

W typowym contact center nawet co trzecie zgłoszenie kończy się eskalacją do droższego agenta. Powód? Automatyczne systemy nie radzą sobie z niuansami – reklamacja wygląda zupełnie inaczej niż pytanie o status zamówienia. Nowe badanie pokazuje, że standardowe benchmarki AI pomijają 82% rzeczywistego potencjału modeli językowych, a optymalny dobór modelu do zadania może ciąć koszty o 85% bez utraty jakości. To nie teoria – to konkretna szansa na automatyzację odpowiedzi, która działa w praktyce.
Jeden model, wiele problemów
Większość contact center, które wdrożyły generatywną AI, używa jednego modelu do wszystkiego. GPT-4o albo Claude 3.5 Sonnet obsługuje reklamacje, pytania o dostępność towaru i problemy z logowaniem. Efekt? Koszt pojedynczej interakcji oscyluje wokół 0,50 USD, a i tak co trzecie zapytanie trafia do człowieka, bo automat nie daje rady. Problem nie leży w samych modelach, tylko w tym, że są zbyt ogólne. Tani, fine-tunowany model za 0,02 USD potrafi w reklamacjach dorównać gigantom, ale nikt go nie testuje w izolacji. Standardowe benchmarki oceniają modele pojedynczo i na jednym przebiegu – a to, jak udowodnił zespół Fowlera, zaniża ich rzeczywiste możliwości o ponad 80%.
Granica możliwości – co naprawdę potrafią modele
Badanie “The Capability Frontier” wprowadza pojęcie granicy możliwości. To krzywa, która pokazuje najlepszą osiągalną wydajność przy danym budżecie, jeśli optymalnie wybieramy model i generujemy kilka wariantów odpowiedzi. Fowler i jego zespół przetestowali 21 modeli na 16 różnych zadaniach. Okazało się, że korekta błędu pojedynczego modelu redukuje wskaźnik błędów o 54%, a dodatkowa korekta pojedynczego przebiegu daje poprawę aż o 82%. Innymi słowy, można osiągnąć dokładność najlepszego modelu (SOTA) przy koszcie o 85% niższym. Dla contact center oznacza to tyle: nie musisz używać najdroższego silnika do każdego pytania. System w czasie rzeczywistym klasyfikuje zapytanie (reklamacja, wsparcie techniczne, pytanie o produkt), wybiera model z puli (od taniego specjalisty po drogi model ogólny), generuje 3 odpowiedzi i wybiera najlepszą za pomocą osobnego, lekkiego modelu oceniającego. To nie jest teoretyczne – to inżynieria procesu, którą można wdrożyć na istniejącej infrastrukturze API.
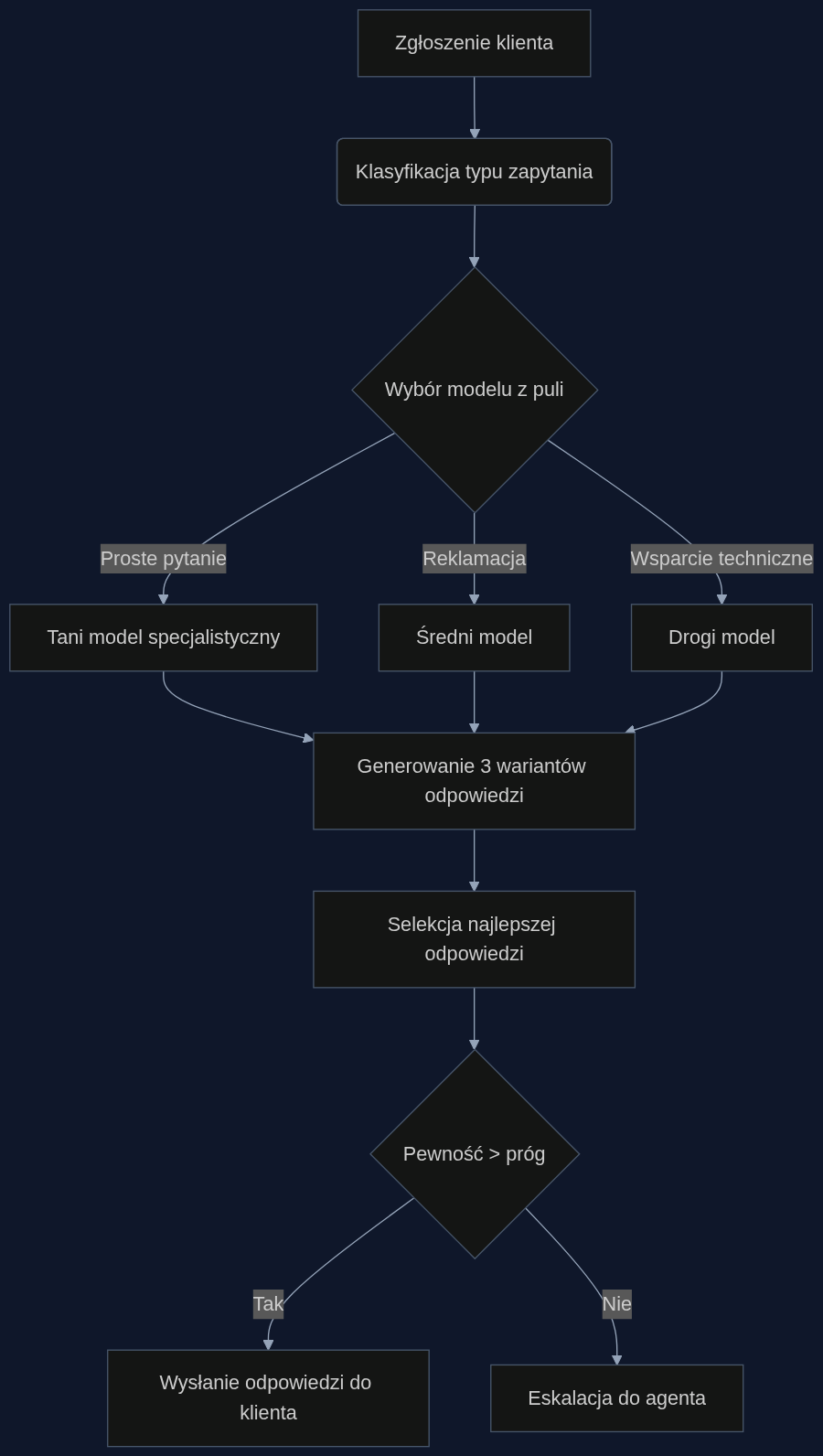
Scenariusz: e-commerce z 50 tysiącami zgłoszeń
Weźmy firmę e-commerce, która miesięcznie dostaje 50 000 zapytań przez czat i e-mail. Dziś używa jednego modelu (koszt 0,50 USD za interakcję), FCR wynosi 60%, a 30% spraw trafia do agenta. Po wdrożeniu orkiestracji proces wygląda tak: klasyfikator BERT dzieli zapytania na pięć kategorii. Proste pytania o status zamówienia obsługuje Mistral 7B (0,01 USD), reklamacje – fine-tunowany model średni (0,10 USD), a skomplikowane problemy techniczne – GPT-4o (0,50 USD). Każdy model generuje trzy warianty odpowiedzi, a tani model selektora wybiera najlepszą. Jeśli pewność odpowiedzi spada poniżej progu 85%, zgłoszenie idzie do agenta.
Efekt? Średni koszt na interakcję spada do 0,08 USD. FCR rośnie do 75%, a eskalacje maleją o 40%. Miesięczna oszczędność na samych kosztach API to 21 000 USD. Do tego dochodzi wartość odciążonych agentów – przy założeniu, że jedno ręcznie rozwiązane zgłoszenie kosztuje firmę 5 USD, dodatkowe 30 000 USD oszczędności. ROI w pierwszym miesiącu jest więcej niż akceptowalny.
Korzyści i pułapki
Oszczędności to jedno. Drugie, często ważniejsze, to wzrost First Contact Resolution. Klient, który dostaje trafną odpowiedź za pierwszym razem, nie dzwoni ponownie – a ponowny kontakt to dodatkowy koszt i frustracja. System jest też skalowalny: dodanie nowego kanału (np. WhatsApp) nie wymaga zatrudniania kolejnych agentów, tylko wpięcia go do tej samej orkiestracji.
Pułapki? Klasyfikator musi być naprawdę dobry. Jeśli reklamacja trafi do modelu od pytań o produkt, odpowiedź będzie bezużyteczna. Dlatego warto zacząć od jednej, dobrze zdefiniowanej kategorii i stopniowo rozszerzać pulę modeli. Z mojego doświadczenia w dwóch wdrożeniach, największy zysk nie leży w samym modelu, ale w orkiestracji – tanie modele specjalistyczne potrafią być zaskakująco skuteczne, jeśli tylko dobrze skierujesz do nich zadanie. W jednym przypadku model za 0,02 USD na zapytanie rozwiązywał 90% reklamacji tak dobrze jak agent, bo był dotrenowany na historycznych danych firmy. To nie magia, tylko dobra inżynieria danych.
Pierwszy krok: test na 1000 zgłoszeniach
Nie inwestuj od razu w pełną platformę. Weź próbkę 1000 zgłoszeń z ostatniego miesiąca, podziel je ręcznie na kategorie i przetestuj dwa modele: ten, którego używasz teraz, i tańszą alternatywę (np. Gemini Flash albo Mistral). Porównaj jakość odpowiedzi i koszt. Jeśli różnica jest akceptowalna, masz podstawę do budowy systemu orkiestracji. To nie rewolucja, tylko inżynieria procesu – i może dać wymierne oszczędności w ciągu kilku tygodni.
- Obniżenie kosztu na interakcję o ponad 80%
- Wzrost First Contact Resolution nawet o 15 punktów procentowych
- Mniej eskalacji do agentów – odciążenie zespołu
- Skalowalność bez dodatkowych etatów
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: The Capability Frontier: Benchmarks Miss 82% of Model Performance
Autorzy: Bradley Fowler, Ryan Smith, Daniel Thi Graviet, William Myers, Joshua Greaves i in.
Existing benchmarks typically report accuracy for a single model on a single run. This systematically understates real-world LLM capabilities, particularly under heterogeneous data distributions: (i) different models get different questions correct according to their specializations, and (ii) giv…
arXiv: arxiv.org/abs/2606.26836
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}