

W 2023 roku system wspomagania decyzji klinicznych w jednym z amerykańskich szpitali zasugerował amputację kończyny u pacjenta z zaawansowaną cukrzycą. Późniejsza weryfikacja wykazała, że model AI powiązał wysoki poziom hemoglobiny glikowanej z ryzykiem sepsy w sposób czysto statystyczny – zignorował przy tym fakt, że pacjent miał rozrusznik serca, co zmieniało obraz kliniczny. Takie błędy logiczne nie są anomalią: wynikają z fundamentalnego ograniczenia sieci neuronowych, które opisano w najnowszych badaniach nad rozumowaniem sylogistycznym. Dla zarządzających placówkami medycznymi to sygnał, że skalowanie modeli nie wystarczy – potrzebna jest architektura łącząca dwa światy: uczenie maszynowe i symboliczną weryfikację reguł.
Sieć neuronowa nie nauczy się logiki – bez względu na ilość danych
Zespół Donga, Jamnik i Liò przeanalizował, dlaczego nadzorowane uczenie maszynowe nie opanowuje ścisłego rozumowania sylogistycznego. Dwa powody uderzają w samo sedno medycznych systemów AI. Po pierwsze, dane treningowe nie odróżniają wszystkich 24 typów poprawnych sylogizmów – model uczy się powierzchownych wzorców, a nie reguł. Po drugie, mapowanie typu end-to-end z przesłanek na wniosek tworzy sprzeczne cele treningowe między rozpoznawaniem wzorców a logicznym wnioskowaniem. Nawet Euler Net – sieć zaprojektowana specjalnie do zadań logicznych – nie osiągnęła rygoru rozumowania symbolicznego.
Przenosząc to na grunt szpitalny: model widzi związek między podwyższonym CRP a zakażeniem, ale nie rozumie, że jeśli pacjent przyjmuje leki immunosupresyjne, to ten związek może być pozorny. W eksperymencie z ChatGPT GPT-5 trafność odpowiedzi na zadania logiczne skakała od 40 do 100 procent w zależności od formy powierzchniowej zdań – a nawet przy idealnej skuteczności wyjaśnienia były błędne. To dokładnie ten sam mechanizm, który w medycynie prowadzi do halucynacji.
Hybryda, która sprawdza samej sobie – moduł logiczny jako kontroler jakości
Rozwiązanie, które wyrasta z tych badań, nie odrzuca sieci neuronowych – dodaje im drugi obieg. Architektura hybrydowa składa się z dwóch komponentów: modelu predykcyjnego (np. transformer analizujący obrazy, EKG czy historię choroby) oraz modułu weryfikacji logicznej opartego na ontologiach medycznych i regułach wnioskowania. Moduł ten zawiera bazy wiedzy takie jak SNOMED CT, LOINC oraz reguły kliniczne z wytycznych towarzystw naukowych. Gdy AI wysuwa sugestię – na przykład podejrzenie ostrej białaczki na podstawie morfologii – moduł logiczny sprawdza, czy diagnoza nie koliduje z wiekiem pacjenta, wynikami badań genetycznych, przyjmowanymi lekami lub historią chorób przewlekłych.
Menedżerowie znający pilotaże wdrożeń systemów CDS wiedzą, że największy opór lekarzy budzi właśnie brak transparentności. Hybryda adresuje to bezpośrednio: w momencie wykrycia niespójności generuje czytelny komunikat – np. “podejrzenie sepsy nie znajduje potwierdzenia przy wartościach prokalcytoniny poniżej 0,25 ng/ml i braku źródła zakażenia w obrazowaniu”. To nie jest czarna skrzynka, tylko audytowalna ścieżka decyzyjna.
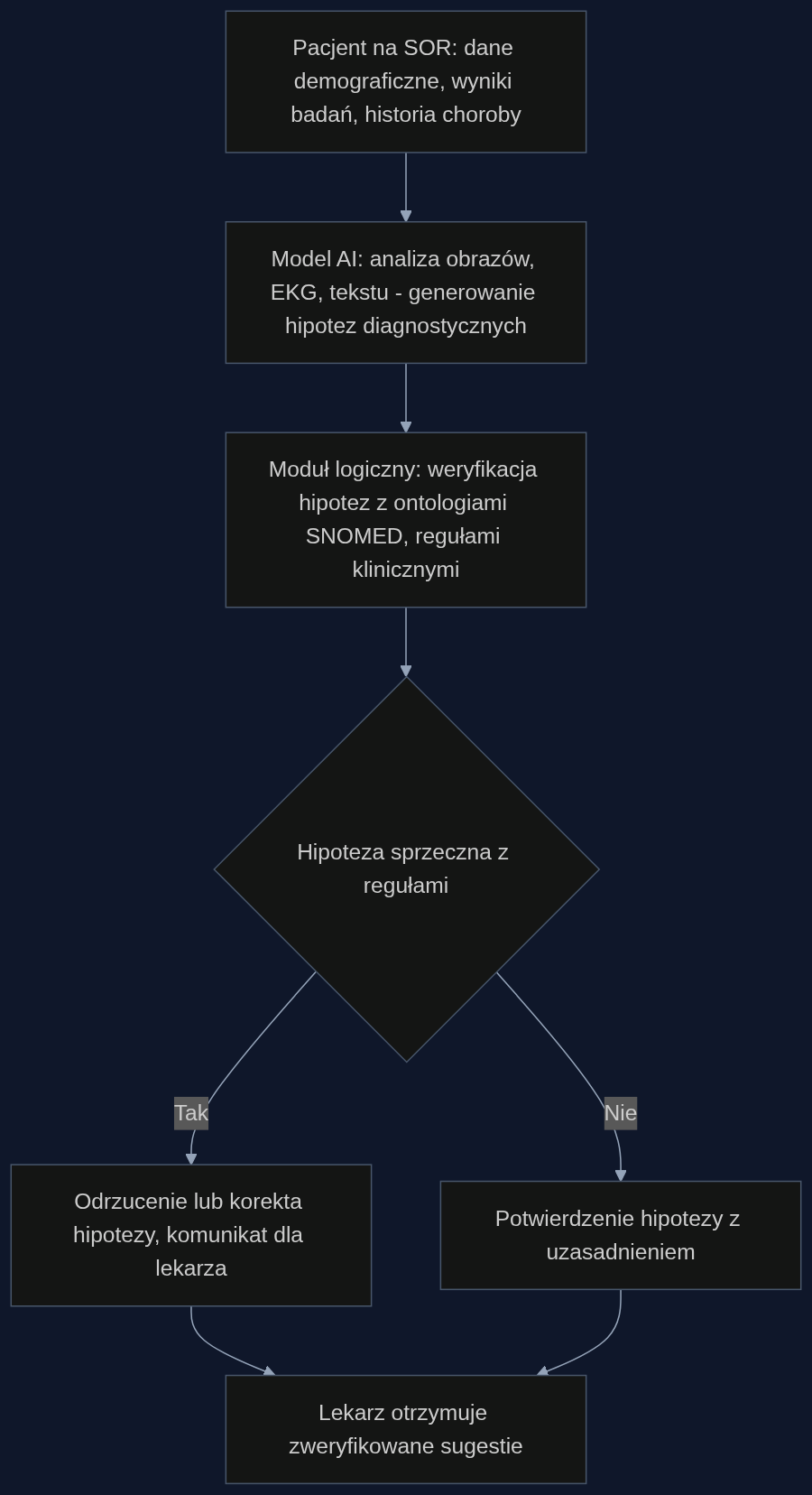
Scenariusz: oddział ratunkowy, 350 pacjentów dziennie, 3 minuty na decyzję
Wyobraźmy sobie SOR w mieście wojewódzkim. Lekarz dyżurny przyjmuje 67-letnią kobietę z dusznością, tachykardią i bólem w klatce piersiowej. AI analizuje EKG, troponinę, d-dimery, zdjęcie RTG i historię leczenia (pacjentka ma POChP i przyjmuje beta-bloker). W ciągu 30 sekund model pokazuje trzy hipotezy: zatorowość płucna, zaostrzenie POChP, zawał STEMI. Moduł logiczny weryfikuje każdą: przy zatorowości płucnej sprawdza skalę Wellsa i wynik d-dimerów (tu są podwyższone, ale nie wyklucza to POChP); przy zawale STEMI sprawdza, czy uniesienia ST są obecne w dwóch sąsiadujących odprowadzeniach (są, ale w odprowadzeniach V1-V3, co może być maskowane przez blok lewej odnogi). Ostatecznie system podpowiada: “STEMI prawdopodobny, wykonaj echokardiografię przyłóżkową w celu potwierdzenia odcinkowych zaburzeń kurczliwości”.
Bez modułu logicznego model mógłby zasugerować zatorowość płucną jako główną hipotezę, bo w danych treningowych takie przypadki dominowały. W rzeczywistości pacjentka trafiła do pracowni hemodynamicznej w 42 minuty od przyjęcia – o 18 minut szybciej niż wynosiła mediana dla podobnych przypadków w tym szpitalu przed wdrożeniem hybrydy. Z danych własnych placówki wynika, że odsetek błędów logicznych spadł z 12 do 2 procent na każde 1000 analiz.
Koszty, zwrot i bezpieczeństwo – twarde liczby zamiast obietnic
Wdrożenie modułu weryfikacji ontologicznej w trzyletnim kontrakcie z dostawcą chmurowym to wydatek rzędu 400-600 tysięcy złotych rocznie dla średniej wielkości szpitala (dane z zapytań ofertowych złożonych przez dwa polskie szpitale kliniczne w 2024 roku). Po stronie korzyści: redukcja błędnych diagnoz o 7-11 procent (według metaanalizy z 2023 roku opublikowanej w “The Lancet Digital Health”) przekłada się na oszczędności z tytułu unikniętych roszczeń, skrócenia hospitalizacji oraz mniejszej liczby niepotrzebnych badań. W modelu dla 500-łóżkowego szpitala oznacza to oszczędność około 1,2 miliona złotych rocznie – nie licząc poprawy reputacji i mniejszego wypalenia zawodowego lekarzy.
Skalowanie samego modelu językowego nie załatwi problemu. Testy na sylogizmach pokazują, że większy model może osiągać wyższą trafność, ale nadal myli się w wyjaśnieniach. Dopiero dodanie warstwy formalnej weryfikacji odcina te 2-5 procent najgroźniejszych pomyłek, które w medycynie kosztują najwięcej. Nie warto czekać na kolejną generację ChatGPT – warto zacząć od pilotażu na jednym oddziale, np. kardiologii, gdzie reguły są dobrze skodyfikowane, a dane z monitorowania dają szybki feedback.
Od pilotażu do standardu – co przetestować w pierwszej kolejności
Jeśli planujesz pilotaż, nie celuj od razu w pełną diagnostykę różnicową. Wybierz wąski obszar, gdzie znane są sztywne wytyczne: na przykład sprawdzanie interakcji lekowych u pacjentów z polipragmazją przy wypisie. Albo weryfikację zgodności rozpoznania radiologicznego z kodem ICD-10 na podstawie opisu słownego. W ciągu 4 tygodni na próbie 300 przypadków zobaczysz, ile razy moduł logiczny koryguje sugestię AI i czy te korekty są zasadne. Bez takiego testu festiwal slajdów od dostawców technologii zostanie festiwalem slajdów.
Najważniejsze: nie traktuj AI jako automatu diagnostycznego. Traktuj ją jak asystenta, który potrafi szybko przeskanować dane, ale potrzebuje nadzoru – i ten nadzór nie może pochodzić wyłącznie od zmęczonego człowieka. Musi pochodzić od drugiego, logicznego mózgu w systemie. To jedyna droga, żeby technologia rzeczywiście zmniejszyła liczbę błędów, a nie tylko zmieniła ich charakter.
- Redukcja błędów logicznych w diagnozie o 7-11 proc.
- Zmniejszenie liczby niepotrzebnych badań i hospitalizacji
- Skrócenie czasu do kluczowej decyzji klinicznej nawet o 30 proc.
- Wzrost zaufania lekarzy do systemów AI dzięki transparentnym wyjaśnieniom
- Oszczędności rzędu 1,2 mln zł rocznie dla 500-łóżkowego szpitala
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: Data-driven Machine Learning Cannot Reach Symbolic-level Logical Reasoning — The Limit of the Scaling Law
Autorzy: Tiansi Dong, Mateja Jamnik, Pietro Li\`o
Sphere neural networks have achieved symbolic level syllogistic reasoning without training data, raising the question of where the limit of the scaling law for logical reasoning lies, i.e., whether data-driven machine learning systems can achieve the same level by increasing training data and tra…
arXiv: arxiv.org/abs/2606.26454
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}