

Dyrektorzy badan i rozwoju w farmacji codziennie staja przed zalewem nowych publikacji klinicznych. Reczne wyszukiwanie w nich konkretnych wynikow liczbowych, jak odsetek poprawy EASI-75 powyzej 60% w grupie pacjentow z AZS, zajmuje analitykom tygodnie, a duze modele jezykowe czesto te liczby zmy slaja. Blad w takiej informacji to nie tylko zmarnowany budzet, ale ryzyko regulacyjne przy rejestracji leku.
Problem: morze PDF-ow i limit ludzkiej uwagi
Przecietny dzial badań klinicznych sledzi ponad 500 nowych badan miesiecznie, kazde opisane w 40- do 80-stronicowym pliku. Analitycy szukaja odpowiedzi na pytania w stylu: "Pokaz mi wszystkie badania fazy III inhibitorow JAK w AZS z poprawa EASI-75 powyzej 60% i liczba pacjentow wieksza niz 200". Takie zlecenie wymaga czytania abstraktow, tabel z wynikami i list kryteriow wlaczenia osobno dla kazdej publikacji. Z doswiadczenia kilku firm CRO wiem, ze jeden analityk potrafi stracic na to trzy tygodnie, a i tak pominie 15-20% istotnych publikacji z powodu zmeczenia.
Potem wkracza pokusa: uzyjmy duzego modelu jezykowego (LLM) z dostepem do bazy dokumentow. Problem w tym, ze standardowy RAG oparty na porownywaniu semantycznym wektorow nie gwarantuje, ze odpowiedziec na pytanie "> 60%" faktycznie pochodzi z dokumentu, ktory te liczbe zawiera. Model potrafi wygenerowac prawdopodobna, ale nieprawdziwa wartosc, a w branzy farmaceutycznej taka halucynacja moze kosztowac miliony i skonczyc sie odrzuceniem wniosku przez regulatora.
Agentowe RAG ze sterowaniem logicznym
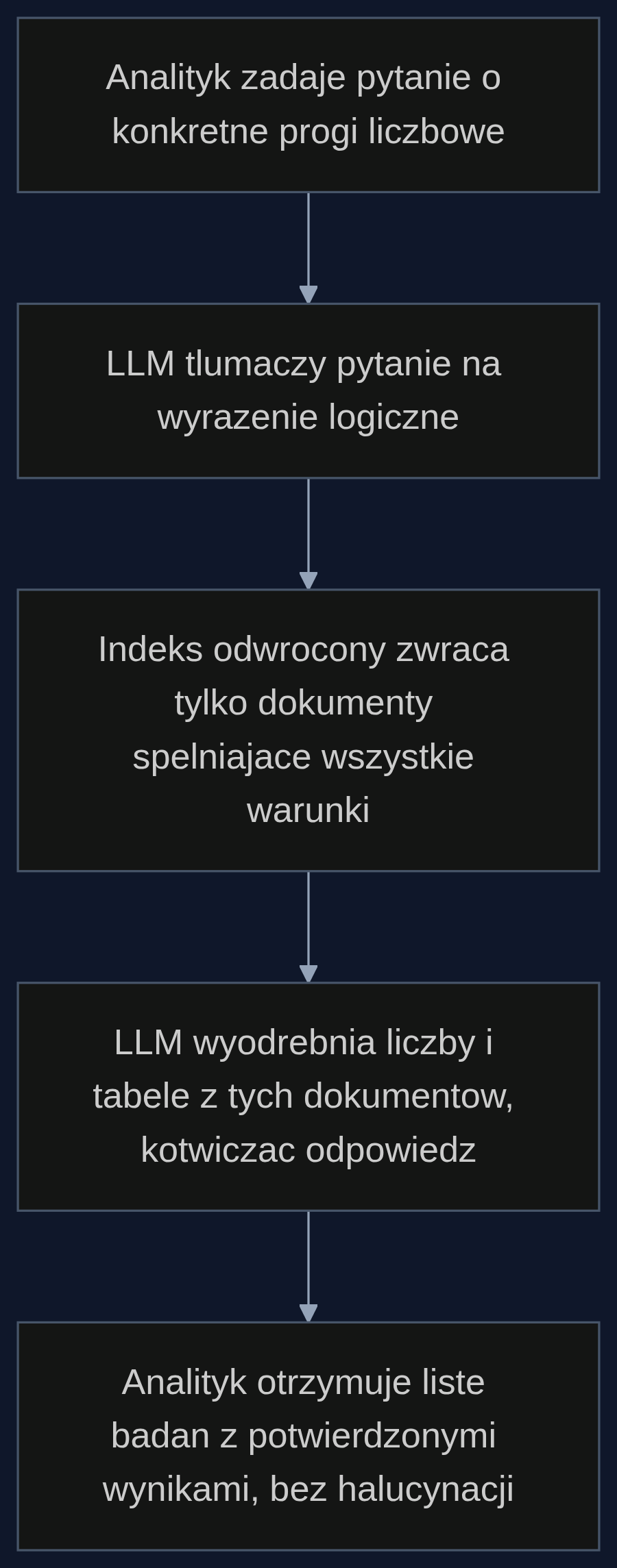
Z najnowszych badan (Zeng i wspolpracownicy) wynika, ze rozwiazaniem jest przeniesienie kontroli na strone LLM nie tylko przy generowaniu odpowiedzi, ale tez przy formuowaniu zapytan do silnika wyszukiwania. Zamiast kodowac tresci w gestych wektorach, korzystamy z lekkiego indeksu odwroconego (odwroconego indeksu slow), ktory potrafi obslugiwac zapytania logiczne. Model jezykowy tlumaczy pytanie analityka na wyrazenie boolowskie, na przyklad: ('faza III' AND 'inhibitor JAK' AND 'AZS' AND 'EASI-75 > 60%' AND 'pacjenci >= 200'), a wyszukiwarka zwraca tylko dokumenty spelniajace wszystkie te warunki.
To tzw. agentowe RAG z logicznym kotwiczeniem. Jak pisza autorzy: "LLM moze skutecznie wyra zac intencje wyszukiwania jako wyrazenia logiczne, dajac mu precyzyjna kontrole nad procesem pobierania danych". Dzieki temu kazda liczba w koncowej odpowiedzi ma przypisane zrodlo, a ryzyko zmy slenia spada do minimum.
Scenariusz: inhibitor JAK i EASI-75
Wyobrazmy sobie analityka, ktory szuka badan fazy III dla inhibitorow JAK w atopowym zapaleniu skory (AZS). Chce znalezc te, gdzie odsetek pacjentow osiagajacych co najmniej 75% poprawe w skali EASI przekroczyl 60%, a liczebnosc probnej wyniosla co najmniej 200 osob. Do tego nalezy odfiltrowac protokoly z chorobami watroby w kryteriach wykluczenia.
W tradycyjnym podejsciu trzeba by recznie przejrzec 800 dokumentow. W systemie z agentowym RAG analityk wpisuje pytanie naturalnym jezykiem. LLM rozbija je na logiczne bloki: wskazuje nazwy lekow, fazy, punkty koncowe i ich progi oraz slowa kluczowe z kryteriow wylaczenia. Nastepnie formuuje zapytanie, ktore trafia do indeksu odwroconego. Ten w ciagu kilku sekund przetrzasa 500 tys. plikow i zwraca 7 badan dokladnie spelniajacych kryteria. Analityk widzi nie tylko liste, ale i konkretne liczby wyciagniete wprost z dokumentow, z wykorzystaniem LLM dopiero na tym etapie, gdy kontekst jest juz zawczony do zweryfikowanych zrodel.
Korzysci: czas, koszty, zero zmy slonych liczb
Firmy CRO, z ktorymi rozmawialem, przyznaja, ze tradycyjny system hybrydowy (polaczenie wektorow i slow kluczowych) generuje koszt rzedu 3-5 tys. dolarow miesiecznie za utrzymanie GPU dla 100 tys. dokumentow. Wdrozenie indeksu odwroconego opartego o logike redukuje te wydatki o okolo 80%, bo calosc dziala na zwyklym serwerze CPU. Jednoczesnie czas analizy dla typowego przegladu zlecenia skraca sie z trzech tygodni do dwoch, trzech godzin.
Jednak najwieksza wartosc to bezpieczenstwo liczb. Kazdy wynik mozna kliknac i przejsc do zdania w PDF-ie. Wedlug badan Zeng i wspolpracownikow, strategia logicznego kotwiczenia "znaczaco redukuje halucynacje" w porownaniu z klasycznym RAG. To kluczowe, gdy jeden bledny wpis moze doprowadzic do zatwierdzenia kierunku badan opartego na falszywych danych.
Podsumowanie
Agentowe RAG z logicznym sterowaniem to nie kolejna futurystyczna obietnica. Mozna je przetestowac na wlasnym repozytorium 500 badan w ciagu tygodnia, korzystajac z jednego otwartego modelu do formuowania zapytan i standardowej biblioteki indeksu odwroconego. Zanim zainwestujecie w kosmiczne klastry GPU, sprawdzcie, czy logika nie wystarczy. Oszczednosci sa wymierne, a bledow w tabelach wynikowych nie bedzie trzeba dwa razy sprawdzac.
- Koniec z halucynacyjnymi liczbami: kazdy wynik da sie przypisac do konkretnego dokumentu.
- Od tygodni do godzin: czas analizy sredniego przegladu 800 badan skrocony z trzech tygodni do trzech godzin.
- Infrastruktura za grosze: zamiast GPU do wektorow wystarczy prosty indeks odwrocony na standardowym serwerze, co obniza koszt utrzymania o okolo 80%.
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: Rethinking Agentic RAG: Toward LLM-Driven Logical Retrieval Beyond Embeddings
Autorzy: Yuqi Zeng, Qixiang Deng, Yulei Wan, Ruiquan Jiang, Xiaoqing Zheng i in.
Recent advances in RAG have shifted toward an agentic paradigm, where LLMs interact with retrieval systems over multiple turns and iteratively refine queries based on intermediate results. At the same time, LLMs have demonstrated a strong ability to construct structured queries that precisely exp...
arXiv: arxiv.org/abs/2605.27123
Czytaj więcej o tej technologii: Logika zamiast wektorów: nowy pomysł na agentowe RAG
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}