy polityczne) pozwalają wykryć dryf: jeśli ich rozkład różni się między grupami, eksperyment jest skażony.
- Dodawanie ukierunkowanych confounderów do persony redukuje dryf, ale ogólna demografia może go początkowo pogłębić.
Praktyczne zastosowania
Aby lepiej zrozumieć opisywaną innowację, przygotowaliśmy cztery przykłady praktycznego zastosowania tej technologii w różnych branżach:



Podsumowanie
Praca Lina i współpracowników to sygnał ostrzegawczy dla każdego, kto testuje produkty na syntetycznych użytkownikach - od chatbotów po rekomendacje treści. W badaniach UX z użyciem LLM-ów warto rutynowo stosować negatywne kontrole i iteracyjnie wzbogacać persony o specyficzne dla domeny confoundery. W ewaluacji modeli (np. testy bezpieczeństwa agentów AI) ignorowanie dryfu może prowadzić do przeszacowania skuteczności interwencji. Wreszcie, w badaniach społecznych symulowanych na LLM-ach - gdzie modele coraz częściej zastępują respondentów - bez korekcji confoundingu wyniki są nie tyle przybliżeniem prawdy, co artefaktem architektury modelu.
Metryka artykułu źródłowego
Tytuł oryginalny: The Illusion of Intervention: Your LLM-Simulated Experiment is an Observational Study
Autorzy: Victoria Lin, Taedong Yun, Maja Matari'c, John Canny, Arthur Gretton, Alexander D'Amour
Data publikacji: 21 maja 2026
arXiv: arxiv.org/abs/2605.20767
Napisanie tego artykułu zostało wspomagane przez sztuczną inteligencję. Treść opiera się na oryginalnym artykule naukowym, a jej dokładność została zweryfikowana automatycznie.
{kind=link}