
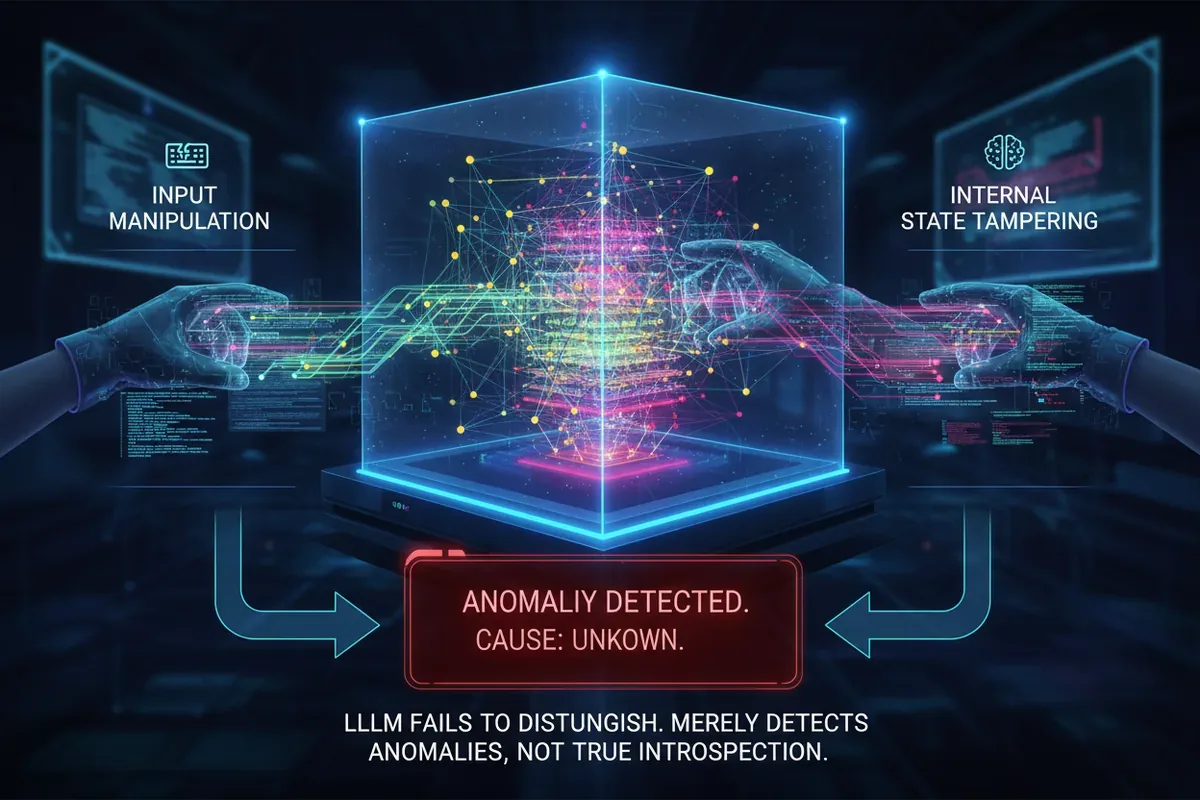
Kiedy pytasz model językowy, czy jest pewny swojej odpowiedzi, oczekujesz, że zajrzy do własnego 'wnętrza' i odpowie szczerze. Nowa analiza trzech badaczy rozbija w pył dotychczasowe dowody na taką introspekcję u LLM-ów, pokazując, że zamiast metapoznania mamy do czynienia ze sprytnym wykrywaniem anomalii i zgadywaniem na podstawie samego wejścia. Wyniki każą ostrożniej podchodzić do narzędzi, które rzekomo monitorują własną wiedzę.
Co to w ogóle znaczy, że model 'patrzy w siebie'?
W psychologii introspekcja to dość mgliste pojęcie. Ludzie nie zawsze potrafią trafnie ocenić, co wiedzą i czego nie wiedzą, potwierdza to każdy student przed egzaminem. Mimo to przez dekady badacze metapoznania próbowali oddzielić rzetelny monitoring własnych procesów od zwykłego zgadywania. Autorzy tego paperu, Shashwat Singh, Tal Linzen i Shauli Ravfogel, przypominają o fundamentalnym ograniczeniu: samo zachowanie podmiotu nie wystarczy, by orzec, że faktycznie ma on wgląd w swoje stany wewnętrzne. Trzeba kontrolowanych eksperymentów.
W przypadku modeli językowych 'patrzenie w siebie' oznaczałoby, że model potrafi wykryć i opisać swoje wewnętrzne stany, na przykład poziom niepewności związany z generowaną odpowiedzią. To kusząca wizja: wyobraźmy sobie asystenta, który przed podaniem informacji mówi: 'Tego akurat nie jestem pewien, ale...' i podaje dane, a my wiemy, że można mu ufać z ograniczonym zaufaniem. Niestety, badanie pokazuje, że dotychczasowe testy tej zdolności były naiwne. Modele uczyły się rozpoznawać wzorce na powierzchni, nigdy nie sięgając głębiej.
Wykrywanie sabotażu: alarm antywłamaniowy, nie introspekcja
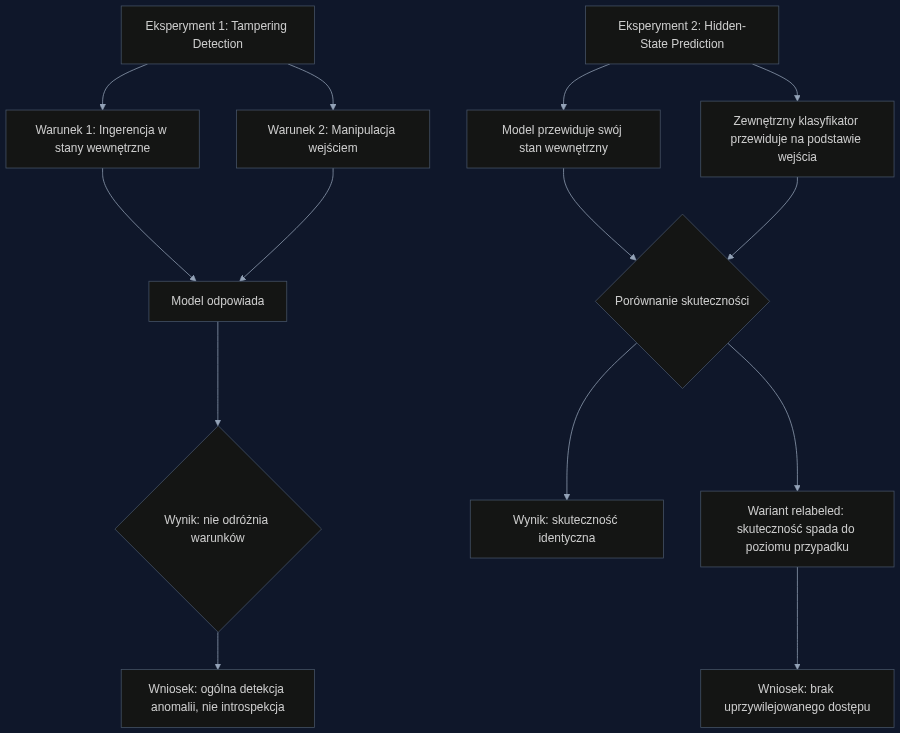
Jednym z analizowanych paradygmatów jest tak zwane tampering detection, zadanie, w którym model ma stwierdzić, czy ktoś manipulował jego wewnętrznymi reprezentacjami, czy tylko zmienił treść wejścia. Wcześniejsze prace sugerowały, że modele to potrafią, co dowodziłoby, że 'czują', kiedy grzebie się w ich neuronowych trzewiach.
Singh i współpracownicy powtórzyli te eksperymenty, ale dodali wariant, w którym manipulowano wyłącznie wejściem (np. podmieniano słowa), nie dotykając stanów wewnętrznych. Okazało się, że modele nie są w stanie odróżnić tych dwóch sytuacji. Reagowały tak samo: wykrywały, że coś jest nie tak, ale nie miały pojęcia, czy zmiana zaszła w nich samych, czy w danych, które im pokazano. To jak alarm przeciwpożarowy, który wyje zarówno przy dymie, jak i przy spalonym toście: informuje o anomalii, ale nie o jej przyczynie. Nie ma tu mowy o introspekcji, raczej o prymitywnym detektorze dziwności.
Wnioski z tej części są jasne: oryginalne badania myliły ogólne wykrywanie odstępstw od normy ze świadomością własnego stanu. W praktyce oznacza to, że nie należy ufać modelowi, który twierdzi, że 'ktoś majstrował przy moich myślach', bo równie dobrze mógł zobaczyć pomieszany tekst i spanikować.
Same dowody behawioralne z natury nie wystarczają, by potwierdzić mocne twierdzenia o introspekcji.
Shashwat Singh, Tal Linzen, Shauli Ravfogel
Streszczenie pracy
Zgadywanie ukrytych stanów: skąd wiesz, co wiesz?
Drugi test dotyczył hidden-state prediction. Poprzednie badania sugerowały, że model potrafi w kontekście (bez trenowania) przewidzieć wartość swojego wewnętrznego wektora, na przykład, czy reprezentacja na danej warstwie zakodowała informację o płci podmiotu w zdaniu. Gdyby model robił to trafnie, znaczyłoby to, że ma bezpośredni dostęp do tych reprezentacji, coś w rodzaju 'widzę swój własny umysł'.
Tym razem autorzy wytrenowali zewnętrzny klasyfikator, który dostawał tylko oryginalne wejście (tekst zdania), bez żadnego podglądania stanów wewnętrznych. Ten prosty model osiągał wyniki identyczne jak sam język LLM w wersji 'samooceny'. Innymi słowy, każdy mógłby tyle samo wywnioskować z samego pytania, nie mając dostępu do wnętrza modelu. To podważa koncepcję uprzywilejowanego dostępu: model nie ma żadnej przewagi nad zewnętrznym obserwatorem, który tylko czyta to samo zdanie.
Najciekawszy był kontrolny wariant z 'przekodowaniem' etykiet. Usunięto zależność semantyczną między zdaniem a kategorią (np. płeć została przypisana losowo), zmuszając model, by polegał wyłącznie na swoich wewnętrznych stanach. Skoro znaczenie jest bezużyteczne, tylko 'pamięć' sieci mogłaby pomóc. I tu wydajność spadła niemal do poziomu przypadku. Model nie potrafił odczytać własnych stanów, gdy nie mógł skorzystać z semantycznego zgadywania. To jakby osoba, która pamięta, że coś wie, ale nie potrafi powiedzieć co, dopóki nie podpowie się jej kontekstu. To nie jest introspekcja, tylko sprytne odtwarzanie skojarzeń.
Co to zmienia w praktyce?
Wyniki te ostudzają entuzjazm wobec samomonitorujących się agentów AI i wszelkich narzędzi, które miałyby oceniać własną niepewność bez zewnętrznych testów. W medycynie czy prawie nie można pozwolić, by system mówił 'jestem na 90% pewny', jeśli ta wartość pochodzi z mechanizmu, który w rzeczywistości przelicza podobieństwo do wzorców w danych treningowych, a nie faktyczną wewnętrzną niepewność. W biznesie, systemy decyzyjne oparte na LLM-ach muszą być wspomagane zewnętrznymi metodami walidacji, a nie polegać na autorefleksji modelu.
Badanie podkreśla też potrzebę lepszego definiowania, co znaczy 'model wie, że wie'. Na razie wiemy tylko, że modele są doskonałymi imitatorami: potrafią generować tekst, który brzmi świadomie, ale nie niosą ze sobą wewnętrznego monitoringu. Jeśli coś wygląda na metapoznanie, sprawdźmy, czy to nie jest po prostu wzorzec w danych.
- Modele LLM mylą ingerencję w swoje stany wewnętrzne z manipulacją wejściem, co świadczy o detekcji anomalii, a nie introspekcji.
- W zadaniach przewidywania ukrytych stanów zewnętrzne klasyfikatory oparte jedynie na wejściu osiągają taką samą skuteczność co autoocena modelu.
- Po usunięciu wskazówek semantycznych (relabeled control) zdolność modelu do odczytu własnych reprezentacji spada do poziomu zgadywania.
Praktyczne zastosowania
Aby lepiej zrozumieć opisywaną innowację, przygotowaliśmy cztery przykłady praktycznego zastosowania tej technologii w różnych branżach:




Podsumowanie
Badanie obala mit introspekcji w dużych modelach językowych, pokazując, że dotychczasowe testy opierały się na wykrywaniu powierzchniowych wzorców. W praktyce oznacza to, że nie można polegać na samoocenie agentów AI w dziedzinach wymagających precyzji, takich jak medycyna, prawo czy autonomiczne systemy decyzyjne. Zamiast tego, deweloperzy powinni integrować zewnętrzne mechanizmy walidacji i testy statystyczne, a także projektować systemy z wbudowaną niepewnością opartą na danych, a nie na deklaracjach modelu. Badanie dostarcza też krytycznej ramy metodologicznej dla przyszłych prac nad metapoznaniem maszyn.
Metryka artykułu źródłowego
Tytuł oryginalny: Can LLMs Introspect? A Reality Check
Autorzy: Shashwat Singh, Tal Linzen, Shauli Ravfogel
Data publikacji: 27 maja 2026
arXiv: arxiv.org/abs/2605.26242
Napisanie tego artykułu zostało wspomagane przez sztuczną inteligencję. Treść opiera się na oryginalnym artykule naukowym, a jej dokładność została zweryfikowana automatycznie.
{kind=link}