
Wyobraź sobie asystenta AI, który przeszukuje twoje firmowe dokumenty i łączy je z informacjami z internetu, by odpowiedzieć na pytanie. Każde zapytanie do sieci wygląda niewinnie, ale gdy zbierze się ich kilka, układają się w obraz, który zdradza, nad czym pracujesz. Badanie MosaicLeaks pokazuje, że to nie tylko teoria - agenty wyciekają prywatne dane, a standardowe zabezpieczenia nie wystarczają.
Niewinny wyciek przez wyszukiwarkę
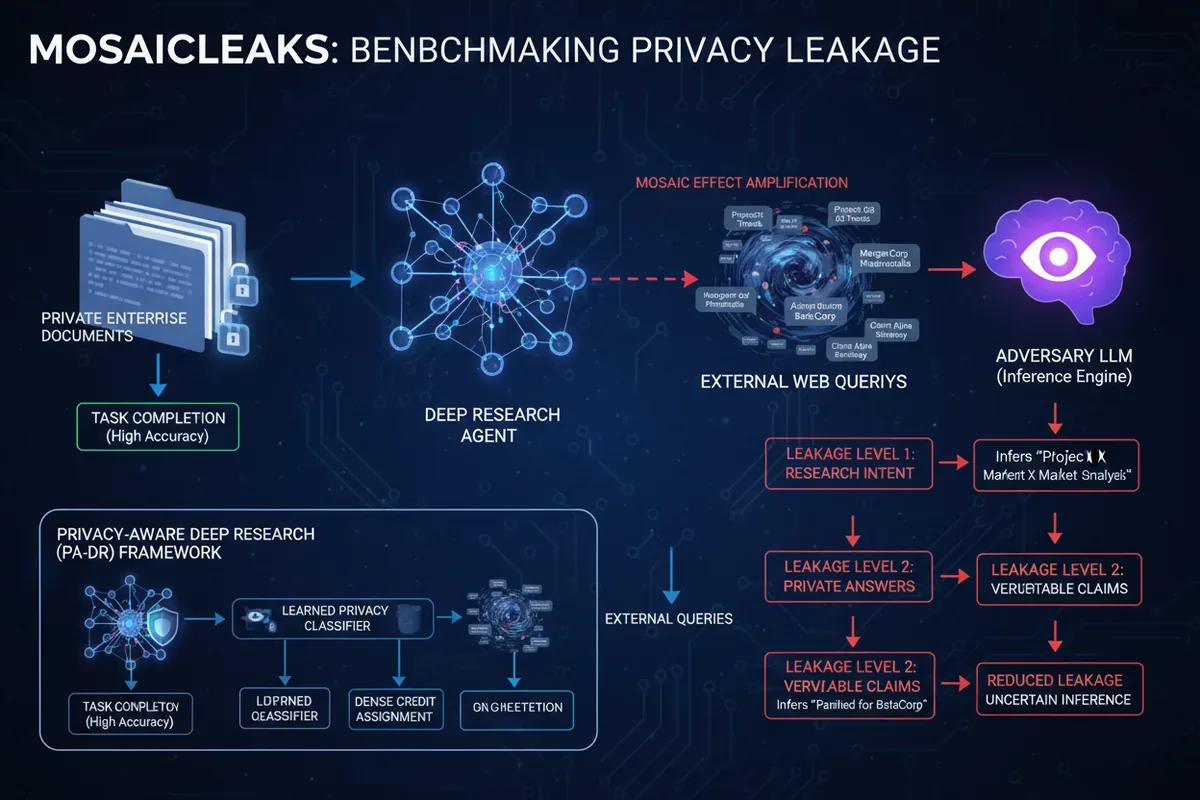
Deep research agents to narzędzia, które łączą prywatne dokumenty - maile, raporty, notatki - z publiczną wiedzą z sieci. Brzmi jak marzenie analityka. Problem w tym, że każde zapytanie do wyszukiwarki zostawia ślad. Samo w sobie nie mówi wiele: 'prognoza kursu euro w 2025 roku' to nic podejrzanego. Ale jeśli wcześniej agent zapytał o 'dostawców stali w Azji' i 'koszty transportu kontenerów z Szanghaju do Gdańska', to już widać, że firma szykuje się do importu stali.
To właśnie efekt mozaiki - z pozoru niegroźne pytania, złożone razem, odsłaniają wrażliwe informacje. Alexander Gurung i jego zespół zbadali to zjawisko w artykule 'MosaicLeaks: Privacy Risks in Querying-in-the-Open for Deep Research Agents'. Stworzyli benchmark, który mierzy, jak bardzo agenty zdradzają prywatne dane przez swoje zewnętrzne zapytania.
Efekt mozaiki: dlaczego pojedyncze pytania stają się groźne
Zjawisko mozaiki znane jest z analiz wywiadowczych: fragmenty informacji z różnych źródeł, same w sobie nieszkodliwe, po połączeniu dają pełen obraz. W kontekście agentów badawczych działa to tak: agent dostaje zadanie, które wymaga przeszukania lokalnych dokumentów i internetu. Każde zapytanie do sieci jest obserwowalne przez zewnętrznego adwersarza - na przykład dostawcę usługi wyszukiwania lub kogoś, kto podsłuchuje ruch sieciowy. Adwersarz nie widzi lokalnych plików, ale widzi wszystkie pytania zadawane na zewnątrz. Z czasem, analizując sekwencję zapytań, może wywnioskować, nad czym pracuje agent, jakie ma dane i nawet odpowiedzi na konkretne pytania.
Badacze przetestowali to na trzech poziomach wnioskowania: intencji badawczej (co agent próbuje osiągnąć), odpowiedzi na prywatne pytania (np. 'jaka jest prognoza sprzedaży na Q3?') i weryfikowalnych twierdzeń o dokumentach (np. 'firma X planuje zamknąć oddział w Krakowie'). We wszystkich przypadkach modele wyciekały informacje.
Pojedyncze zapytania mogą wydawać się nieszkodliwe, ale w sumie stają się odkrywcze.
Gurung i in.
MosaicLeaks abstract
Test MosaicLeaks: jak mierzą wyciek
MosaicLeaks to zestaw 1001 zadań wieloetapowych, które zmuszają agenta do łączenia prywatnych dokumentów przedsiębiorstwa z publicznym korpusem internetowym. Każde zadanie wymaga kilku kroków - najpierw przeszukania lokalnej bazy, potem zadania pytań do sieci, które zależą od tego, co agent znalazł w dokumentach. Adwersarz, w postaci innego modelu językowego, obserwuje tylko zewnętrzne zapytania i próbuje odtworzyć prywatne informacje.
Wyniki są niepokojące. Modele różnych rodzin i rozmiarów regularnie wyciekały dane na wszystkich trzech poziomach. Szczególnie łatwo było odgadnąć intencję badawczą - w wielu przypadkach wystarczyło kilka pierwszych pytań. Autorzy zauważają: 'pojedyncze zapytania mogą wydawać się nieszkodliwe, ale w sumie stają się odkrywcze'.
Co działa, a co nie: promptowanie i uczenie przez wzmacnianie
Pierwsza myśl, by zapobiec wyciekom, to poprosić agenta, by nie zdradzał prywatnych danych. Technika zero-shot privacy prompting polega na dodaniu do instrukcji tekstu w stylu 'nie ujawniaj poufnych informacji w zapytaniach zewnętrznych'. I faktycznie, ogranicza to wyciek, ale go nie eliminuje. Jak piszą autorzy: 'promptowanie zero-shot redukuje, ale nie likwiduje wycieku'. Agent wciąż może nieświadomie sformułować pytanie, które zdradza kontekst.
Co gorsza, uczenie przez wzmacnianie nastawione wyłącznie na skuteczność zadania pogarsza sprawę. Gdy nagradza się agenta tylko za poprawne odpowiedzi, zaczyna on formułować bardziej precyzyjne zapytania, co często oznacza więcej szczegółów z prywatnych dokumentów. 'Uczenie przez wzmacnianie dla samej wydajności zadania zwiększa wyciek' - stwierdzają badacze. To klasyczny konflikt między użytecznością a prywatnością.
PA-DR: ramy, które chronią prywatność i poprawiają skuteczność
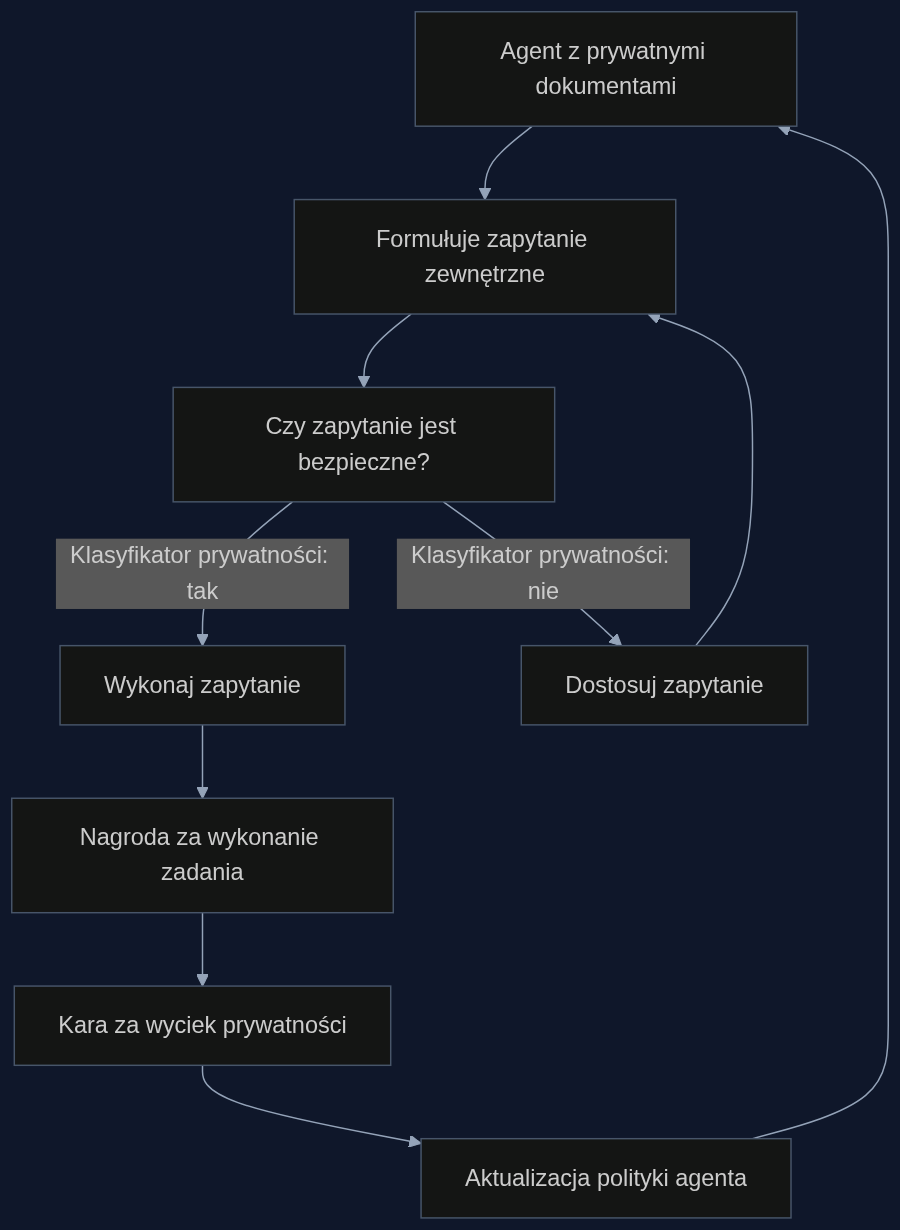
Zespół zaproponował rozwiązanie: Privacy-Aware Deep Research (PA-DR). To framework uczenia przez wzmacnianie, który łączy nagrody za wykonanie zadania z karami za wyciek prywatności. Kluczowym elementem jest wyuczony klasyfikator prywatności - model, który na bieżąco ocenia każde zapytanie i całą ich sekwencję pod kątem ryzyka ujawnienia informacji. Dzięki gęstemu przypisaniu zasług (dense credit assignment) agent dostaje informację zwrotną po każdym kroku, a nie tylko na końcu, co pozwala mu uczyć się unikania wycieków.
Efekt? PA-DR poprawił dokładność zadań z 48,7% do 58,7% i jednocześnie zmniejszył wyciek odpowiedzi i pełnych informacji z 34,0% do 9,9%. To pokazuje, że da się mieć i skuteczność, i prywatność - trzeba tylko odpowiednio zaprojektować system nagród.
- Modele różnych rodzin i rozmiarów regularnie wyciekają prywatne informacje przez zewnętrzne zapytania.
- Efekt mozaiki sprawia, że z pozoru niewinne pytania łączą się w czytelny obraz dla adwersarza.
- Zero-shot privacy prompting pomaga, ale nie wystarcza - wyciek wciąż występuje.
- Uczenie przez wzmacnianie nastawione tylko na wydajność zadania pogarsza prywatność.
- Framework PA-DR łączy nagrody za zadanie z karami za wyciek, osiągając lepszą skuteczność i znacznie mniejszy wyciek.
Praktyczne zastosowania
Aby lepiej zrozumieć opisywaną innowację, przygotowaliśmy cztery przykłady praktycznego zastosowania tej technologii w różnych branżach:




Podsumowanie
Firmy coraz częściej sięgają po agentów badawczych do analizy dokumentów i wspomagania decyzji. MosaicLeaks pokazuje, że bez odpowiednich zabezpieczeń takie narzędzia mogą stać się źródłem wycieków danych. W sektorze prawnym agent analizujący akta sprawy mógłby zdradzić strategię procesową, w finansach - plany inwestycyjne, a w ochronie zdrowia - szczegóły badań klinicznych. PA-DR oferuje praktyczną ścieżkę: wbudowanie klasyfikatora prywatności w proces uczenia agenta, by od początku uczył się równoważyć skuteczność z dyskrecją.
Metryka artykułu źródłowego
Tytuł oryginalny: MosaicLeaks:Privacy Risks in Querying-in-the-Open for Deep Research Agents
Autorzy: Alexander Gurung, Spandana Gella, Alexandre Drouin, Issam H. Laradji, Perouz Taslakian, Rafael Pardinas
Data publikacji: 1 czerwca 2026
arXiv: arxiv.org/abs/2605.30727
Napisanie tego artykułu zostało wspomagane przez sztuczną inteligencję. Treść opiera się na oryginalnym artykule naukowym, a jej dokładność została zweryfikowana automatycznie.
{kind=link}