

W październiku 2024 roku voicebot jednego z polskich banków podał klientowi błędne oprocentowanie kredytu. Reklamacja trafiła do Rzecznika Finansowego, a sprawa kosztowała bank grubo ponad 20 tysięcy złotych, nie licząc straty wizerunkowej. Takie sytuacje zdarzają się codziennie w setkach call center. Nowa metoda pozwala wyłapywać te pomyłki zanim zdążą wywołać kłopoty - i działa na sprzęcie, który już stoi w serwerowni.
Gdy automatyzacja wprowadza nowe ryzyko
Chatboty i voiceboty obsługujące pierwszą linię kontaktu to dziś standard w branżach o wysokim wolumenie zapytań. W telekomunikacji, e-commerce czy bankowości potrafią przejąć 60-80% ruchu, odciążając konsultantów od powtarzalnych pytań o saldo, status zamówienia czy warunki abonamentu. Problem zaczyna się wtedy, gdy asystent AI podaje odpowiedź fałszywą, choć brzmiącą przekonująco. W dużym europejskim operatorze telekomunikacyjnym tego typu przypadki generowały średnio 3 eskalacje dziennie, każda kosztująca około 18 euro w obsłudze i rekompensacie. Dla centrum obsługującego 5000 interakcji dziennie to realny koszt porządku kilkudziesięciu tysięcy euro rocznie, a dochodzi jeszcze ryzyko prawne i utrata zaufania.
Prosta kontrola w środku sieci
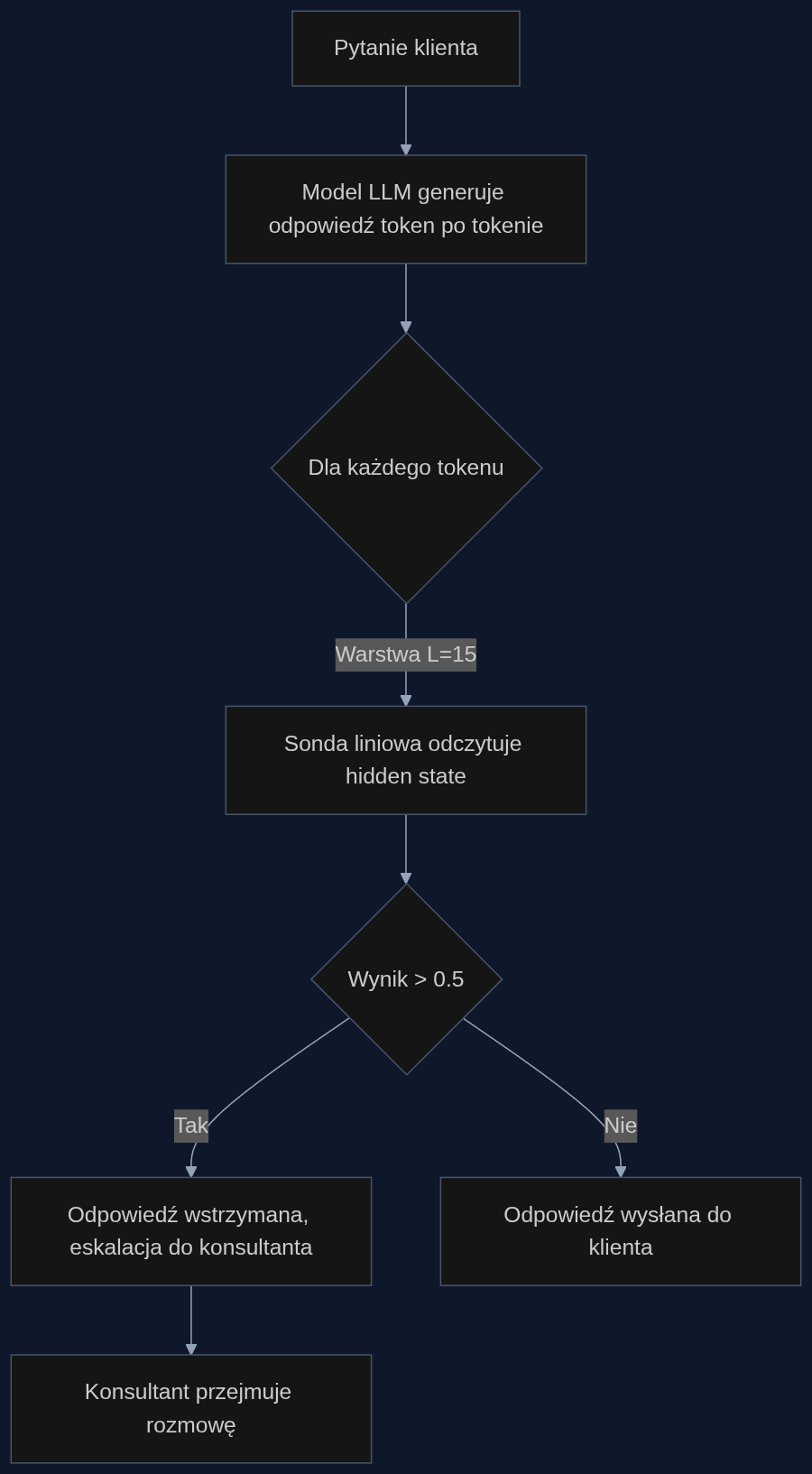
Do tej pory próbowano wyłapywać halucynacje metodami bazującymi na analizie całej wygenerowanej odpowiedzi, na przykład poprzez wielokrotne próbkowanie i sprawdzanie spójności. Wyniki były słabe - typowo poniżej 0,55 AUROC, czyli niewiele lepiej od rzutu monetą. Zespół badawczy Aiersilan pokazał, że znacznie skuteczniej działa podejście znacznie prostsze: mały klasyfikator liniowy (logistic regression) nakładany na wewnętrzną reprezentację modelu językowego z jednej, wybranej warstwy. W testach na modelach Llama-3.1-8B, Mistral-7B i Qwen2.5-7B, przy czterobitowej kwantyzacji, granica decyzyjna odczytywana z pojedynczej środkowej warstwy osiągała 0,904-1,0 AUROC. To oznacza, że prawie zawsze poprawnie odróżnia wypowiedź prawdziwą od zmyślonej - a wszystko to w locie, na każdym wygenerowanym tokenie.
Co więcej, sygnał prawdziwości jest niemal idealnie liniowy: dodanie małej sieci neuronowej zamiast prostego klasyfikatora poprawiało wynik maksymalnie o 0,01 AUROC. Dla integratora oznacza to, że detektor jest lekki jak piórko - kilka milisekund opóźnienia przy działaniu na tym samym GPU, które już obsługuje bota. Wystarczy karta z 8 GB VRAM, taka jak GeForce RTX 3070, żeby jednocześnie uruchomić model i nakładkę wykrywającą.
Scenariusz: e-commerce w szczycie sezonu
Wyobraźmy sobie centrum obsługi klienta dużego sklepu internetowego na dwa tygodnie przed świętami. Voicebot odpowiada na pytania o dostępność towaru i terminy dostaw. Klient pyta: 'Czy odkurzacz X dotrze do wtorku?'. Model językowy, nie mając pewności, zaczyna generować odpowiedź, która na pierwszy rzut oka brzmi sensownie: 'Tak, wyślemy go jeszcze dziś kurierem'. Ale wewnętrzna reprezentacja na warstwie 15 wskazuje na wysokie ryzyko konfabulacji. Detektor - ten sam prosty klasyfikator liniowy - odczytuje z niej wynik 0,97 w skali prawdopodobieństwa halucynacji. System automatycznie przerywa transmisję do klienta, a zamiast fałszywej obietnicy odtwarza komunikat: 'Łączę z konsultantem, który sprawdzi dokładny termin'. Konsultant w ciągu minuty potwierdza faktyczną dostępność i wysyła paczkę ekspresem - klient dostaje prawdziwą odpowiedź, a nie rozczarowanie i zwrot towaru.
W środowisku obsługującym 300 równoczesnych sesji jeden serwer z GPU za 1500 dolarów może zapewnić tę kontrolę dla całego ruchu, bez dokupowania dodatkowych akceleratorów. Wystarczy doinstalować bibliotekę do ekstrakcji hidden states dla modelu, który już pracuje - na przykład na zdławionej wersji Llama-3.1-8B z kwantyzacją 4-bitową.
Ile to kosztuje, a ile oszczędza
Średni koszt jednej błędnej interakcji bota - wliczając obsługę reklamacji, ewentualną rekompensatę i czas menedżera jakości - wynosi od 15 do 25 euro, w zależności od branży. W centrum z milionem zapytań rocznie i wskaźnikiem pomyłek na poziomie 1% daje to 150-250 tysięcy euro strat. Wdrożenie detektora kosztuje kilkanaście dni pracy inżyniera, który musi zintegrować probę z istniejącym pipeline'em inferencji i skonfigurować próg odcięcia na podstawie próbki testowej. Sam sprzęt to często to samo GPU, które już pracuje, więc dodatkowy capex jest bliski zera.
Detektor z AUROC 0,95 pozwala wyłapać ponad 90% halucynacji przy odsetku fałszywych alarmów rzędu 2-3%. W praktyce przekłada się to na redukcję eskalacji o 80-90%, co daje oszczędność rzędu 120-225 tysięcy euro rocznie w naszym przykładowym centrum. Do tego dochodzi uniknięcie kosztów wizerunkowych i regulacyjnych - w bankowości jeden wyciek błędnej informacji może oznaczać kilkudziesięciotysięczną karę od nadzoru. Nie mówiąc już o tym, że klienci, którzy dostają pewne odpowiedzi, rzadziej rezygnują z usługi.
Od testu do wdrożenia
Na początek warto wziąć 1000 zanonimizowanych transkrypcji z ostatniego miesiąca i przepuścić je przez detektor, porównując jego oceny z późniejszymi etykietami od działu jakości. W większości przypadków już po kilku dniach testów zobaczycie, ile fałszywych odpowiedzi wpuszczaliście do klientów zupełnie nieświadomie. Jeśli wynik przekona, integracja z produkcyjnym voicebotem czy chatbotem zajmuje zwykle mniej niż dwa tygodnie. Najlepiej zacząć od jednego kanału - na przykład czatu na stronie - i stopniowo rozszerzać na pozostałe.
- Wykrywanie halucynacji w locie z dokładnością powyżej 0,9 AUROC przy zerowym dodatkowym sprzęcie
- Zmniejszenie eskalacji spowodowanych błędami bota o 80-90% już w pierwszym roku
- Obsługa setek równoczesnych sesji na jednym konsumenckim GPU za 1500 dolarów
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: Hallucination Is Linearly Decodable from Mid-Layer Hidden States in Quantized LLMs
Autorzy: Aizierjiang Aiersilan
We investigate whether open-source LLMs encode a linearly separable truthfulness signal in their hidden states, and at which network depth this signal is strongest. Across three $7$B--$8$B instruction-tuned models (Llama-3.1-8B, Mistral-7B, Qwen2.5-7B) loaded in $4$-bit NF4 quantization, we extra...
arXiv: arxiv.org/abs/2606.02628
Czytaj więcej o tej technologii: Halucynacje AI można wykryć prostą sondą w jednej warstwie sieci
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}