
Powtarzalne pytania o kody błędów i procedury naprawcze potrafią sparaliżować nawet sprawny helpdesk. Zespół odbija piłeczkę między instrukcjami PDF a starszymi technikami, a czas pierwszego kontaktu wydłuża się do kilkunastu minut. A gdyby tak każdy agent - i każdy klient na stronie - mógł w kilka sekund dostać diagnozę opartą wyłącznie na waszej wewnętrznej dokumentacji? Model HRM-Text pokazuje, że własny asystent techniczny nie wymaga już milionów na infrastrukturę ani dostępu do zewnętrznego API.
Zamiast miliardów tokenów - pary problem-rozwiązanie
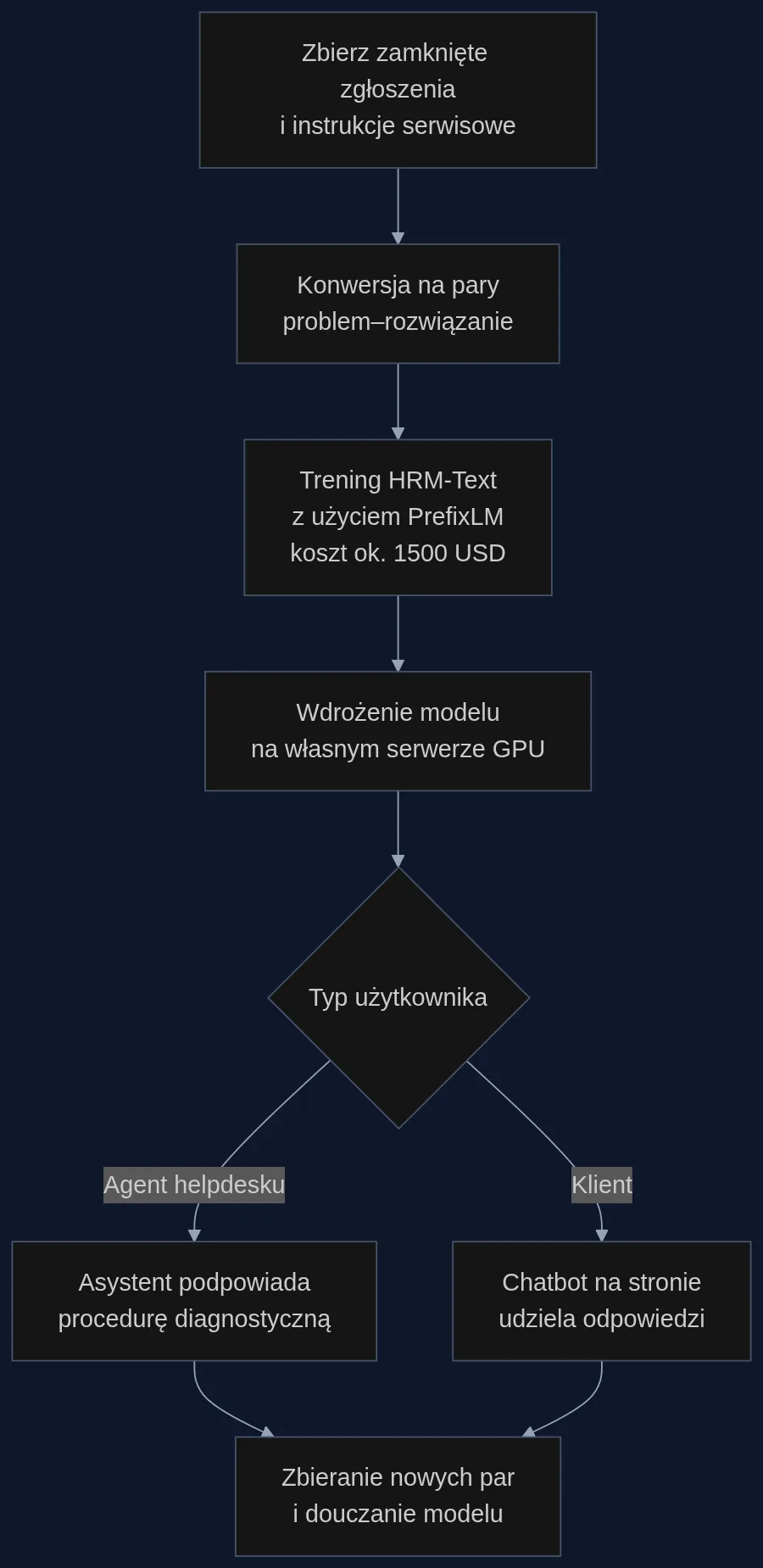
Wsparcie techniczne produktów opiera się na gotowych ścieżkach: 'jeśli wystąpi błąd X, sprawdź Y, jeśli nie pomoże, wykonaj Z'. Te ścieżki są już opisane w instrukcjach serwisowych i w setkach zamkniętych zgłoszeń helpdesku. Problem w tym, że standardowe duże modele językowe potrzebują setek miliardów tokenów luźnego tekstu, by w ogóle zacząć rozumieć kontekst - a potem i tak nie znają specyfiki waszych urządzeń.
Zespół Guana Wanga pokazał architekturę, która odwraca tę logikę. Hierarchiczny model rekurencyjny (HRM) uczy się wyłącznie na parach instrukcja-odpowiedź. Zamiast wchłaniać internet, dostaje sformatowane dane: 'Klient pyta o błąd E23 w pralce X200 → Odpowiedź: sprawdź filtr pompy, następnie czujnik ciśnienia, kod części…'. To wystarczy, by model o miliardzie parametrów osiągnął wyniki porównywalne z modelami 2-7 mld parametrów, zużywając przy tym 100-900 razy mniej tokenów. Cały trening od zera zamyka się w 1500 dolarów.
Scenariusz: helpdesk producenta sprzętu przemysłowego
Weźmy firmę z 3 tysiącami aktywnych zgłoszeń miesięcznie i bazą 1200 artykułów serwisowych. Każdy agent spędza średnio 6 minut na szukaniu odpowiedniej procedury - pomiędzy wewnętrznym wiki, PDF-ami a pytaniami do inżynierów.
Wdrażamy model HRM-Text wyszkolony od zera na 15 tysiącach par 'problem-rozwiązanie', wyciągniętych z zamkniętych ticketów i instrukcji. Trening na jednej karcie GPU A100 trwa niecałe trzy dni, koszt ok. 1500 USD. Gotowy model wrzucamy na serwer z kartą RTX 4090 (koszt ok. 8000 zł jednorazowo). Od teraz agent wkleja do chatu opis usterki: 'Maszyna CNC XT-5 wyrzuca alarm 401 po wymianie głowicy'. Model zwraca listę trzech prawdopodobnych przyczyn i procedurę diagnostyczną krok po kroku - na podstawie wyłącznie wewnętrznej dokumentacji, bez wycieku do chmury. Czas odpowiedzi: poniżej dwóch sekund.
Tę samą bazę można wystawić jako widget na portalu klienckim. Klient opisuje objawy, a bot podaje kroki, zanim w ogóle utworzy zgłoszenie. W pilotażu u jednego z dystrybutorów maszyn budowlanych taki chatbot zamknął 23% zapytań bez udziału człowieka w pierwszym miesiącu.
ROI, który widać na wyciągu z karty
Przyjmijmy 3000 zgłoszeń miesięcznie, z czego 600 (20%) to powtarzalne pytania o znane usterki. Średni koszt obsługi jednego zgłoszenia w Polsce to ok. 40-60 zł (czas agenta, narzędzia, ewentualna eskalacja). Przejęcie tych 600 ticketów przez bota daje oszczędność rzędu 24 000 - 36 000 zł miesięcznie. Koszt treningu (ok. 5500 zł) zwraca się w pierwszym tygodniu. Dodajmy do tego uniknięte opłaty za API - zewnętrzny model, nawet przy stawce 0,01 USD za zapytanie, przy 5000 zapytań dziennie generowałby rachunek 1500 USD miesięcznie. Własny model na własnym serwerze nie generuje kosztów zmiennych.
Pełna kontrola nad danymi. Dokumentacja techniczna, kody błędów i procedury naprawcze to często know-how firmy. Korzystanie z zewnętrznych API oznacza wysyłanie tych danych na serwery poza jurysdykcją. HRM-Text działa offline, na sprzęcie w waszej serwerowni. Nikt poza wami nie widzi zapytań, a model można dowolnie dostrajać nowymi zgłoszeniami bez udziału zewnętrznego dostawcy.
Od pomysłu do pilotażu w 5 dni
Największa bariera - 'nie mamy ustrukturyzowanych danych' - upada, gdy spojrzy się na zamknięte tickety helpdeskowe. System typu Jira, Zendesk czy Freshdesk przechowuje historię korespondencji: klient opisuje problem, agent wstawia rozwiązanie. Wystarczy wyciągnąć 500-1000 par, oczyścić z danych osobowych i sformatować jako instrukcje. Resztę robi skrypt treningowy. Nawet bez zaawansowanego zespołu data science można w weekend sprawdzić, czy model udziela poprawnych odpowiedzi na 10 najczęstszych pytań.
Rekomendacja na start: zdefiniuj 10 kategorii usterek z największą liczbą zgłoszeń. Przygotuj po 50 par dla każdej, trenuj model przez dwie doby na pojedynczej karcie GPU. Sprawdź jakość odpowiedzi na sucho, potem w pilotażowej grupie agentów. Jeśli trafność przekroczy 80%, rozszerz bazę i udostępnij klientom.
- Samowystarczalny asystent techniczny działa na własnej infrastrukturze - bez opłat za tokeny i bez wycieku danych na zewnątrz.
- Trening tylko na parach problem-rozwiązanie wystarczy, by model poprawnie diagnozował usterki na podstawie instrukcji serwisowych i zamkniętych zgłoszeń.
- Koszt 1500 USD za wytrenowanie modelu od zera zwraca się w kilka dni, gdy bot przejmuje powtarzalne pytania od agentów i klientów.
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: HRM-Text: Efficient Pretraining Beyond Scaling
Autorzy: Guan Wang, Changling Liu, Chenyu Wang, Cai Zhou, Yuhao Sun i in.
The current pretraining paradigm for large language models relies on massive compute and internet-scale raw text, creating a significant barrier to foundational research. In contrast, biological systems demonstrate highly sample-efficient learning through multi-timescale processing, such as the f...
arXiv: arxiv.org/abs/2605.20613
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}