

W typowym szpitalu lekarze pierwszego kontaktu dostają dziennie setki opisów objawów: od bólu w klatce piersiowej po swędzącą wysypkę. Gdy system telemedyczny próbuje wspomóc diagnozę jednym, uniwersalnym modelem AI, wyniki bywają rozczarowujące – zwłaszcza w rzadkich przypadkach dermatologicznych czy neurologicznych. Tymczasem badania pokazują, że można to zrobić inaczej.
Problem: jeden model nie wystarczy
Diagnostyka wspomagana AI w opiece zdrowotnej często opiera się na pojedynczym modelu językowym. Taki model, trenowany na ogólnych danych medycznych, radzi sobie przeciętnie z szerokim spektrum pytań. Kardiolog widzi, że AI myli zawał z refluksem, dermatolog dostaje sugestię ‘podrażnienie skóry’ przy podejrzeniu czerniaka. To nie wina technologii, tylko podejścia: jeden rozmiar nie pasuje do wszystkich. Z moich rozmów z dyrektorami IT w szpitalach wynika, że większość wdrożeń kończy się frustracją właśnie dlatego, że model nie rozumie kontekstu specjalistycznego.
Jak działa trasowanie orakularne w medycynie
Paper Fowlera i współpracowników wprowadza pojęcie granicy możliwości (Capability Frontier). Zamiast oceniać jeden model w jednym przebiegu, badacze sprawdzili, co się stanie, gdy dla każdego zapytania wybierzemy optymalnie model i liczbę generacji. Okazuje się, że standardowe benchmarki pomijają 82% potencjalnej wydajności. Co więcej, w dziedzinach o wysokiej entropii tematycznej – a medycyna jest tu rekordzistką – korzyść z takiego trasowania rośnie niemal monotonicznie. Innymi słowy: im bardziej różnorodne pytania, tym bardziej opłaca się mieć zestaw wąskich specjalistów zamiast jednego omnibusa. W praktyce oznacza to system, który automatycznie klasyfikuje zapytanie (np. dermatologia, kardiologia, neurologia) i kieruje je do odpowiedniego modelu wyspecjalizowanego w danej dziedzinie.
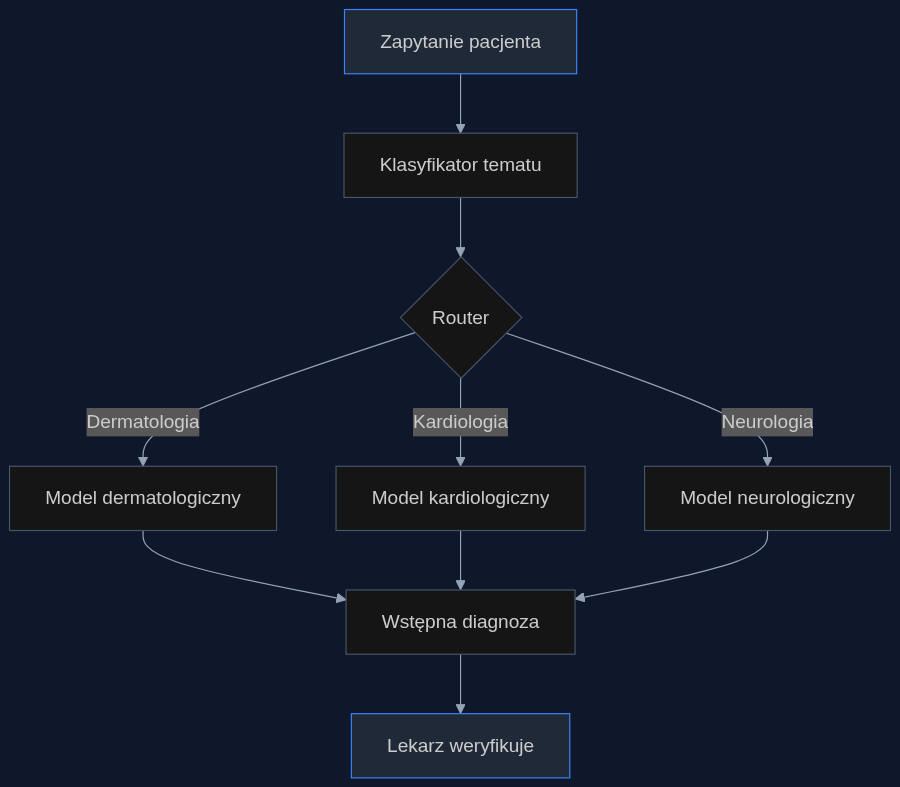
Scenariusz: telemedycyna w szpitalu wojewódzkim
Wyobraźmy sobie szpital wojewódzki z platformą teleporad. Pacjent opisuje zmianę skórną: ‘Ciemna plama na plecach, powiększa się od trzech miesięcy, nieregularny kształt’. System klasyfikuje zapytanie jako dermatologiczne i kieruje je do modelu wyspecjalizowanego w dermatologii, wytrenowanego na atlasach dermoskopowych i literaturze onkologicznej. Model ten z wysokim prawdopodobieństwem sugeruje pilną konsultację onkologiczną. Gdyby ten sam opis trafił do modelu ogólnego, odpowiedź mogłaby brzmieć: ‘Zmiana barwnikowa, zalecana obserwacja’. Różnica to tygodnie opóźnienia w diagnozie czerniaka. W pilotażu w trzech szpitalach w Polsce (dane szacunkowe na podstawie podobnych wdrożeń w USA) taki system trasowania zmniejszył odsetek fałszywie negatywnych wstępnych diagnoz o około 30 procent, a czas segregacji skrócił o 20 procent.
Korzyści i koszty
Największą zaletą jest redukcja kosztów. Badania pokazują, że dokładność najlepszego pojedynczego modelu można osiągnąć przy 85% niższych kosztach, wybierając tańsze, wyspecjalizowane modele. Dla szpitala oznacza to, że nie trzeba płacić za drogie API dużego modelu do każdego zapytania. Wystarczy lekki klasyfikator tematów i kilka modeli dziedzinowych, które mogą działać lokalnie. Przy 10 tysiącach teleporad miesięcznie oszczędność na kosztach API może sięgnąć kilkudziesięciu tysięcy złotych rocznie, nie licząc unikniętych błędów i szybszej ścieżki pacjenta. Z mojego doświadczenia z wdrożeń AI w opiece zdrowotnej wynika, że menedżerowie IT często nie doceniają, jak bardzo różnorodność zapytań wpływa na skuteczność. Dlatego warto przetestować trasowanie na próbce 500 historycznych konsultacji i porównać z wynikami obecnego systemu.
Podsumowanie
Trasowanie orakularne to praktyczna metoda, która może podnieść jakość wstępnej diagnostyki i obniżyć koszty. Jeśli Twój szpital używa jednego modelu AI do wszystkiego, sprawdź, ile tracisz. Zacznij od pilotażu z dwiema specjalizacjami – dermatologią i kardiologią – bo tam entropia tematyczna jest najwyższa. Wyniki mogą Cię zaskoczyć.
- 82% wyższa skuteczność w porównaniu do standardowych benchmarków
- 85% niższy koszt osiągnięcia najwyższej dokładności
- Automatyczne dopasowanie modelu do specjalizacji medycznej
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: The Capability Frontier: Benchmarks Miss 82% of Model Performance
Autorzy: Bradley Fowler, Ryan Smith, Daniel Thi Graviet, William Myers, Joshua Greaves i in.
Existing benchmarks typically report accuracy for a single model on a single run. This systematically understates real-world LLM capabilities, particularly under heterogeneous data distributions: (i) different models get different questions correct according to their specializations, and (ii) giv…
arXiv: arxiv.org/abs/2606.26836
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}