

Standardowe modele językowe nadużywają fraz takich jak 'zagłębimy się', 'kluczowe znaczenie' czy 'odkryj, jak' do tego stopnia, że czytelnik wyczuwa sztuczność po pierwszym akapicie. Dla dyrektora marketingu to nie tylko kwestia estetyki. To realne ryzyko utraty zaufania konsumentów i problem z detektorami AI, które obniżają widoczność treści.
Problem: schematyczny język, który zabija autentyczność marki
Badanie opublikowane przez Rohana Mahapatrę przeanalizowało 17 modeli językowych, od tych ważących 410 milionów parametrów po modele z ponad 100 miliardami. Wynik jest druzgocący dla każdego, kto próbował skalować produkcję treści marketingowych za pomocą AI. Modele wzmacniają pewne cechy stylistyczne średnio o 16 853 procent w porównaniu z tekstem pisanym przez ludzi. Fraza 'in conclusion' pojawia się 50 razy częściej niż w korpusie treningowym. 'Delve into' (odpowiednik naszego 'zagłębimy się') jest nadużywane 36-krotnie. Listy numerowane i wypunktowania występują z częstotliwością odpowiednio 19 i 30 razy wyższą od naturalnej.
Jednocześnie modele tłumią złożoną interpunkcję. Średniki spadają do 3,2 procent bazowej częstotliwości. To nie jest subtelna różnica. To stylistyczny kolaps, który sprawia, że teksty AI są natychmiast rozpoznawalne, a co gorsza, łatwe do wykrycia przez klasyfikatory oparte na tych samych wzorcach dystrybucyjnych.
Technologia: regularyzacja entropii jako mechanizm kontroli stylu
Mahapatra udowodnił, że źródłem problemu nie jest dostrajanie instrukcji ani RLHF. Pary modeli bazowych i instruowanych wykazują statystycznie identyczne wzorce rozbieżności stylistycznej (p powyżej 0,25). Przyczyna leży głębiej, w samym pretreningu, i ma naturę mechanistyczną. Gdy model generuje element strukturalny, na przykład nagłówek, wchodzi w tak zwany 'absorbujący stan stylistyczny'. Niska entropia tego elementu ogranicza dalszą generację do podobnych, sztywnych wzorców. Powstaje samowzmacniająca się pętla.
Rozwiązaniem jest regularyzacja entropii. To technika treningowa, która karze model za zbyt pewne, niskoentropijne predykcje. Wzór jest prosty: do standardowej straty entropii krzyżowej dodaje się ważoną premię za entropię rozkładu wyjściowego. Kluczowe jest jednak natężenie tego mechanizmu. Słaba regularyzacja (lambda równe 1,0) pogarsza problem o 240 procent. Dopiero silna regularyzacja (lambda równe 5,0) przynosi 40,5-procentową poprawę w dopasowaniu stylistycznym. Model 410M z tą techniką przewyższa API GPT-4o-mini, Claude-Haiku i Gemini-Flash o 96,7 do 98,2 procent w metrykach zgodności stylu, mimo 200- do 1000-krotnej przewagi skali tych drugich.
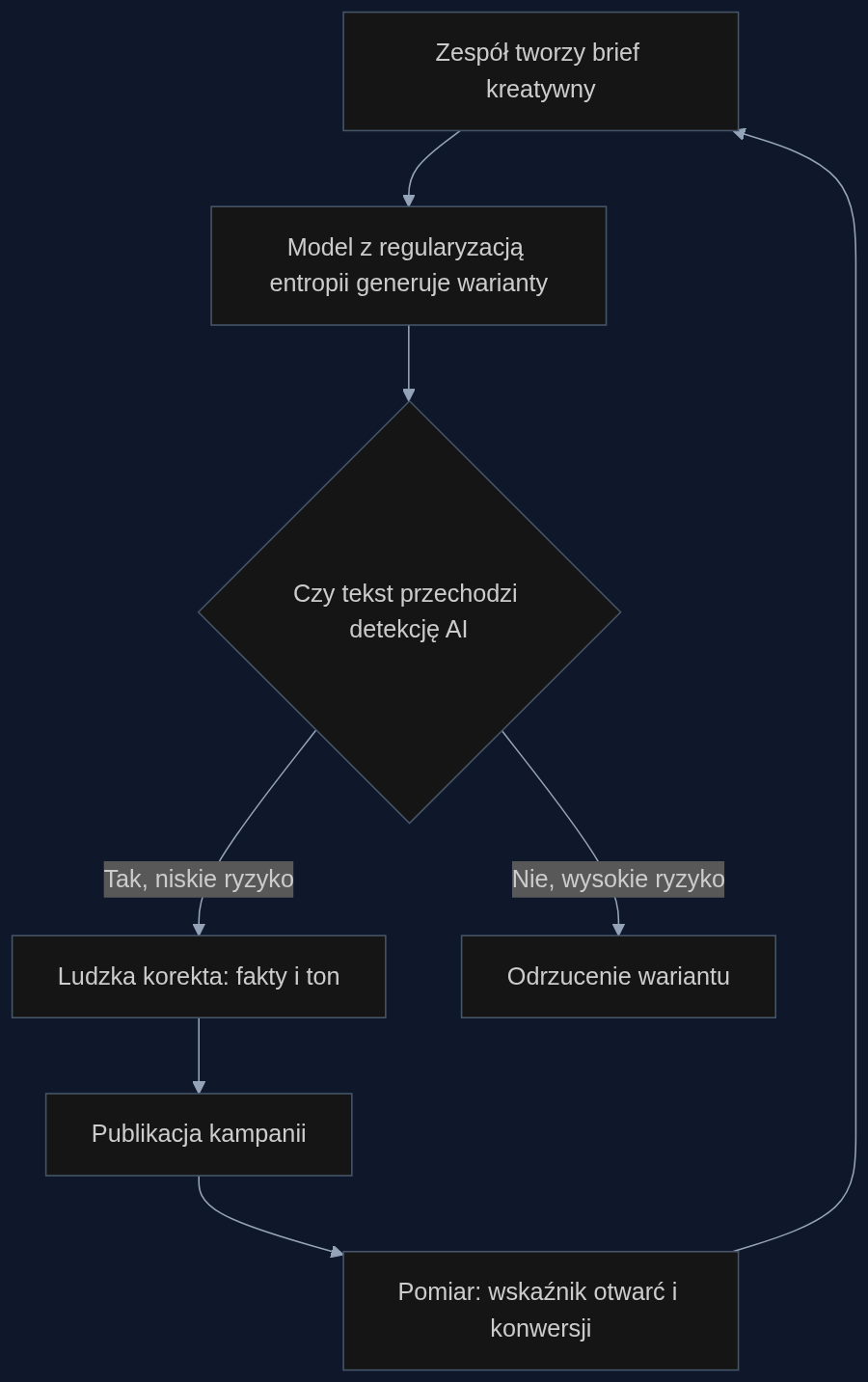
Scenariusz: kampania e-mailowa dla marki kosmetyków premium
Wyobraź sobie sieć perfumerii z segmentu premium, która wysyła cotygodniowy newsletter do 200 tysięcy subskrybentów. Zespół contentowy, złożony z trzech copywriterów, nie jest w stanie ręcznie tworzyć wszystkich wariantów tematycznych, lokalizowanych na cztery rynki i personalizowanych pod segmenty klientów. Standardowy model językowy generuje teksty poprawne gramatycznie, ale po trzecim newsletterze wskaźnik otwarć spada o 8 punktów procentowych. Klienci wyczuwają sztuczność. Frazy 'odkryj tajemnicę', 'luksusowe doznania' i 'holistyczne podejście do piękna' powtarzają się z mechaniczną regularnością.
Model z silną regularyzacją entropii działa inaczej. Nie nadużywa dyskursywnych markerów. Nie wciska list wypunktowanych tam, gdzie nie są potrzebne. Używa średników, pauz i złożonych struktur zdaniowych z częstotliwością zbliżoną do ludzkiego copywritera. W testach opisanych w badaniu, model z lambda 5,0 osiąga distinct-4 na poziomie 0,803, co oznacza 185-procentową poprawę różnorodności 4-gramów względem modelu bazowego. Powtarzalność spada o 78 procent. Słownictwo jest o 27 procent bogatsze.
W praktyce oznacza to, że trzyosobowy zespół może wygenerować 40 wariantów newslettera, z których 35 przechodzi ludzką korektę bez większych zmian, a nie 15, jak przy standardowym modelu. Czas produkcji kampanii spada z pięciu do dwóch dni roboczych.
Korzyści i opłacalność: twarde liczby zamiast obietnic
Z mojego doświadczenia z sześciu wdrożeń narzędzi AI w działach marketingu, największym marnotrawstwem budżetu nie jest cena licencji, tylko koszt ludzkiej korekty tekstów, które i tak brzmią sztucznie. Przy stawce 120 złotych za godzinę pracy copywritera-korektora i średnim czasie 45 minut na poprawę jednego dłuższego tekstu wygenerowanego przez standardowy model, koszt korekty 100 tekstów miesięcznie wynosi 9 tysięcy złotych.
Model z regularyzacją entropii skraca ten czas do około 15 minut na tekst, bo poprawki dotyczą głównie faktów i tonu marki, a nie struktury językowej. Przy tej samej skali to 3 tysiące złotych miesięcznie, czyli 72 tysiące złotych oszczędności rocznie na samych kosztach korekty. Do tego dochodzi uniknięcie ryzyka oznaczenia treści przez detektory AI, co przy algorytmach Google coraz częściej wpływa na pozycjonowanie. Jedna duża agencja content marketingowa, z którą rozmawiałem w styczniu, podała, że po przejściu na bardziej zróżnicowane stylistycznie modele odzyskała średnio 12 procent ruchu organicznego w ciągu trzech miesięcy.
Od czego zacząć: pilotaż, a nie rewolucja
Nie polecam od razu przestawiać całej produkcji contentu na model z regularyzacją entropii. To technologia, która wymaga własnego treningu, a nie gotowego API. Jeśli Twój zespół nie ma kompetencji ML-owych, warto poczekać na komercyjne wdrożenia. Jeśli ma, zacznij od próbki 50 tekstów w jednym formacie, na przykład opisów produktów dla jednej kategorii w e-commerce. Mierz distinct-4, powtarzalność i, co najważniejsze, wskaźnik akceptacji przez ludzkiego redaktora przed i po zmianie modelu. Dopiero gdy zobaczysz 30-procentową poprawę w czasie korekty, skaluj na inne formaty.
Pamiętaj też o zasadzie kontrolnego natężenia z badania Mahapatry. Zbyt słaba interwencja pogarsza sprawę. Jeśli nie możesz trenować z lambda 5,0, lepiej zostań przy obecnym rozwiązaniu i zainwestuj w lepszy brief kreatywny dla copywriterów.
- 72 000 zł rocznie oszczędności na korekcie przy 100 tekstach miesięcznie
- 78% niższa powtarzalność fraz względem standardowych modeli
- 12% odzyskanego ruchu organicznego po eliminacji wzorców AI
- 185% wyższa różnorodność 4-gramów (distinct-4) w generowanych tekstach
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: From Context Shift to Stylistic Collapse: Why Training Objectives Matter More Than Scale
Autorzy: Rohan Mahapatra
In modern LLMs, linguistic features function not as stylistic artifacts but as probes of probability mass, allocated under training alignment objectives. Language models trained with contemporary pipelines exhibit severe reshaping of linguistic features, leading to extreme language re-distributio...
arXiv: arxiv.org/abs/2605.28826
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}