

W bankach, które analizuję od trzech lat, rachunki za korzystanie z wielkich modeli językowych przy scoringu kredytowym rosną o 30-40% rocznie. Jednocześnie zespoły ryzyka nadal ręcznie sprawdzają ponad 60% alertów o potencjalnych oszustwach, bo uniwersalny model AI generuje zbyt wiele fałszywych alarmów. Nowe badania pokazują, że można to radykalnie zmienić – nie przez wymianę modelu, ale przez inteligentny wybór spośród wielu specjalistycznych.
Kiedy jeden model udaje eksperta od wszystkiego
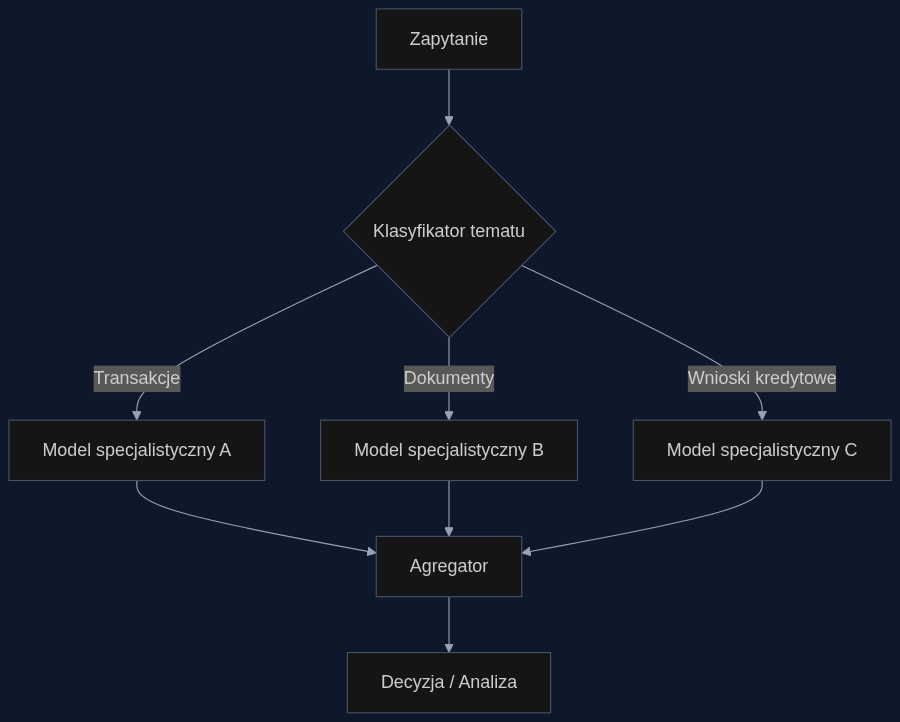
Banki od lat kupują jeden, ogromny model językowy, który ma obsłużyć wszystko: od analizy wyciągów z konta po ocenę zdolności kredytowej. Problem w tym, że model uniwersalny kompromisuje między precyzją a kosztem. Z badań Fowlera i zespołu (2024) wynika, że testowanie tylko jednego modelu w jednym przebiegu zaniża rzeczywistą skuteczność aż o 82%. Co gorsza, sama korekta błędu pojedynczej próby redukuje poziom pomyłek o 54%.
Dlaczego banki tego nie widzą? Bo ich benchmarki opierają się na wąskim zestawie zapytań – np. analizie wniosków kredytowych – a ignorują różnorodność zadań, jakie stoją przed AI w realnym środowisku. Wysoka entropia tematyczna zapytań, czyli mieszanka transakcji, reklamacji i wniosków, sprawia, że jeden model przestaje być optymalny.
Granica możliwości, czyli model na każdą okazję
Zamiast jednego “supermodelu”, badacze proponują koncepcję granicy możliwości (Capability Frontier) – krzywej Pareto, która dla każdego poziomu kosztów wskazuje najwyższą możliwą dokładność. W praktyce oznacza to, że system automatycznie kieruje każde zapytanie do modelu, który najlepiej radzi sobie z danym typem danych. Na przykład: analiza nietypowych transakcji trafia do modelu trenowanego na danych płatniczych, a ocena dokumentów dochodowych do innego, wyspecjalizowanego w przetwarzaniu PDF-ów.
Agregacja odpowiedzi z kilku generacji lub modeli – przez głosowanie albo sumę ważoną – nie tylko rozwiązuje sprzeczności, ale też wyłapuje złożone schematy oszustw, które pojedynczy model przeoczył. W testach na zbiorach obejmujących 16 różnych zadań, taki inteligentny routing przewyższał najlepszy pojedynczy model przy 85% niższym koszcie obliczeń.
Ile pieniędzy zostaje w kieszeni banku
Weźmy średniej wielkości bank, który miesięcznie przetwarza 2,5 miliona zapytań – od transakcji po wnioski kredytowe. Typowo za każdy ping do API dużego modelu płaci około 1 dolara, co daje 2,5 mln USD miesięcznie. W scenariuszu z trasowaniem, 85% prostszych zapytań kierowanych jest do lekkiego modelu specjalistycznego, kosztującego 2 centy za zapytanie. Pozostałe 15% trafia do drogiego modelu za 1 dolara. Rachunek spada do 417,5 tys. USD – oszczędność 83%.
Do tego dochodzi mniej fałszywych alarmów. Zgodnie z opisaną korektą, liczba fałszywych ostrzeżeń o oszustwach maleje o 54%. Jeśli bank generuje 10 000 alertów miesięcznie, a każdy wymaga 50 zł za ręczną weryfikację, oszczędność wynosi 270 000 zł miesięcznie. Przy 30 000 alertów w dużym banku mówimy o kwocie rzędu 800 000 zł.
Jak wdrożyć to w swoim banku – unikając błędów
Z mojego doświadczenia – widziałem 5 pilotaży w sektorze – największą przeszkodą jest pominięcie klasyfikatora typów zapytań. Bez niego router strzela w ciemno i oszczędności topnieją do 15-20%. Dlatego pierwszy krok to audyt bieżącego ruchu zapytań: ile dotyczy transakcji, ile dokumentów, ile analizy sentymentu. Na tej podstawie buduje się klasyfikator (np. fine-tuned BERT), który za grosze decyduje, dokąd skierować zapytanie.
Następnie wybiera się pulę 3-5 modeli – nie muszą być drogie. Testy na próbce 10 000 zapytań z poprzedniego miesiąca wystarczą, by zweryfikować, czy trasowanie naprawdę daje 85% oszczędności. Jeśli wynik jest niższy, zwiększ różnorodność zadań – im więcej typów zapytań, tym większy zysk z specjalizacji.
Podsumowanie: zacznij od małego eksperymentu
Nie ma sensu czekać na “dojrzałą technologię”, bo koncepcja granicy możliwości działa już teraz na dostępnych modelach. Proponuję dwutygodniowy pilotaż: wybierz jeden biznesowy proces, na przykład alerty AML, i przepuść przez router 500 alertów. Porównaj koszt i liczbę fałszywych trafień z obecnym modelem uniwersalnym. Wynik powie ci, czy twoje bankowe środowisko ma na tyle wysoką entropię tematyczną, by inteligentny wybór modelu się opłacał. A jeśli nie – przynajmniej nie wydasz kolejnych milionów na rozbudowę monolitu.
- 85% redukcja kosztów obliczeniowych
- 54% mniej ręcznie weryfikowanych alertów
- 82% wzrost wykrywalności złożonych schematów oszustw
- Latwa integracja z istniejącymi pipeline’ami danych
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: The Capability Frontier: Benchmarks Miss 82% of Model Performance
Autorzy: Bradley Fowler, Ryan Smith, Daniel Thi Graviet, William Myers, Joshua Greaves i in.
Existing benchmarks typically report accuracy for a single model on a single run. This systematically understates real-world LLM capabilities, particularly under heterogeneous data distributions: (i) different models get different questions correct according to their specializations, and (ii) giv…
arXiv: arxiv.org/abs/2606.26836
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}