
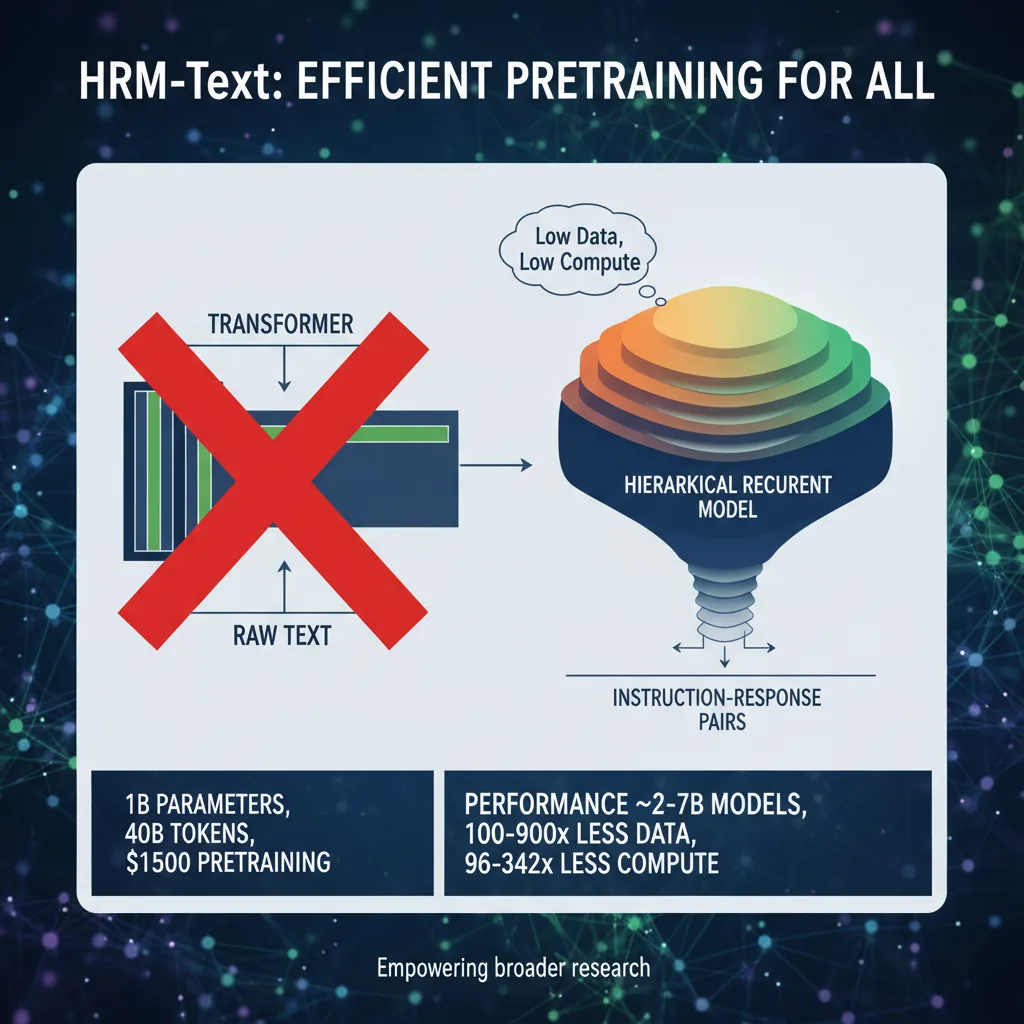
Wytrenować model językowy porównywalny z systemami o miliardach parametrów za równowartość używanego laptopa? Badacze z HRM-Text udowodnili, że to możliwe. Ich model wart miliard parametrów, uczony na 40 miliardach tokenów za jedyne 1500 dolarów, osiąga wyniki zbliżone do otwartych modeli o rozmiarze 2-7 miliardów parametrów - zużywając przy tym setki razy mniej danych i mocy obliczeniowej.
Architektura inspirowana mózgiem: hierarchiczny model rekurencyjny
W HRM-Text nie ma już standardowego transformera. Zastępuje go hierarchiczny model rekurencyjny (HRM), który rozdziela przetwarzanie na dwie skale czasowe: wolną warstwę strategiczną i szybką warstwę wykonawczą. Pomysł zaczerpnięto wprost z neurobiologii - przypomina sposób, w jaki kora przedczołowa (strateg) i ciemieniowa (wykonawca) dzielą zadania w mózgu.
Wolna warstwa analizuje szerszy kontekst, podejmuje decyzje na poziomie całej rozmowy czy dokumentu. Szybka warstwa reaguje na bieżące słowa, generując precyzyjne odpowiedzi. Taki dwupoziomowy rytm pozwala modelowi uczyć się znacznie efektywniej niż płaska architektura złożona z dziesiątek identycznych bloków uwagi.
Autorzy musieli jednak rozwiązać problem stabilności głębokiej rekurencji. Wprowadzili MagicNorm - nową technikę normalizacji - oraz warmup deep credit assignment, czyli metodę stopniowego przypisywania kredytu w sieci. Dzięki nim model nie wpada w pułapkę eksplodujących gradientów i może sięgać po bardzo odległe zależności bez utraty sygnału.
Trening bez surowego tekstu: pary instrukcja-odpowiedź jako nowy paradygmat
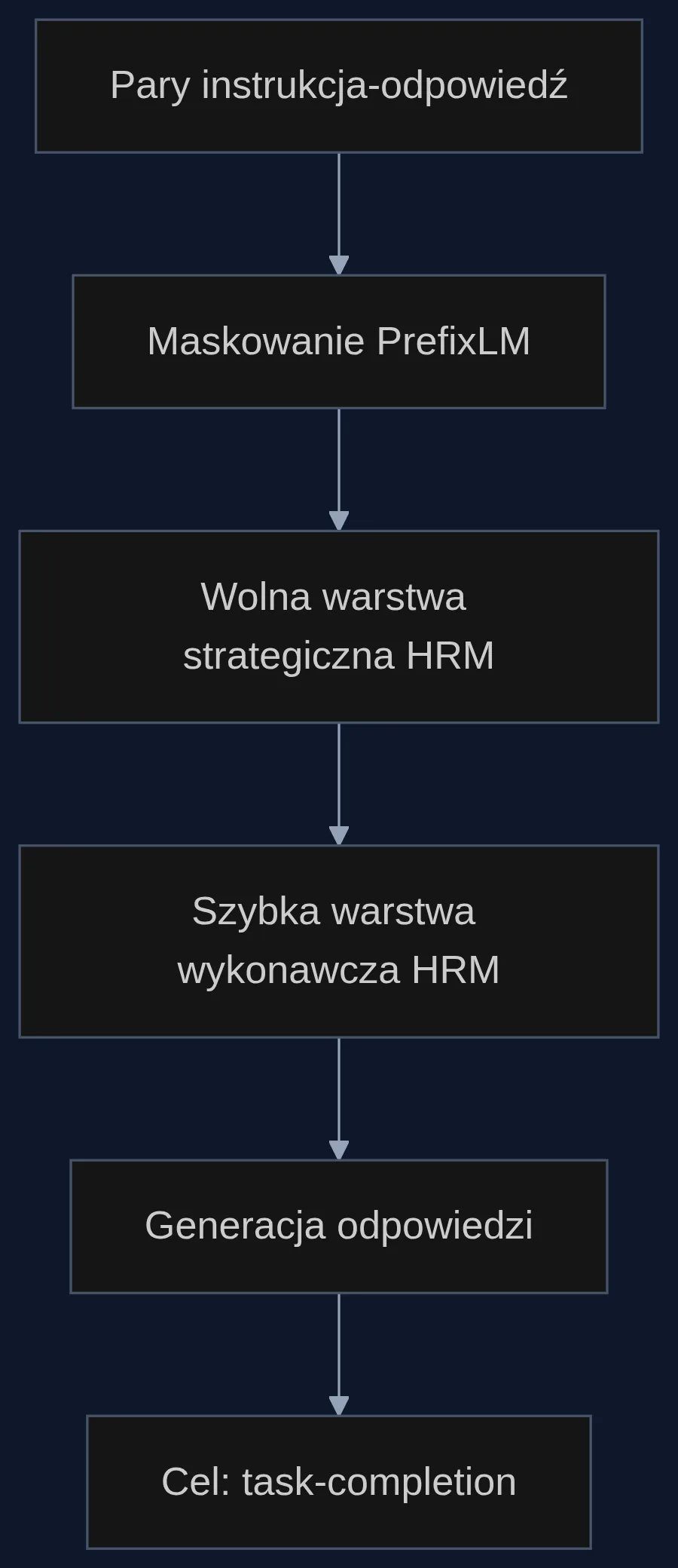
Tradycyjne modele językowe zjadają petabajty nieustrukturyzowanego tekstu - artykułów, książek, stron internetowych - i dopiero potem są dostrajane do konkretnych zadań. Zespół HRM-Text postawił na radykalnie inne podejście: od samego początku model widzi tylko pary instrukcja-odpowiedź, a celem treningu jest uzupełnienie zadania (task-completion), a nie przewidywanie kolejnego tokena w luźnym korpusie.
Do tego użyto maskowania PrefixLM: model otrzymuje instrukcję jako widoczny prefiks, a resztę - swoją odpowiedź - musi wygenerować samodzielnie. To sprawia, że już w fazie pretreningu uczy się podążać za poleceniami, a nie tylko naśladować statystyczny wzorzec języka. W praktyce oznacza to, że każdy token niesie większą wartość informacyjną: zamiast przedzierać się przez setki miliardów przypadkowych zdań, sieć od razu ćwiczy kompetencje potrzebne później użytkownikom.
Mimo wykorzystania około 100-900 razy mniejszej liczby tokenów treningowych i 96-432 razy mniejszej szacowanej mocy obliczeniowej niż standardowe modele bazowe, HRM-Text osiąga wyniki porównywalne z otwartymi modelami o 2-7 miliardach parametrów.
Guan Wang et al.
arXiv:2605.20613
Wyniki, które zaskakują: porównanie z gigantami
Przy budżecie 1500 dolarów i 40 miliardach tokenów HRM-Text zdobył 60,7% na MMLU, 81,9% na ARC-C, 82,2% na DROP, 84,5% na GSM8K i 56,2% na MATH. Współczesne modele open source o 2-7 miliardach parametrów potrzebują do osiągnięcia podobnych rezultatów od 100 do 900 razy więcej tokenów i od 96 do 432 razy więcej obliczeń.
Te liczby przestawiają myślenie o skalowaniu. Nie chodzi o dodawanie kolejnych warstw i dokupowanie kolejnych GPU - często wyższe kompetencje rodzą się z lepszego współgrania architektury i celu uczenia. HRM-Text jest dowodem, że 1 miliard parametrów może stanąć obok 7-miliardowych kolegów, jeśli tylko zrezygnujemy z przerzucania surowego tekstu i przyjmiemy hierarchię w miejsce płaskiej uwagi.
Demokratyzacja pretreningu: co to oznacza dla badaczy i firm
Wytrenowanie własnego modelu językowego od zera do tej pory oznaczało budżety rzędu setek tysięcy dolarów i dostęp do klastrów obliczeniowych. HRM-Text pokazuje, że wystarczy kwota porównywalna z zakupem sprzętu do domowego laboratorium. Dla małych zespołów badawczych i firm to zmiana zasad gry - mogą teraz tworzyć wyspecjalizowane modele bez uzależnienia od ogromnych dostawców chmury.
Co więcej, trening on wyłącznie na parach instrukcja-odpowiedź otwiera drogę do szybkiego budowania asystentów dziedzinowych: modele od razu rozumieją polecenia, nie trzeba ich osobno dostrajać. Wystarczy przygotować odpowiednio sformatowany zbiór zadań z konkretnej branży - medycznej, prawnej czy edukacyjnej - i uruchomić relatywnie tani pretraining.
Nie znaczy to, że HRM-Text zastąpi gigantów wszędzie. Modele o setkach miliardów parametrów wciąż mają przewagę w zadaniach wymagających encyklopedycznej wiedzy. Ale dla precyzyjnego rozumienia instrukcji i rozwiązywania problemów wąsko zdefiniowanych dziedzin, mały model z inteligentną architekturą może być lepszym wyborem niż potwór liczony w tysiącach GPU.
- HRM-Text wykorzystuje hierarchiczny model rekurencyjny zamiast transformera, co radykalnie zmniejsza zapotrzebowanie na dane i obliczenia.
- Model trenowany wyłącznie na parach instrukcja-odpowiedź od razu uczy się wykonywać zadania, pomijając etap przetwarzania surowego tekstu.
- Przy koszcie 1500 dolarów i 40 miliardach tokenów osiąga wyniki porównywalne z modelami 2-7 miliardów parametrów, zużywając 100-900 razy mniej tokenów.
Praktyczne zastosowania
Aby lepiej zrozumieć opisywaną innowację, przygotowaliśmy cztery przykłady praktycznego zastosowania tej technologii w różnych branżach:



Podsumowanie
HRM-Text to nowy punkt odniesienia dla efektywnego pretreningu. Jego architektura i cel uczenia pozwalają firmom tworzyć zaawansowane asystenty dziedzinowe bez ogromnych inwestycji. Można sobie wyobrazić specjalistyczne modele do obsługi zgłoszeń klientów w call center, systemy analizy dokumentów prawnych w kancelariach czy inteligentne korepetytorie uczące się na zbiorze pytań i odpowiedzi z platform e-learningowych - wszystko to przy budżecie liczonym w setkach, a nie tysiącach dolarów.
Metryka artykułu źródłowego
Tytuł oryginalny: HRM-Text: Efficient Pretraining Beyond Scaling
Autorzy: Guan Wang, Changling Liu, Chenyu Wang, Cai Zhou, Yuhao Sun, Yifei Wu, Shuai Zhen, Luca Scimeca, Yasin Abbasi Yadkori
Data publikacji: 21 maja 2026
arXiv: arxiv.org/abs/2605.20613
Napisanie tego artykułu zostało wspomagane przez sztuczną inteligencję. Treść opiera się na oryginalnym artykule naukowym, a jej dokładność została zweryfikowana automatycznie.
{kind=link}