

Wyobraź sobie, że Twój zespół przygotowuje linię obrony w głośnym sporze patentowym. Wdrażacie system AI, który przeszukuje publiczne bazy orzeczeń, łącząc je z wewnętrznymi notatkami. System działa bez zarzutu, ale każde zapytanie do zewnętrznej bazy jest jak rzucany cień. Przeciwnik, obserwując tylko te zapytania, może złożyć z nich obraz Waszej strategii. To nie fikcja. To efekt mozaiki, który właśnie został precyzyjnie zmierzony i okiełznany.
Problem, o którym nie mówi się na konferencjach LegalTech
Widziałem to na własne oczy podczas audytu w jednej z warszawskich kancelarii. Młodszy associate testował narzędzie do researchu, wrzucając do niego fragmenty umowy joint venture. Narzędzie, chcąc znaleźć analogiczne klauzule w orzecznictwie, odpaliło serię zapytań do publicznych baz. Z pozoru niewinne frazy. Ale gdyby ktoś je zebrał i przeanalizował, zobaczyłby nie tylko przedmiot sporu, ale też słabe punkty konstrukcji prawnej, którą kancelaria właśnie budowała.
Badanie MosaicLeaks pokazuje, że to nie jest przypadek. Gdy agent AI łączy prywatne dokumenty z publicznym internetem, przeciwnik obserwujący same zapytania jest w stanie wywnioskować intencję badawczą, odpowiedzi na prywatne pytania, a nawet konkretne twierdzenia z wewnętrznych dokumentów. To trzy poziomy wycieku. Standardowe promptowanie 'nie zdradzaj tajemnic' trochę pomaga, ale nie likwiduje problemu. Co gorsza, jeśli wytrenujemy agenta tylko pod kątem skuteczności researchu, będzie zdradzał jeszcze więcej.
Technologia, która uczy agenta milczeć strategicznie
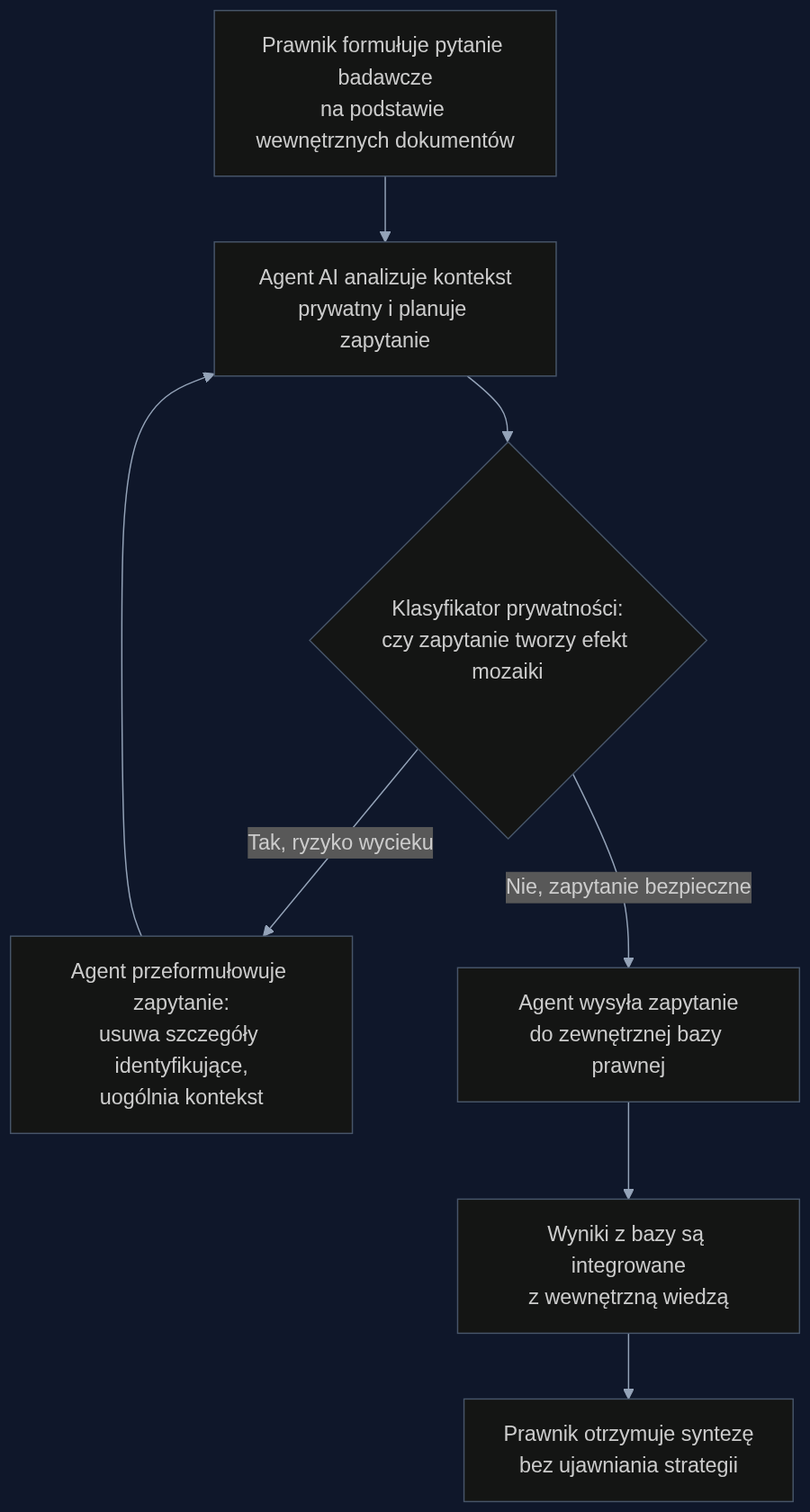
Zespół Gurunga i współpracowników nie tylko nazwał problem. Stworzył też ramę do jego rozwiązania - Privacy-Aware Deep Research (PA-DR). To mechanizm, który uczy agenta balansowania między skutecznością a prywatnością na poziomie każdego pojedynczego zapytania.
Działa to tak: agent planuje zapytanie do zewnętrznej bazy. Zanim je wyśle, w tle pracuje klasyfikator prywatności. On ocenia, czy to konkretne zapytanie, w połączeniu z poprzednimi, nie tworzy efektu mozaiki. Jeśli ryzyko jest zbyt wysokie, agent dostaje sygnał zwrotny, żeby przeformułować pytanie - na tyle ogólnie, by nie zdradzić kontekstu, ale na tyle precyzyjnie, by dostać użyteczne wyniki. To nie jest prosty filtr słów kluczowych. To model, który rozumie semantyczny związek między wewnętrznym dokumentem a formułowanym zapytaniem.
W liczbach wygląda to obiecująco. Bazowe modele, bez żadnych zabezpieczeń, przy skuteczności researchu na poziomie 48,7% zdradzały pełną informację w 34% przypadków. PA-DR podnosi skuteczność do 58,7%, a wyciek pełnej informacji tnie do 9,9%. To nie jest usunięcie ryzyka do zera. Ale to redukcja o ponad 70%, przy jednoczesnym wzroście jakości wyników. Dla partnera zarządzającego to sygnał: można mieć i szybkość AI, i kontrolę nad tajemnicą zawodową.
Scenariusz: przygotowanie do arbitrażu inwestycyjnego
Weźmy konkret. Kancelaria przygotowuje się do arbitrażu przeciwko państwu na podstawie traktatu BIT. Wewnętrzny dokument to analiza prawna wskazująca, że kluczowym argumentem będzie naruszenie klauzuli 'fair and equitable treatment' poprzez konkretną zmianę regulacji podatkowej z 2022 roku.
Asystent AI, bez zabezpieczeń PA-DR, mógłby wysłać do zewnętrznej bazy zapytania typu: 'orzeczenia ICSID naruszenie FET zmiana podatkowa sektor wydobywczy 2022'. To już jest praktycznie streszczenie strategii. Adwersarz widzący ciąg takich zapytań z jednego IP wie, gdzie szukać słabych punktów.
Ten sam agent z włączonym PA-DR rozbije to na serię bezpieczniejszych kroków. Najpierw zapyta ogólnie o 'standard FET w orzecznictwie ICSID'. Potem, po analizie wyników, o 'interpretację pośredniego wywłaszczenia'. Dopiero na końcu, po kilku rundach i z zachowaniem odstępów czasowych, sięgnie po wątek podatkowy, ale sformułuje go jako 'zmiany fiskalne a ochrona inwestycji', bez wskazywania roku i sektora. Kontekst pozostaje w wewnętrznej bazie. Na zewnątrz widać tylko rozproszone, ogólne zapytania, które mógłby zadać każdy doktorant prawa międzynarodowego.
Co to znaczy dla budżetu i zgodności
Z mojego doświadczenia z wdrożeń w sektorze prawnym wynika, że największym hamulcowym dla AI nie jest cena licencji, tylko strach przed incydentem. Jeden wyciek strategii procesowej może kosztować kancelarię nie tylko sprawę wartą kilkadziesiąt milionów, ale i utratę klientów, którzy oczekują absolutnej dyskrecji.
PA-DR adresuje ten strach w sposób mierzalny. Dla działu compliance oznacza to konkretny parametr do raportowania: 'ryzyko wycieku pełnej informacji poniżej 10% przy skuteczności researchu powyżej 58%'. To nie jest marketingowy slogan, tylko twarda metryka z benchmarku. Można to wpisać do umowy z dostawcą narzędzia AI jako KPI.
Jeśli chodzi o RODO i tajemnicę adwokacką, mechanizm ten wpisuje się w zasadę privacy by design. Agent nie wysyła na zewnątrz surowych danych z wewnętrznych dokumentów, tylko przetworzone, zanonimizowane zapytania. Sam klasyfikator prywatności może być audytowany przez zewnętrzną firmę bezpieczeństwa. To zmienia dyskusję z zarządem z 'czy AI jest bezpieczne?' na 'jak mierzymy i ograniczamy ryzyko resztkowe?'.
Od czego zacząć jutro rano
Nie rzucałbym się od razu na wdrażanie pełnego PA-DR we wszystkich sprawach. To dojrzała koncepcja badawcza, ale jej komercyjne implementacje dopiero powstają. Natomiast już dziś można zrobić trzy rzeczy.
Po pierwsze, przeprowadzić audyt obecnego użycia narzędzi researchowych. Poproś zespół IT o logi zapytań do zewnętrznych baz z ostatniego miesiąca. Przejrzyj je pod kątem efektu mozaiki. Założę się, że znajdziesz kilka przypadków, gdzie ciąg zapytań opowiada jasną historię o prowadzonej sprawie.
Po drugie, wprowadź politykę 'bezpiecznego promptowania' dla prawników korzystających z AI. Zamiast 'znajdź orzeczenia podobne do naszej sprawy X', niech piszą 'znajdź orzeczenia dotyczące zagadnienia Y w kontekście Z', celowo pomijając szczegóły identyfikujące klienta i strategię. To zero-kosztowa proteza do czasu wdrożenia automatycznych zabezpieczeń.
Po trzecie, rozmawiając z dostawcami LegalTech, pytaj ich wprost o mechanizmy prywatności na poziomie zapytań. Jeśli odpowiedzą, że 'wszystko jest szyfrowane', to za mało. Szyfrowanie chroni przed podsłuchem na łączu, nie przed analizą semantyczną zapytań przez platformę czy wyciekiem do logów. Pytaj o klasyfikatory prywatności, o gęste przypisywanie odpowiedzialności (dense credit assignment), o metryki wycieku. To są konkretne terminy z tej publikacji. Użyj ich. Zobaczysz, kto się zaczerwieni.
- Redukcja wycieku pełnej informacji z 34% do poniżej 10%
- Wzrost skuteczności researchu z 48,7% do 58,7%
- Mierzalne KPI dla zgodności z RODO i tajemnicą adwokacką
- Eliminacja ryzyka ujawnienia strategii przez efekt mozaiki zapytań
- Możliwość bezpiecznego łączenia akt sprawy z zewnętrznymi bazami orzeczeń
- Audytowalny mechanizm privacy by design, a nie tylko szyfrowanie transmisji
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: MosaicLeaks:Privacy Risks in Querying-in-the-Open for Deep Research Agents
Autorzy: Alexander Gurung, Spandana Gella, Alexandre Drouin, Issam H. Laradji, Perouz Taslakian i in.
Deep research agents increasingly combine private local documents with external tools like web retrieval, creating a privacy risk: an agent's external queries may leak sensitive information from its local context. This risk is amplified by the mosaic effect, where individual queries may appear ha...
arXiv: arxiv.org/abs/2605.30727
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}