
Wielkie modele językowe radzą sobie świetnie po angielsku, ale kiedy przychodzi do polskiego, arabskiego czy indonezyjskiego, często zawodzą. Naukowcy znaleźli przyczynę w architekturze Mixture-of-Experts i proponują RA-MoE - metodę, która nakierowuje 'ekspertów' modelu na to, co już umieją po angielsku. To nie magia, tylko celowana inżynieria.
Problem: angielskocentryczne eksperty
Wielkie modele językowe radzą sobie świetnie po angielsku, ale kiedy przychodzi do polskiego, arabskiego czy indonezyjskiego, często zawodzą. Naukowcy znaleźli przyczynę w architekturze Mixture-of-Experts i proponują RA-MoE, metodę, która nakierowuje 'ekspertów' modelu na to, co już umieją po angielsku. To celowana inżynieria, nie magia.
Środkowe warstwy kluczem do równości
Modele Mixture-of-Experts (MoE) to architektura, w której wiele wyspecjalizowanych podsieci (ekspertów) aktywuje się tylko wtedy, gdy są potrzebni. Myśl o tym jak o zespole tłumaczy; każdy zna się na swojej dziedzinie, ale żeby skorzystać z ich wiedzy, trzeba odpowiednio do nich trafić. W modelach MoE za to trafianie odpowiada mechanizm trasowania.
Problem w tym, że trasowanie trenowane jest głównie na danych angielskich. Kiedy model dostaje zdanie po polsku, trasowanie często wybiera nie tych ekspertów, co trzeba. Efekt? Model po angielsku odpowiada poprawnie, a po polsku plecie bzdury, mimo że ogólna wiedza jest ta sama. To jakby dyspozytor w międzynarodowej firmie rozumiał tylko angielskie opisy zadań.
Guanzhi Deng i współpracownicy zbadali ten fenomen i odkryli coś zaskakującego: nie chodzi o to, że model nie zna polskiego, tylko o to, że nie potrafi przekierować pytania do właściwych ekspertów, gdy język się zmienia.
Środkowe warstwy tworzą uniwersalną językowo strefę wyrównania, gdzie rozbieżność trasowania silnie przewiduje różnice w wydajności między językami.
Guanzhi Deng i współpracownicy
Abstract
RA-MoE: trzyetapowe uczenie
Przyglądając się, jak modele MoE przetwarzają różne języki, autorzy znaleźli coś, co nazwali uniwersalną językowo strefą wyrównania. Chodzi o środkowe warstwy sieci, te, które nie zajmują się ani wstępnym rozpoznawaniem słów, ani finalną generacją odpowiedzi. W tych warstwach rozbieżność trasowania między angielskim a innym językiem okazała się silnym predyktorem różnic w wydajności.
Wyobraź sobie, że te środkowe warstwy działają jak uniwersalny tłumacz: jeśli tutaj wybór ekspertów jest podobny dla angielskiego i polskiego, model radzi sobie porównywalnie w obu językach. Jeśli się rozjeżdża, polski kuleje. To odkrycie dało naukowcom punkt zaczepienia: można poprawić działanie modelu w wielu językach, nie ucząc go wszystkiego od nowa, tylko naprawiając trasowanie w tych środkowych warstwach.
'Środkowe warstwy tworzą uniwersalną językowo strefę wyrównania, gdzie rozbieżność trasowania silnie przewiduje różnice w wydajności między językami', piszą autorzy w abstrakcie. To zdanie jest osią, wokół której zbudowali całą metodę.
Kiedy naprawa się opłaca?
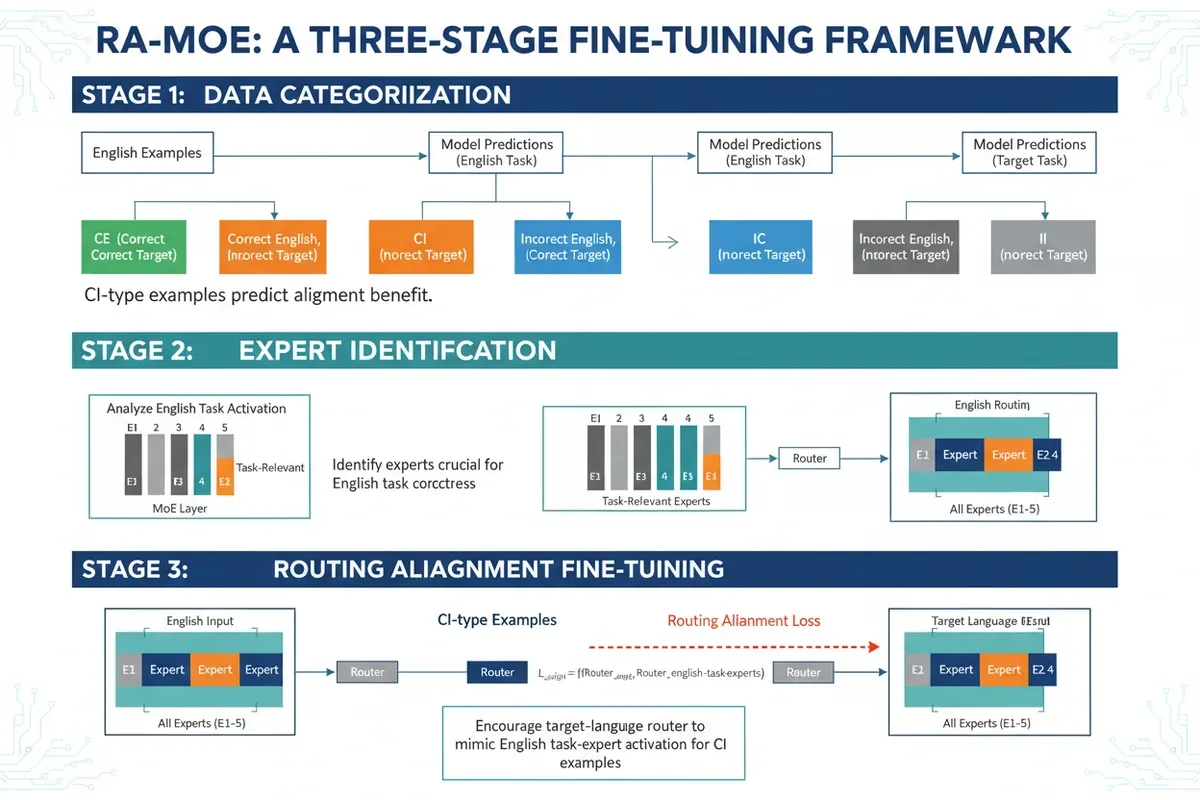
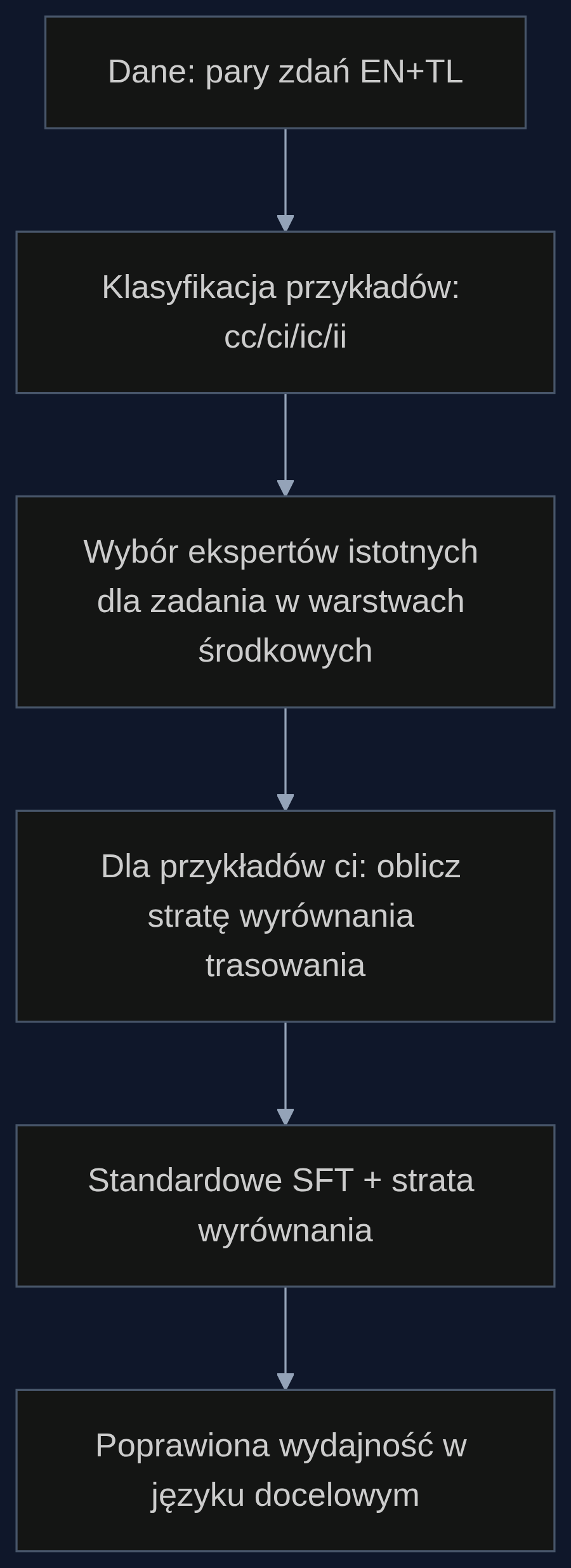
RA-MoE (Routing-Aligned Fine-Tuning) to proces składający się z trzech etapów. Pierwszy to klasyfikacja przykładów na cztery typy: obie odpowiedzi poprawne (cc), angielski dobrze, docelowy źle (ci), angielski źle, docelowy dobrze (ic), obie źle (ii). Najważniejsze są te ci, to one pokazują, gdzie model ma wiedzę, ale nie potrafi jej zastosować w innym języku.
Drugi etap to identyfikacja ekspertów istotnych dla zadania w środkowych warstwach, na podstawie przykładów angielskich. Następnie, podczas douczania, dodawana jest dodatkowa strata, routing alignment loss. Dla przykładów typu ci system jest karany, jeśli trasowanie w języku docelowym nie naśladuje wzorca aktywacji ekspertów z angielskiego. Innymi słowy, model uczy się: 'skoro już wiesz, kto jest potrzebny po angielsku, użyj tej samej ścieżki dla polskiego'.
'Udział przykładów typu ci w parze zadanie-język jest wiarygodnym predyktorem korzyści z wyrównania trasowania', czytamy dalej w abstrakcie. To znaczy, że przed uruchomieniem czasochłonnego treningu można szybko oszacować, czy RA-MoE w ogóle pomoże w danym przypadku.
- Modele MoE świetnie się skalują, ale wąskim gardłem jest trasowanie - po angielsku działa dobrze, w innych językach często losowo.
- Środkowe warstwy sieci pełnią rolę uniwersalnej strefy: im większa rozbieżność trasowania, tym gorsza wydajność w danym języku.
- RA-MoE klasyfikuje przykłady na cztery typy i dla tych, gdzie model myli się tylko w języku docelowym, nakazuje naśladować angielski wzorzec ekspertów.
- Metoda poprawia wyniki w 6 językach i 3 zadaniach, a współczynnik ci pozwala przewidzieć, kiedy ją zastosować.
Praktyczne zastosowania
Aby lepiej zrozumieć opisywaną innowację, przygotowaliśmy cztery przykłady praktycznego zastosowania tej technologii w różnych branżach:




Podsumowanie
RA-MoE może pomóc firmom budować asystenty AI, które równie dobrze pomagają klientom w Tokio, Warszawie i Kairze, bez kosztownego douczania od zera dla każdego języka. W e-commerce automatyczne moderowanie opinii w kilkudziesięciu językach stanie się bardziej wiarygodne, a w sektorze finansowym analiza dokumentów w językach rzadziej reprezentowanych dostanie solidniejsze podstawy. Wystarczy policzyć udział ci w danych, by stwierdzić, czy inwestycja w RA-MoE ma sens.
Metryka artykułu źródłowego
Tytuł oryginalny: Routing-Aligned Fine-Tuning for Multilingual Downstream Tasks in Mixture-of-Experts Models
Autorzy: Guanzhi Deng, Kuan Wu, Haibo Wang, Shing Yin Wong, Sichun Luo, Linqi Song
Data publikacji: 28 maja 2026
arXiv: arxiv.org/abs/2605.28306
Napisanie tego artykułu zostało wspomagane przez sztuczną inteligencję. Treść opiera się na oryginalnym artykule naukowym, a jej dokładność została zweryfikowana automatycznie.
{kind=link}