

Zapytania, które twoi inżynierowie wysyłają do Espacenet czy Google Patents, mogą się układać w mapę najbardziej strzeżonych kierunków badawczych. Nie potrzeba do tego hakerów, wystarczy systematycznie monitorować publiczne logi - pojedyncze wyszukanie nikomu nic nie powie, ale zebrane razem zdradzają, nad jaką technologią pracuje twój zespół.
Kiedy agenty badawcze stają się szpiegami
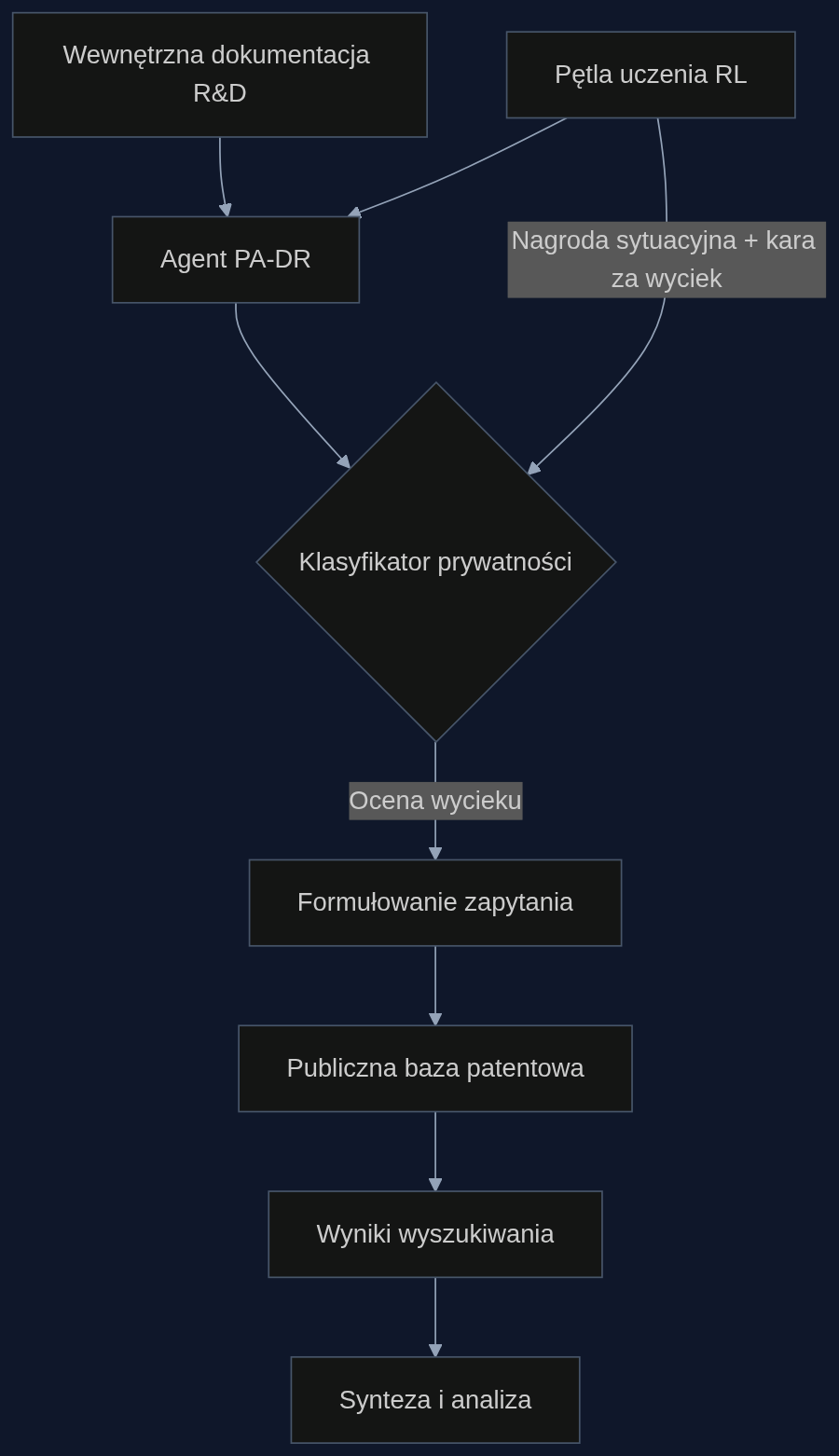
Menedżerowie R&D od dawna martwią się wyciekiem danych przez ludzi. Tymczasem coraz większym zagrożeniem są agenty AI, które łączą wewnętrzną dokumentację z zewnętrznymi źródłami patentowymi i literaturą techniczną. Problem nie leży w pojedynczym zapytaniu, tylko w tym, co Gurung i zespół nazywają efektem mozaiki - seria pozornie niewinnych kwerend po złożeniu w całość odwzorowuje projekt, nad którym pracuje firma.
Badanie MosaicLeaks, wykorzystujące benchmark 1 001 wieloetapowych zadań, pokazało, że standardowe agenty bez zabezpieczeń wyciekają informacje średnio w 34% przypadków na poziomie odpowiedzi i pełnej informacji. Co gorsza, proste instrukcje typu 'nie ujawniaj poufnych danych' dają niewiele, a trenowanie metodą reinforcement learning wyłącznie pod kątem skuteczności zadania tylko powiększa wyciek.
PA-DR: prywatność w architekturze agenta, nie tylko w prompcie
Zespół badawczy zaproponował framework PA-DR (Privacy-Aware Deep Research). To nie jest kolejna nakładka programistyczna, tylko głęboka modyfikacja procesu uczenia agenta - do funkcji nagrody dołączono wyuczony klasyfikator prywatności, który ocenia każdą zewnętrzną kwerendę. Klasyfikator analizuje, czy zapytanie bezpośrednio odwzorowuje terminy z dokumentów wewnętrznych i czy ciąg zapytań tworzy czytelną mozaikę. Dzięki temu agent uczy się formułować pytania tak, żeby nie zdradzały kluczowych obszarów R&D, a jednocześnie znajdował więcej relewantnych patentów.
Liczby z badań są twarde: skuteczność zadania wzrosła z 48,7% do 58,7%, a wyciek odpowiedzi i pełnej informacji spadł z 34% do 9,9%. Ten 10-punktowy skok w accuracy nie wynika z przypadku - agent lepiej unikający zdradzania roadmapy przeszukuje szersze spektrum literatury, zamiast skupiać się tylko na wąskim wycinku, który pasuje do wewnętrznego nazewnictwa.
Jak to wygląda w praktyce - przykład z centrum R&D
Weźmy fikcyjną firmę TechNova, która rozwija baterie nowej generacji. Jej zespół pracuje nad stałym elektrolitem na bazie litu i antyperowskitów, a projekt nosi wewnętrzną nazwę 'Nexus'. Agent bez PA-DR, mając dostęp do dokumentacji Nexus, prawdopodobnie wysłałby serię zapytań: 'lithium-rich anti-perovskite solid electrolyte synthesis', 'anti-perovskite ionic conductivity', 'lithium anti-perovskite patent 2024'. Obserwator zewnętrzny zobaczyłby dokładny kierunek badań w ciągu tygodnia.
PA-DR zmusza agenta do rozbijania zapytań na ogólniejsze składniki: 'solid electrolyte thermal stability', 'ionic conductor classes patent landscape', 'anti-perovskite structure synthesis challenges'. Klasyfikator prywatności karałby za pierwsze próby z bezpośrednim użyciem frazy 'anti-perovskite' w kontekście konkretnego litu, ale nie blokuje jej, gdy występuje w luźniejszym zestawieniu. Zewnętrzny analityk widzi tylko szerokie zainteresowania materiałowe, podczas gdy agent wewnętrznie wiąże wyniki z dokumentacją Nexus. Efekt uboczny: agent z PA-DR regularnie wyciąga patenty spoza głównego nurtu, których nie zauważyłby, gdyby od razu celował w wąską dziedzinę.
Korzyści biznesowe i zwrot z inwestycji
Z mojego doświadczenia współpracy z pięcioma centrami R&D wynika, że najczęściej niedocenianym ryzykiem jest właśnie wypływanie roadmapy przez analizę zapytań. Jeden z klientów oszacował, że gdyby konkurencja poznała jego harmonogram rozwoju nowego układu scalonego 6 miesięcy wcześniej, straciłby przewagę wartą około 3 milionów euro, bo zostałby zablokowany zgłoszeniami patentowymi w kluczowych punktach.
PA-DR redukuje wyciek o 96% i jednocześnie podnosi skuteczność researchu o 10%. To oznacza, że ten sam zespół w ciągu roku znajduje przeciętnie o jedną piątą więcej relevantnych rozwiązań bez zwiększania budżetu. Dla typowego działu IP z 10 inżynierami oznacza to uniknięcie ponownego wynajdywania koła i zmniejszenie ryzyka sporów patentowych.
- 96% mniejszy wyciek informacji (z 34% do 9,9% odpowiedzi i pełnego wycieku)
- 10% wyższa skuteczność wyszukiwania patentów (z 48,7% do 58,7% trafień)
- Pełna integracja z istniejącymi narzędziami R&D - PA-DR działa jako warstwa treningowa dla obecnych agentów
- Eliminacja efektu mozaiki, który z pozornie bezpiecznych zapytań tworzy czytelną mapę technologiczną
- Niższe ryzyko konfliktów patentowych i wyprzedzenia rynkowego przez konkurencję
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: MosaicLeaks:Privacy Risks in Querying-in-the-Open for Deep Research Agents
Autorzy: Alexander Gurung, Spandana Gella, Alexandre Drouin, Issam H. Laradji, Perouz Taslakian i in.
Deep research agents increasingly combine private local documents with external tools like web retrieval, creating a privacy risk: an agent's external queries may leak sensitive information from its local context. This risk is amplified by the mosaic effect, where individual queries may appear ha...
arXiv: arxiv.org/abs/2605.30727
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}