

Weryfikatorzy toną w zalewie wypowiedzi polityków, gdzie każda dotyczy dat, kwot i nazwisk. Sprawdzenie ich ręcznie to godziny klikania w rejestry. Prosta rama agentowego RAG, operująca na logicznych zapytaniach i indeksie odwróconym, może to robić w kilka sekund, za ułamek kosztów obecnych systemów.
Problem: więcej tez niż czasu
Redakcje fact-checkingowe, jak te w Demagogu czy w AFP, sprawdzają dziennie dziesiątki obietnic wyborczych, wypowiedzi sejmowych i ogłoszeń rządowych. Większość dotyczy konkretnych zdarzeń: "podpisaliśmy umowę na 340 milionów w lipcu 2022 roku", "bezrobocie spadło o 1,2 punktu procentowego". Żeby to zweryfikować, trzeba przekopać archiwa transkrypcji, rejestry umów, bazy GUS. W praktyce jeden dziennikarz może zrobić dwie, trzy takie analizy dziennie. Reszta tez czeka albo przechodzi bez sprawdzenia. Przy budżecie organizacji non profit, który często opiera się na grantach, nie ma mowy o zatrudnianiu armii analityków.
Z moich rozmów z szefami redakcji wynika, że kluczowym ograniczeniem nie jest brak chęci, tylko prędkość żmudnego sprawdzania. Potrzebują narzędzia, które w kilka chwil powie: "w transkrypcji z 15 lipca 2022 rzeczywiście padła kwota 340 mln, ale umowa z rejestru wskazuje na 290 mln". I poda konkretny link do źródła.
Rozwiązanie: agent, który zadaje logiczne pytania
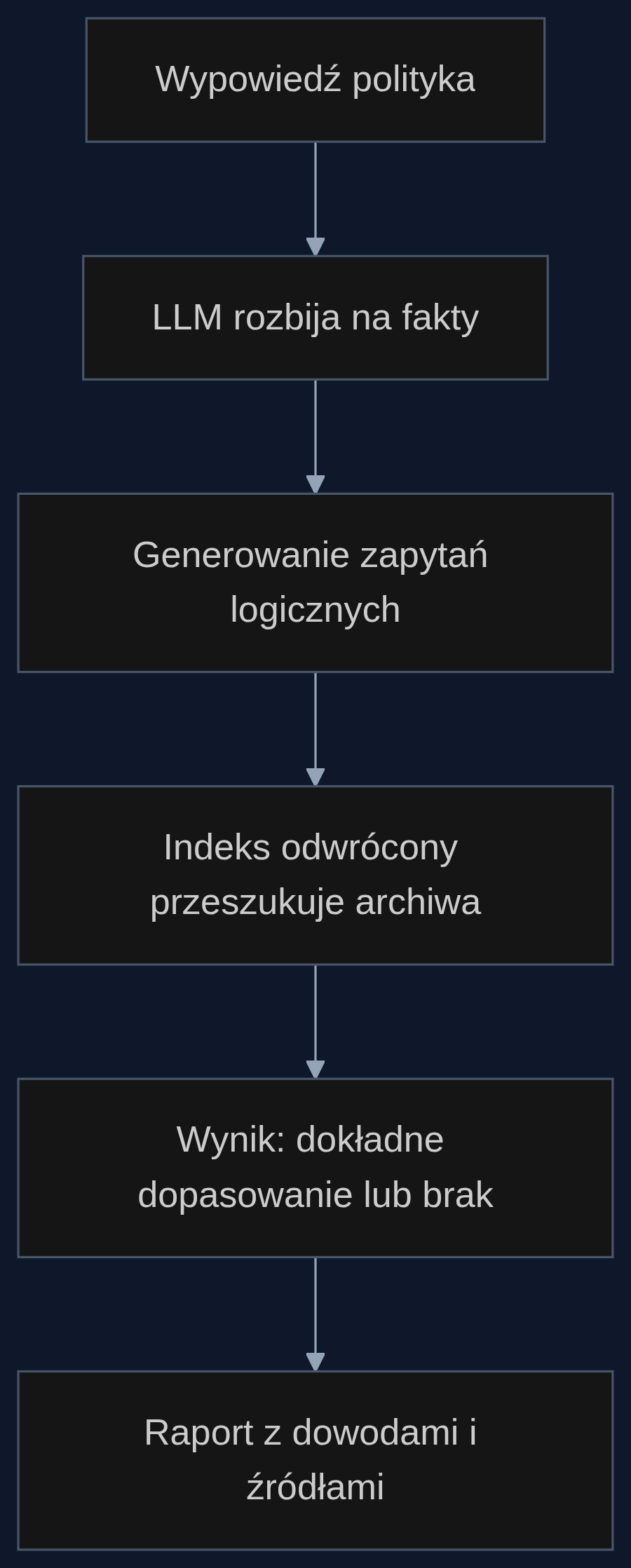
Nowa rama agentowego RAG (Retrieval-Augmented Generation) idzie pod prąd trendom. Zamiast opierać się na kosztownych embeddingach i wyszukiwaniu wektorowym, stawia na precyzyjne zapytania logiczne formułowane przez duży model językowy (LLM). To trochę jakby asystent fact-checkera sam rozbijał tezę na składowe i generował zapytanie do klasycznej wyszukiwarki opartej na indeksie odwróconym.
Kluczowa jest tu rezygnacja z przeszukiwania zbliżonych semantycznie tekstów, które często prowadzi do halucynacji. Zamiast tego LLM tworzy wyrażenia logiczne, np. "dokument zawiera 'umowa' ORAZ '340' ORAZ datę pomiędzy 2022-07-01 a 2022-07-31". Indeks odwrócony wykonuje je natychmiast i zwraca dokładne dopasowania - albo ich brak. Każde potwierdzenie lub obalenie tezy ma sztywny, powtarzalny dowód w postaci zapytania i wyniku. Redaktor widzi nie tylko odpowiedź, ale i logikę, która za nią stoi.
Scenariusz: polityk mówi o umowie, system znajduje konkret
Wyobraźmy sobie debatę, w której jeden z kandydatów deklaruje: "Za moich rządów podpisaliśmy kontrakt z firmą X na budowę szpitala. Wartość to 180 milionów złotych, umowa z marca 2023 roku." Fact-checker wkleja cytat do narzędzia opartego na omawianej ramie.
System, wykorzystując LLM, rozbija zdanie na trzy fakty do zweryfikowania: (1) czy istnieje umowa z firmą X, (2) czy jej wartość to 180 mln, (3) czy data zawarcia to marzec 2023. Dla każdego z nich generuje zapytanie logiczne do indeksu archiwalnych rejestrów zamówień publicznych (np. bazy TED albo krajowego BIP). W ciągu paru sekund zwraca wynik: "Znaleziono umowę z firmą X z 28.03.2023 o wartości 176 mln." Różnica 4 milionów jest od razu widoczna, a źródłem dowodu jest bezpośredni link do konkretnego wpisu w rejestrze.
Co istotne, gdyby w indeksie nie było takiej umowy, system odpowiedziałby jednoznacznie "brak dowodu" zamiast generować prawdopodobne streszczenie na podstawie podobnych tekstów. To eliminuje syndrom "pewnie chodziło o..." typowy dla chatbotów uczących się na wektorach.
Dlaczego to rozwiązanie jest tanie i praktyczne
Większość komercyjnych systemów fact-checkingowych opiera się na przetwarzaniu języka naturalnego z użyciem embeddingów i baz wektorowych. Ich wdrożenie to koszt rzędu kilkudziesięciu tysięcy złotych miesięcznie za infrastrukturę plus opłaty za API modeli. Dla redakcji zatrudniającej trzy osoby to często bariera nie do przeskoczenia.
Opisywana rama używa uproszczonego backendu - indeksu odwróconego - który można postawić na zwykłym serwerze za kilkaset złotych miesięcznie. Koszt budowy takiego indeksu to głównie jednorazowy wydatek na programistę, który połączy go z archiwami publicznymi. Później utrzymanie to znikome obciążenie. Dla organizacji non profit, które już i tak mają dostęp do rejestrów przez API, całość zamknie się w niskim czterocyfrowym budżecie rocznie.
Z mojego doświadczenia wynika, że kluczem nie jest potężny model językowy, ale właśnie lekki backend wyszukiwania. Redakcje często dysponują już umowami z dostawcami danych. Wpięcie w to warstwy logicznych zapytań z LLM-em jako tłumaczem intencji daje szybki zysk bez przepłacania.
Od czego zacząć w swojej redakcji
Najprostszy pilotaż to zbudowanie indeksu odwróconego z kilkuletnich transkrypcji sejmowych (dane jawne z sejmometra) i rejestru umów centralnych (część już dostępna przez API). Następnie połączenie go z modelem językowym - do testów wystarczy tańszy model w chmurze, np. GPT-4o mini. W pierwszym tygodniu sprawdźcie 30 tez, które już ręcznie analizowaliście, i porównajcie czas dojścia do dowodu. Widziałem wdrożenia, gdzie ręczna weryfikacja 10 wypowiedzi zajmowała 4 godziny, a z narzędziem schodziła do 15 minut, z pełną ścieżką dowodową. Jeśli system sprawdzi się na małej skali, można rozszerzać indeks o nowe źródła.
Redakcje, które podejmą ten wysiłek jako pierwsze, dostaną przewagę w szybkości publikacji sprostowań - a w walce z dezinformacją każda godzina ma znaczenie.
- Weryfikacja jednej tezy w kilkanaście sekund zamiast godzin
- Odpowiedzi oparte na twardych dowodach logicznych, nie na statystycznym prawdopodobieństwie
- Koszt budowy i utrzymania na poziomie dostępnym dla organizacji non profit
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: Rethinking Agentic RAG: Toward LLM-Driven Logical Retrieval Beyond Embeddings
Autorzy: Yuqi Zeng, Qixiang Deng, Yulei Wan, Ruiquan Jiang, Xiaoqing Zheng i in.
Recent advances in RAG have shifted toward an agentic paradigm, where LLMs interact with retrieval systems over multiple turns and iteratively refine queries based on intermediate results. At the same time, LLMs have demonstrated a strong ability to construct structured queries that precisely exp...
arXiv: arxiv.org/abs/2605.27123
Czytaj więcej o tej technologii: Logika zamiast wektorów: nowy pomysł na agentowe RAG
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}