
Dziecko uczy się, że nie wolno krzyczeć, bo rodzic mówi: 'to niegrzeczne'. DITTO - nowy model AI - działa podobnie. Zamiast suchych liczb, dostaje słowną krytykę i na jej podstawie poprawia swoje zachowanie w symulacjach.
Od besztania do nauki - jak słowa kształtują AI
Ludzie nie uczą się norm społecznych z tabel punktowych. Matka nie mówi 'twoje zachowanie oceniam na 3/10'. Mówi: 'to było niegrzeczne'. Badacze z Carnegie Mellon, Microsoft Research i innych instytucji wyszli z tego samego założenia, tworząc DITTO. To model językowy, który czerpie wiedzę z komentarzy w języku naturalnym - werbalnej informacji zwrotnej - zamiast ze skalarnych nagród typowych dla uczenia ze wzmocnieniem.
Dotychczasowe próby symulowania ludzkich zachowań przez AI opierały się na liczbowej ocenie: model dostawał plusa lub minusa. Problem w tym, że rzeczywiste interakcje są wielowymiarowe. Odpowiedź może być merytorycznie poprawna, ale niegrzeczna, albo empatyczna, lecz nieprecyzyjna. Werbalna informacja zwrotna - taka, jakiej udzielamy sobie nawzajem - niesie te niuanse. DITTO potrafi je odczytać i przełożyć na lepszą politykę działania, bez potrzeby podawania komentarzy w trakcie właściwego testu.
Autorzy piszą wprost: 'Ludzie uczą się norm społecznych i zachowań z werbalnej informacji zwrotnej (np. rodzic mówiący 'to było niegrzeczne' lub przyjaciel tłumaczący 'oto dlaczego to zabolało')'. Na tej obserwacji zbudowano całą metodę.
DITTO: dwa kroki do lepszej symulacji
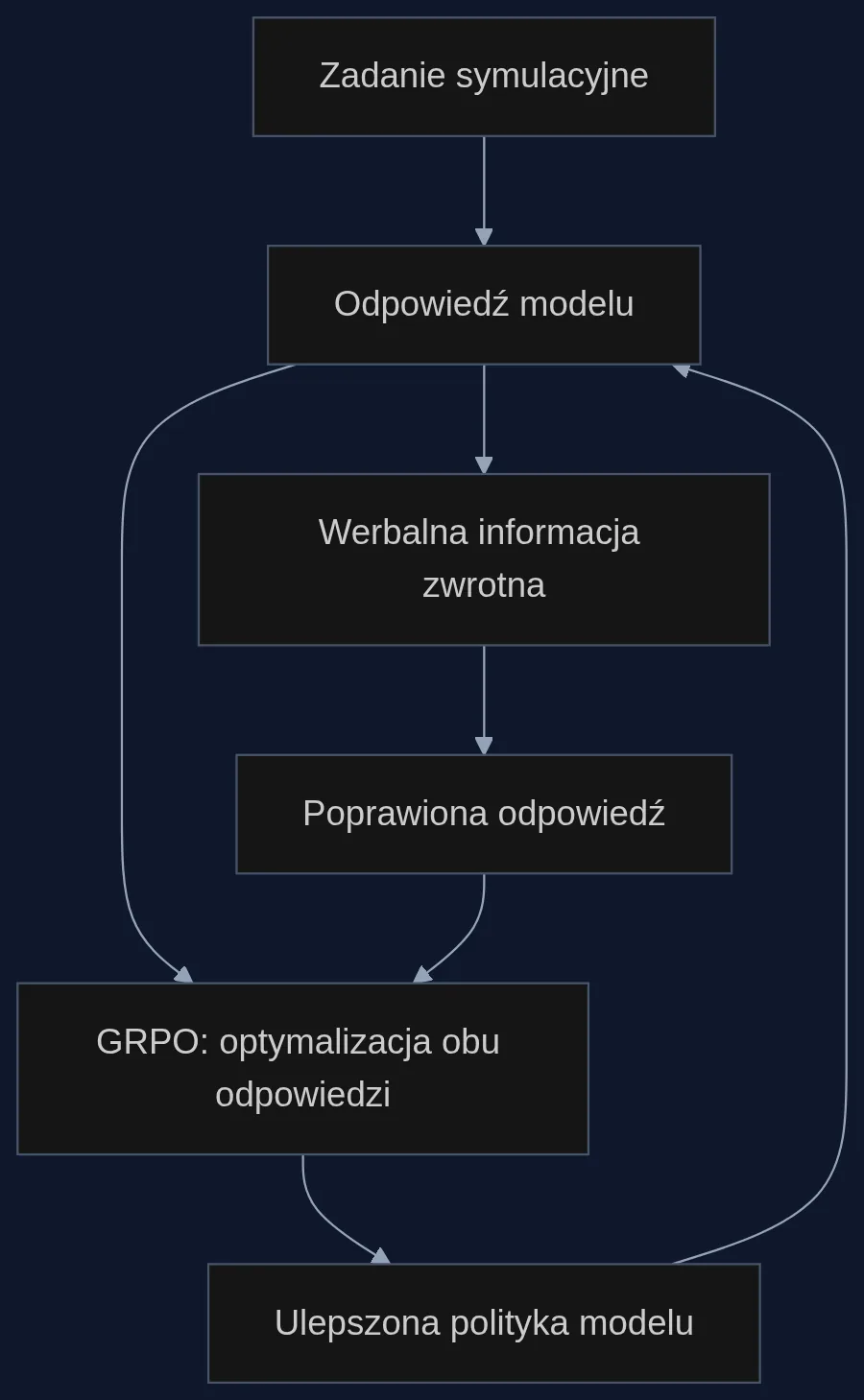
Mechanizm DITTO jest prosty. Wyobraźmy sobie trenera personalnego, który po każdym ćwiczeniu nie wystawia oceny, tylko mówi: 'za bardzo garbisz plecy' albo 'świetnie, teraz wolniej'. Model działa w dwóch krokach. Najpierw generuje odpowiedź na zadanie symulacyjne - na przykład odgrywa rolę ucznia. Następnie otrzymuje werbalną informację zwrotną (np. 'ta wypowiedź brzmiała arogancko') i na jej podstawie tworzy poprawioną wersję. Obie odpowiedzi - pierwotna i poprawiona - są wspólnie optymalizowane za pomocą algorytmu GRPO (Group Relative Policy Optimization).
GRPO porównuje grupę odpowiedzi i wyznacza kierunek poprawy. Dzięki temu model nie tylko uczy się unikać konkretnych błędów, ale też internalizuje ogólne zasady, które kryją się za słownymi wskazówkami. To trochę jak uczeń, który po kilku uwagach nauczyciela sam zaczyna rozumieć, co znaczy 'dobrze napisane wypracowanie', i nie potrzebuje już ciągłych poprawek. W czasie testu DITTO działa już bez dostępu do informacji zwrotnej - destyluje ją do swojej wewnętrznej polityki.
Ludzie uczą się norm społecznych i zachowań z werbalnej informacji zwrotnej (np. rodzic mówiący 'to było niegrzeczne' lub przyjaciel tłumaczący 'oto dlaczego to zabolało').
Weiwei Sun i in.
Abstract
SOUL - 10 sprawdzianów dla cyfrowego człowieka
Żeby rzetelnie ocenić postępy, potrzebny był solidny poligon. Badacze stworzyli SOUL (Simulation gym Of hUman-Like behavior) - zestaw dziesięciu zadań z sześciu kategorii: teoria umysłu, odgrywanie ról, umiejętności społeczne, symulacja ucznia, symulacja użytkownika i symulacja persony. To pierwszy tak spójny benchmark do testowania, czy AI potrafi zachowywać się jak człowiek w różnych kontekstach.
Zadania nie są abstrakcyjne. Model musi na przykład wczuć się w pacjenta opisującego objawy, ucznia zadającego pytania, czy użytkownika testującego nową aplikację. Każdy scenariusz wymaga innego rodzaju empatii, precyzji i wyczucia społecznego. SOUL dostarcza zarówno danych treningowych, jak i jednolitej metryki - dzięki temu można porównywać różne podejścia w uczciwy sposób.
Lepszy niż GPT-5.4 - wyniki, które robią różnicę
Wyniki są mocne. DITTO osiągnął średnio 36% poprawy w stosunku do modelu bazowego. W sześciu z dziesięciu testów SOUL pobił GPT-4o - model uznawany za jeden z najsilniejszych na rynku. 'DITTO osiąga średnio 36% poprawy w stosunku do modelu bazowego i przewyższa GPT-4o w 6 z 10 testów SOUL' - podsumowują autorzy. To realna przewaga werbalnej informacji zwrotnej nad tradycyjnym uczeniem przez skalarne nagrody.
Szczególnie dobrze poszło mu w zadaniach wymagających teorii umysłu i umiejętności społecznych - czyli tam, gdzie niuanse językowe mają największe znaczenie. To sugeruje, że model nie tylko zapamiętał poprawne odpowiedzi, ale rzeczywiście wykształcił coś na kształt społecznego wyczucia. Badacze konkludują: 'RL z werbalną informacją zwrotną to obiecujący kierunek trenowania LLM-ów do symulowania ludzkich zachowań'.
- Werbalna informacja zwrotna zastępuje liczbowe nagrody, oddając wielowymiarowość ludzkich ocen.
- DITTO uczy się na słownych komentarzach, ale nie potrzebuje ich podczas testowania - wiedza jest internalizowana.
- Model osiąga 36% poprawy nad bazą i wygrywa z GPT-5.4 w większości zadań benchmarku SOUL.
- SOUL to pierwszy kompleksowy zestaw testów symulacji ludzkich zachowań, obejmujący 10 zadań w 6 kategoriach.
Praktyczne zastosowania
Aby lepiej zrozumieć opisywaną innowację, przygotowaliśmy cztery przykłady praktycznego zastosowania tej technologii w różnych branżach:




Podsumowanie
DITTO może znaleźć zastosowanie w trenowaniu wirtualnych asystentów, by lepiej rozumieli niuanse społeczne, w symulacjach edukacyjnych, gdzie AI wciela się w ucznia o określonych potrzebach, oraz w testowaniu interfejsów konwersacyjnych - zamiast angażować prawdziwych ludzi, wystarczy model zachowujący się jak człowiek. Technologia ta otwiera drogę do bardziej naturalnych interakcji z AI, szczególnie tam, gdzie sucha poprawność to za mało.
Metryka artykułu źródłowego
Tytuł oryginalny: Reinforcing Human Behavior Simulation via Verbal Feedback
Autorzy: Weiwei Sun, Xuhui Zhou, Jiarui Liu, Weihua Du, Haojia Sun, Yiqing Xie, Qianou Ma, Sihao Chen, Mengting Wan, Longqi Yang, Pei Zhou, Sherry Wu, Sean Welleck, Graham Neubig, Yiming Yang, Maarten Sap
Data publikacji: 21 maja 2026
arXiv: arxiv.org/abs/2605.20506
Napisanie tego artykułu zostało wspomagane przez sztuczną inteligencję. Treść opiera się na oryginalnym artykule naukowym, a jej dokładność została zweryfikowana automatycznie.