
Wyobraź sobie, że zamiast tygodniami uczyć model językowy na klastrach GPU, liczysz optymalne parametry raz, jednym wzorem. Vincent Granville, naukowiec zajmujący się AI, twierdzi, że właśnie to zrobił. Jego architektura dla dużych modeli językowych omija głębokie sieci neuronowe i cały ten żmudny trening, znajdując globalne optimum funkcji straty w formie zamkniętej.
Pożegnanie z propagacją wsteczną
Współczesne duże modele językowe opierają się na głębokich sieciach neuronowych. Ich trening to proces iteracyjny: dane przepływają przez warstwy, obliczany jest błąd, a potem algorytm propagacji wstecznej aktualizuje miliony lub miliardy wag. Powtarza się to tysiące razy, pochłaniając ogromne ilości energii i czasu. Granville proponuje coś radykalnie innego.
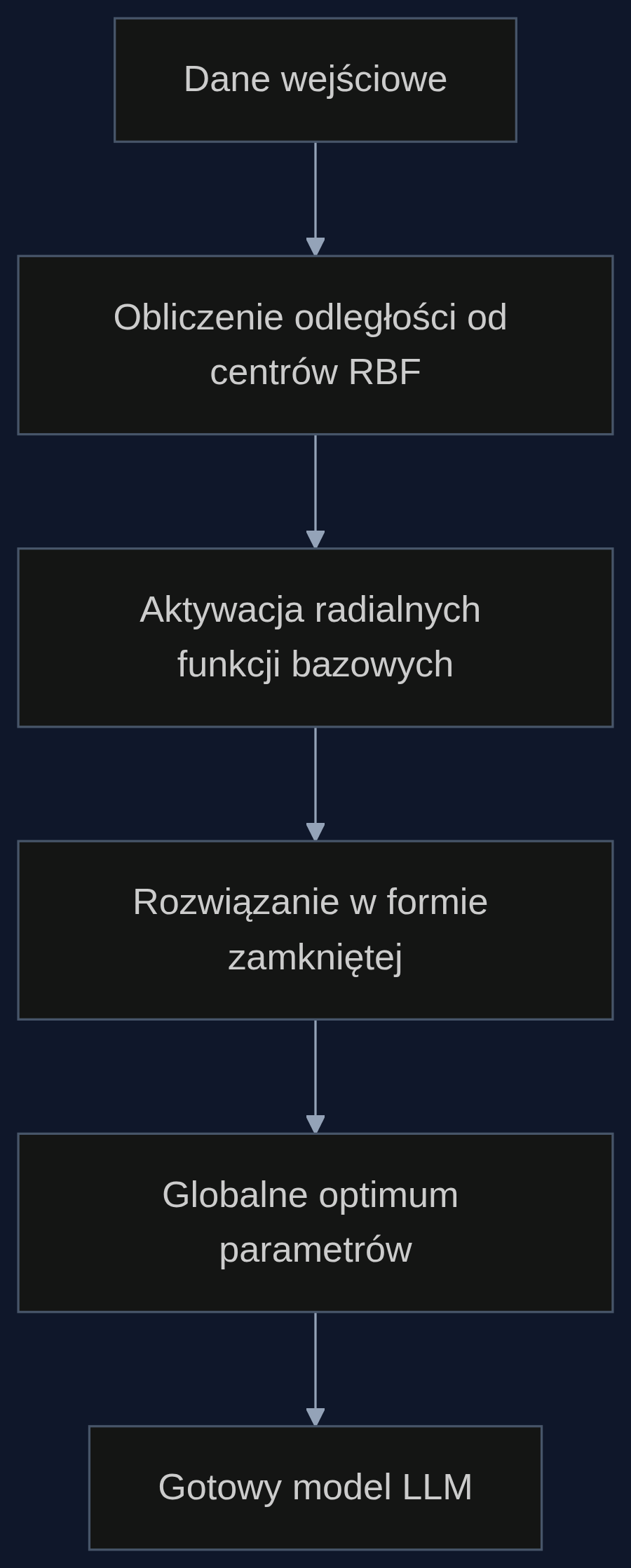
Jego model korzysta z sieci RBF (Radial Basis Function). To rodzaj sieci neuronowej, która zamiast mnożyć wejścia przez wagi w wielu warstwach, mierzy odległość wejścia od pewnych punktów centralnych i na tej podstawie podejmuje decyzje. Kluczowa różnica polega na tym, że dla tej architektury autor znalazł sposób na bezpośrednie wyliczenie najlepszych możliwych parametrów. Żadnych iteracji, żadnego ryzyka utknięcia w lokalnym minimum. Jeden wzór i gotowe.
Chiński trop i niezależne odkrycie
W swojej pracy Granville przyznaje, że nie jest osamotniony w myśleniu o sieciach RBF jako alternatywie dla głębokiego uczenia. Pisze: 'Bardzo niedawno chińscy naukowcy wykazali znaczące zainteresowanie modelem zwanym siecią RBF jako zamiennikiem dla standardowych DNN, oferującym zwiększoną wyjaśnialność i wyższą dokładność'. Jego własne badania doprowadziły go do bardzo podobnej maszynerii matematycznej.
Zbieżność ta jest ciekawa, bo sugeruje, że nie jest to tylko egzotyczny pomysł pojedynczego badacza. Równoległe prace w różnych częściach świata, zmierzające w tym samym kierunku, mogą oznaczać, że ograniczenia dzisiejszych transformerów stają się na tyle dotkliwe, że szukanie fundamentalnie innych rozwiązań przestaje być teoretyczną ciekawostką. Granville wyjaśnia: 'Okazuje się, że mój nowy model, odkryty niezależnie, opiera się na dokładnie tym samym mechanizmie. Ale z istotnym zwrotem akcji: nie potrzebuje DNN, ponieważ znajduje globalne optimum funkcji straty w formie zamkniętej, w jednej iteracji, eliminując żmudny etap treningu'.
Bardzo niedawno chińscy naukowcy wykazali znaczące zainteresowanie modelem zwanym siecią RBF jako zamiennikiem dla standardowych DNN, oferującym zwiększoną wyjaśnialność i wyższą dokładność.
Vincent Granville
LLMs Without Deep Neural Networks: New Architecture, Benefits and Case Study
Co to właściwie znaczy 'w formie zamkniętej'?
W uczeniu maszynowym standardem jest poszukiwanie rozwiązania metodą prób i błędów. Algorytm robi mały krok, sprawdza czy błąd zmalał, robi kolejny krok. To jak szukanie najniższego punktu w górach we mgle - możesz zejść do doliny, ale nie wiesz, czy za następnym grzbietem nie ma głębszej. Rozwiązanie w formie zamkniętej to jak posiadanie mapy z dokładnymi współrzędnymi najniższego punktu. Podstawiasz liczby do wzoru i masz pewność, że to globalne minimum.
W praktyce oznacza to, że zamiast uruchamiać trening na setkach czy tysiącach GPU przez wiele dni, obliczasz parametry modelu w jednym przebiegu. Dla modeli językowych, gdzie koszt treningu idzie w miliony dolarów, a ślad węglowy jest coraz częściej krytykowany, taka zmiana miałaby znaczenie nie tylko naukowe, ale i ekonomiczne.
Wyjaśnialność zamiast czarnej skrzynki
Jednym z największych problemów dzisiejszych LLM-ów jest to, że nikt do końca nie rozumie, dlaczego model wygenerował akurat taką odpowiedź. Miliardy parametrów tworzą czarną skrzynkę, której działania nie da się prześledzić krok po kroku. Sieci RBF mają tu naturalną przewagę. Ich architektura, oparta na odległościach od centrów, jest z natury bardziej przejrzysta.
Możesz spojrzeć na dane wejściowe i zobaczyć, do którego centrum są najbliżej, a tym samym która część modelu miała największy wpływ na wynik. W zastosowaniach regulowanych - medycynie, prawie, finansach - to nie jest fanaberia, tylko wymóg. Modele, których decyzji nie da się wyjaśnić, po prostu nie przechodzą audytów zgodności.
Czy to już działa?
Artykuł Granville'a ma charakter wysokopoziomowego przeglądu i studium przypadku. Nie znajdziemy w nim jeszcze pełnoskalowego modelu konkurującego z GPT-4 czy Claude. Autor przedstawia matematyczne podstawy i wstępne wyniki, które sugerują, że metoda może osiągać wyższą dokładność niż tradycyjne podejścia. To obietnica, nie gotowy produkt.
Mimo to warto na nią spojrzeć poważnie. Historia technologii zna przypadki, gdy fundamentalnie inne podejście wypierało dominujący paradygmat nie dlatego, że było dopracowane, ale dlatego, że omijało jego wrodzone ograniczenia. Sieci RBF nie zastąpią jutro transformerów w ChatGPT, ale jeśli problem wyjaśnialności i kosztów treningu będzie narastał, kierunek wskazany przez Granville'a i chińskich badaczy może okazać się czymś więcej niż akademicką ciekawostką.
- Nowa architektura LLM oparta na sieciach RBF zamiast głębokich sieci neuronowych
- Globalne optimum funkcji straty wyliczane bezpośrednio, w jednym kroku, bez iteracyjnego treningu
- Zwiększona wyjaśnialność modelu, kluczowa w branżach regulowanych
- Zbieżność z niezależnymi badaniami chińskich naukowców nad sieciami RBF
Praktyczne zastosowania
Aby lepiej zrozumieć opisywaną innowację, przygotowaliśmy cztery przykłady praktycznego zastosowania tej technologii w różnych branżach:




Podsumowanie
Proponowana architektura może znaleźć zastosowanie wszędzie tam, gdzie koszt treningu i brak wyjaśnialności są dziś blokerami. W medycynie, gdzie modele wspomagają diagnostykę, możliwość prześledzenia dlaczego system wskazał konkretną chorobę jest wymogiem regulacyjnym, a nie opcją. W sektorze finansowym, przy ocenie ryzyka kredytowego czy wykrywaniu nadużyć, audytorzy muszą rozumieć przesłanki decyzji modelu. Wreszcie, sama eliminacja żmudnego treningu obniża próg wejścia dla mniejszych firm, które nie dysponują budżetami na kilkumiesięczne obliczenia na klastrach GPU.
Metryka artykułu źródłowego
Tytuł oryginalny: LLMs Without Deep Neural Networks: New Architecture, Benefits and Case Study
Autorzy: Vincent Granville
Data publikacji: 1 czerwca 2026
arXiv: arxiv.org/abs/2605.30385
Napisanie tego artykułu zostało wspomagane przez sztuczną inteligencję. Treść opiera się na oryginalnym artykule naukowym, a jej dokładność została zweryfikowana automatycznie.