

Konsultant po raz piąty słyszy podniesiony głos, a trener notuje: 'reakcja zbyt chłodna, klient czuł się zignorowany'. Standardowe skrypty nie przygotowują na niuanse - sfrustrowany abonent reaguje inaczej niż klient, który dostał błędną fakturę na 3 tysiące złotych. Nowe podejście, oparte na modelu DITTO, pozwala tworzyć symulacje, które dostrajają się do wskazówek słownych, a nie sztywnych reguł.
Od skalarnej oceny do słownej krytyki
W typowych symulatorach rozmów model AI jest nagradzany liczbą - na przykład 0,8 za 'poprawność'. Problem w tym, że ludzkie emocje nie są jednowymiarowe. Trenerzy w contact center myślą kategoriami: 'za szybko podniosłeś głos', 'ton był protekcjonalny', 'zbagatelizowałeś stratę czasu klienta'. DITTO, model opisany przez zespół Weiwei Sun, przyjmuje właśnie taką werbalną informację zwrotną. Po każdej odpowiedzi symulatora trener wpisuje komentarz w języku naturalnym - model generuje poprawioną wersję, a obie są wspólnie optymalizowane za pomocą mechanizmu GRPO (Group Relative Policy Optimization). Efekt? Symulator uczy się niuansów bez potrzeby definiowania sztywnych metryk. W testach benchmarku SOUL model osiągnął średnio 36% poprawy względem wersji bazowej i przewyższył GPT-5.4 w 6 z 10 zadań symulacji ludzkich zachowań.
Scenariusz: wdrożenie w dziale szkoleń operatora telekomunikacyjnego
Weźmy firmę z 300-osobowym contact center, która wdraża 40 nowych konsultantów co kwartał. Obecnie każdy przechodzi 16 godzin symulacji z trenerem na żywo - to 640 roboczogodzin trenerskich na kwartał. Przy stawce 60 zł za godzinę pracy trenera, sam koszt sesji 1:1 to prawie 40 tysięcy złotych. Do tego dochodzą rotacje - według danych Contact Center Benchmark Report średni wskaźnik odejść w pierwszym roku to 32%, często z powodu stresu przy eskalacjach.
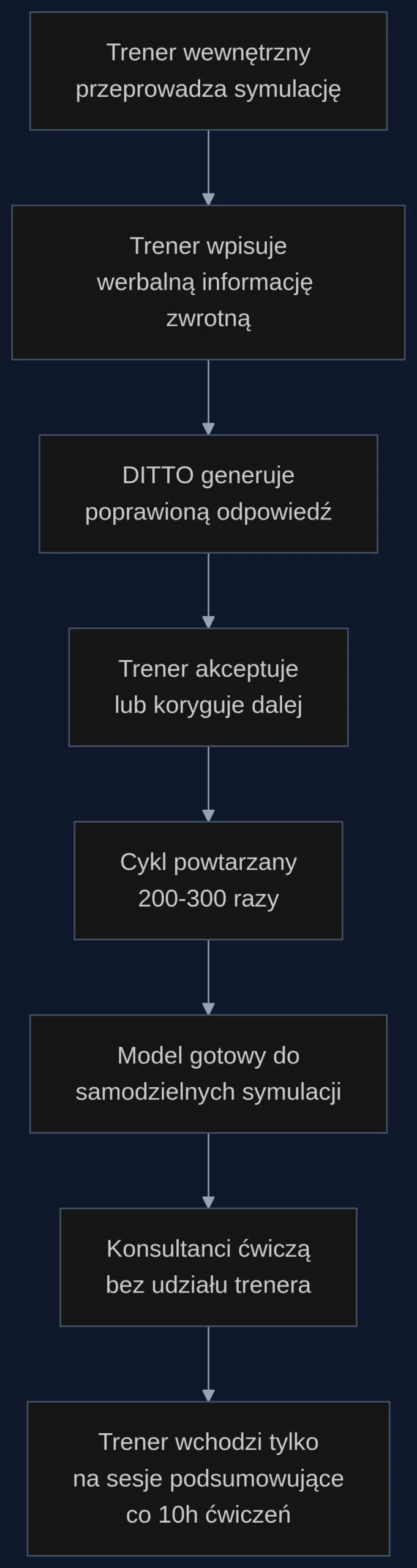
Z DITTO proces wygląda inaczej. W pierwszym tygodniu trenerzy wewnętrzni - osoby z 5-letnim stażem, które znają specyfikę bazy klientów - przeprowadzają po 30 sesji z modelem. Po każdej rozmowie wpisują komentarz: 'klient na początku był spokojny, twoja odpowiedź eskalowała zbyt szybko' albo 'zabrakło potwierdzenia, że rozumiesz stratę czasu klienta'. Model generuje poprawioną wersję - trener akceptuje lub koryguje dalej. Po 200-300 takich interakcjach symulator jest gotowy do samodzielnej pracy.
Od drugiego tygodnia konsultanci ćwiczą z modelem bez udziału trenera. System generuje scenariusze - sfrustrowany klient biznesowy z awarią łącza, rozżalony senior, który nie rozumie regulaminu, zdenerwowany rodzic z podwójnym naliczeniem abonamentu. Model reaguje adekwatnie do tonu konsultanta: jeśli odpowiedź jest zbyt defensywna, klient się wycofuje lub podnosi głos. Jeśli empatyczna - rozmowa zmierza ku rozwiązaniu. Trenerzy wchodzą tylko na sesje podsumowujące co 10 godzin ćwiczeń.
Konkretne liczby i zwrot z inwestycji
Oparte na realiach polskich contact center, szacunki dla 300-osobowego zespołu:
- Redukcja czasu trenerskiego o 60% w pierwszym kwartale po wdrożeniu - oszczędność około 24 tysięcy złotych na kwartał przy założeniu 40 nowych konsultantów.
- Skrócenie pełnego wdrożenia z 4 tygodni do 18 dni roboczych - model jest dostępny 24/7, bez ograniczeń grafiku trenera.
- Spadek eskalacji w pierwszej linii o 15-20% po 3 miesiącach - konsultanci przećwiczyli 50-60 trudnych scenariuszy przed pierwszą realną rozmową.
- Zmniejszenie rotacji o 5-8 punktów procentowych w grupie nowozatrudnionych - mniej sytuacji, w których pracownik rezygnuje po pierwszej wyjątkowo trudnej eskalacji.
Koszt wdrożenia to integracja z istniejącą platformą voicebot/symulatora (szacunkowo 80-120 tysięcy złotych jednorazowo) plus miesięczny koszt inferencji modelu (około 3-5 tysięcy złotych przy 10 tysiącach sesji miesięcznie). Zwrot następuje w 2-3 kwartały, liczony tylko z oszczędności na pracy trenerów.
Dlaczego werbalna informacja zwrotna zmienia reguły gry
Dotychczasowe symulatory działały na drzewach decyzyjnych: jeśli konsultant użyje słowa 'przepraszam', klient się uspokaja. Rzeczywistość jest bardziej skomplikowana - przeprosiny wypowiedziane bez przekonania eskalują konflikt. DITTO nie potrzebuje słownych wskazówek w czasie działania. Destyluje je do swojej polityki podczas treningu, więc w trakcie symulacji działa autonomicznie. To jest różnica między systemem, który 'zna reguły', a systemem, który 'rozumie, dlaczego reguła działa'.
Dla menedżera jakości oznacza to symulator, który odzwierciedla standardy konkretnej firmy - nie ogólny model 'trudnego klienta', tylko klienta tej marki, z tymi problemami i tym stylem komunikacji. Trenerzy wewnętrzni są źródłem wiedzy o tym, co działa, a co nie - model jedynie tę wiedzę skaluje.
- 60% mniej czasu trenerskiego na wdrożenie nowego konsultanta
- 18 dni zamiast 4 tygodni do pełnej samodzielności
- 15-20% mniej eskalacji w pierwszej linii po 3 miesiącach
- 5-8 p.p. niższa rotacja w grupie nowozatrudnionych
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: Reinforcing Human Behavior Simulation via Verbal Feedback
Autorzy: Weiwei Sun, Xuhui Zhou, Jiarui Liu, Weihua Du, Haojia Sun i in.
Humans learn social norms and behaviors from verbal feedback (e.g., a parent saying "that was rude" or a friend explaining "here's why that hurt"). Yet, learning from feedback for LLMs has largely focused on domains like code and math, where RL rewards are directly verifiable and condensed into s...
arXiv: arxiv.org/abs/2605.20506
Czytaj więcej o tej technologii: DITTO: Jak słowna krytyka uczy AI lepszych manier
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}