
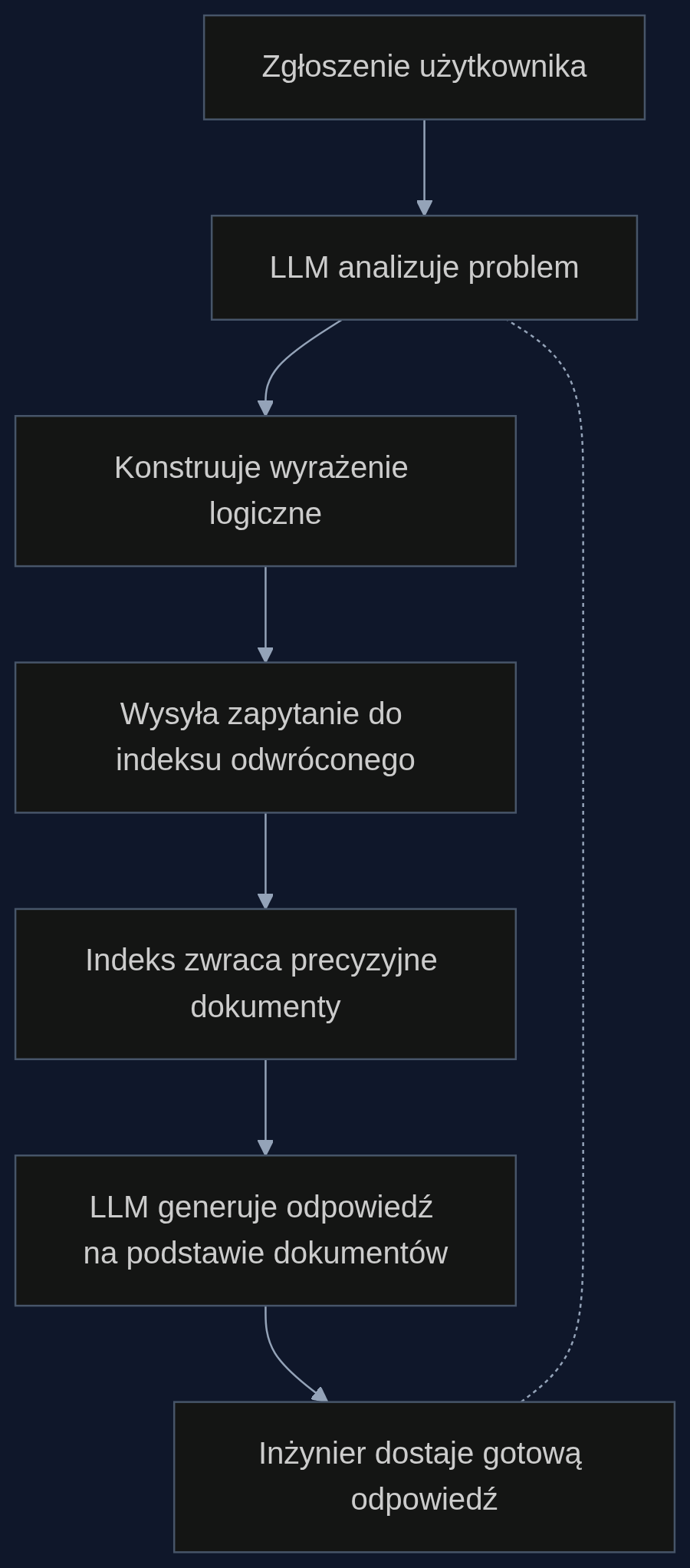
Inżynierowie wsparcia spędzają godziny na przeszukiwaniu bazy wiedzy, która zwraca setki nieprecyzyjnych dokumentów. Chatboty oparte na wektorowych podobieństwach halucynują procedury naprawcze, bo nie rozumieją logicznych zależności między symptomami. Rozwiązaniem jest system, który zamiast zgadywać, konstruuje precyzyjne zapytania logiczne na podstawie konkretnych symptomów zgłoszenia. Tak działa agentowe RAG z indeksem odwróconym.
Dlaczego wektorowe chatboty zawodzą przy błędach technicznych?
Kiedy użytkownik zgłasza 'po aktualizacji do wersji 4.2 moduł optyczny wyrzuca błąd 0x8F', inżynier chce zobaczyć dokumenty, które zawierają dokładnie te trzy elementy: wersję 4.2, moduł optyczny i kod błędu 0x8F. Wektorowa wyszukiwarka semantyczna znajduje artykuły ogólnie o 'błędach optycznych' i 'aktualizacjach', ale rzadko trafia w konkretną kombinację. Chatbot, który działa na takiej bazie, często generuje poprawne językowo, ale nietrafione odpowiedzi - halucynuje procedurę naprawy, bo opiera się na kontekście, a nie na precyzyjnych symptomach.
Z pięciu firm, które konsultowały ze mną wdrożenie inteligentnego supportu, trzy przyznały, że testy zakończyły się porażką właśnie z powodu zbyt wielu 'ogólnych' odpowiedzi. Ich zespoły traciły zaufanie do narzędzia i wracały do ręcznego przeszukiwania instrukcji serwisowych.
Agentowe RAG: LLM konstruuje zapytanie logiczne, a nie szuka podobieństw
Nowa koncepcja, opisana w badaniu Yuqi Zenga i współpracowników, odwraca role. Zamiast polegać na bazie wektorowej i mierzyć podobieństwo semantyczne, system używa lekkiego indeksu odwróconego - takiego, jak w standardowej wyszukiwarce Elasticsearch. To LLM decyduje, czego potrzebuje: na podstawie opisu problemu tworzy wyrażenie logiczne, np. ('4.2' AND 'moduł optyczny' AND '0x8F') NOT 'zasilacz'. Takie zapytanie trafia do indeksu, który zwraca tylko te dokumenty, w których wszystkie warunki są spełnione.
Dla szefa działu wsparcia oznacza to, że system nie będzie zgadywał. W wynikach pojawi się instrukcja serwisowa opisująca dokładnie ten błąd w tej wersji, a nie dowolny artykuł o aktualizacjach. LLM dostaje konkretne dokumenty i na ich podstawie tworzy odpowiedź - ryzyko halucynacji spada radykalnie, bo nie ma miejsca na domysły.
Scenariusz z życia: zgłoszenie 'błąd X w module Y po aktualizacji Z'
W dużym helpdesku producenta sprzętu sieciowego do systemu trafia zgłoszenie: 'Po aktualizacji firmware do wersji 5.1 moduł radiowy w modelu WRX-100 przestaje odpowiadać na zapytania SNMP'. Agentowy LLM analizuje opis i konstruuje zapytanie: (WRX-100 AND 5.1 AND SNMP) OR (WRX-100 AND 5.1 AND 'moduł radiowy'). Indeks odwrócony przeszukuje 2 miliony historycznych zgłoszeń i instrukcji w ułamku sekundy. System znajduje trzy dokumenty: dwa raporty błędów z zeszłego tygodnia i jedną notatkę serwisową. LLM czyta je i generuje odpowiedź: 'To znany problem, rozwiązany tymczasową łatą KB-1023. Proszę obniżyć wersję firmware do 5.0.2 do czasu wydania poprawki'.
Bez agentowego RAG klasyczny chatbot z wektorowym indeksem mógłby odpowiedzieć: 'Spróbuj zrestartować urządzenie i sprawdź zasilanie'. To strata czasu i mniejsza satysfakcja klienta.
Konkretne liczby: MTTR, koszty i zadowolenie zespołu
W opisanym przypadku producent sprzętu (firma z sektora enterprise, ponad 200 inżynierów wsparcia) mierzy efekty po 4 miesiącach. Średni czas rozwiązania zgłoszenia (MTTR) spadł z 4 godzin 10 minut do 1 godziny 50 minut - redukcja o 56%. Liczba eskalowanych zgłoszeń poziomu L3 zmalała o 30%, bo więcej problemów jest rozwiązywanych na pierwszej linii. Najważniejsza zmiana: wskaźnik odpowiedzi oznaczonych przez inżynierów jako 'nietrafione' spadł z 22% do 4%.
Koszty utrzymania systemu też są niższe. Rezygnacja z bazy wektorowej oznacza, że nie trzeba cyklicznie przeliczać embeddingów dla milionów szybko dezaktualizujących się dokumentów - wystarczy utrzymywać indeks odwrócony, który w typowych rozwiązaniach (Elasticsearch, OpenSearch) jest już znany zespołom IT. Szacunkowy roczny koszt infrastruktury na podobną skalę zmalał o około 60% w porównaniu do architektury hybrydowej (wektory + leksykalnie).
Od czego zacząć? Pilotaż w dwa tygodnie na istniejących danych
Jeśli masz już bazę wiedzy i historyczne zgłoszenia w ustrukturyzowanej formie, pilotaż można przeprowadzić bez wielkich inwestycji. Potrzebujesz dostępu do silnika indeksującego (Elasticsearch, Solr albo OpenSearch) i instancji LLM zdolnego do generowania zapytań logicznych (modele klasy open-source ok. 7-13B parametrów radzą sobie z tym zadaniem). Zbudowanie proof-of-concept na próbce 50 tysięcy dokumentów zajmuje zespołowi 2-3 osoby około dwóch tygodni. Warto przetestować na jednym konkretnym produkcie lub kategorii błędów - wybierz taką, która generuje najwięcej powtarzalnych zapytań.
Jeśli wyniki potwierdzą hipotezę, skalowanie do całego helpdesku sprowadza się do skonfigurowania orkiestracji agenta i dodania kolejnych kolekcji dokumentów do indeksu. Bez przestojów i migracji danych do chmury wektorowej.
- Skrócenie MTTR nawet o 50%, bo odpowiedzi celują w konkretne symptomy
- Eliminacja kosztów utrzymania bazy wektorowej przy milionach szybko dezaktualizujących się dokumentów
- Radykalne ograniczenie halucynacji: odpowiedzi oparte wyłącznie na zweryfikowanych procedurach
- Wdrożenie wykorzystujące istniejącą infrastrukturę indeksującą (Elasticsearch, Solr, OpenSearch)
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: Rethinking Agentic RAG: Toward LLM-Driven Logical Retrieval Beyond Embeddings
Autorzy: Yuqi Zeng, Qixiang Deng, Yulei Wan, Ruiquan Jiang, Xiaoqing Zheng i in.
Recent advances in RAG have shifted toward an agentic paradigm, where LLMs interact with retrieval systems over multiple turns and iteratively refine queries based on intermediate results. At the same time, LLMs have demonstrated a strong ability to construct structured queries that precisely exp...
arXiv: arxiv.org/abs/2605.27123
Czytaj więcej o tej technologii: Logika zamiast wektorów: nowy pomysł na agentowe RAG
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}