
Wyobraź sobie, że rozwiązujesz trudne sudoku. Nie wypełniasz go w jednym błyskawicznym ruchu - analizujesz, wracasz do poprzednich pól, skreślasz błędne ścieżki. Nowe podejście do sztucznej inteligencji, nazwane Equilibrium Reasoners, uczy sieci neuronowe robić dokładnie to samo. Zamiast produkować odpowiedź od razu, model iteruje, dochodząc do stabilnego rozwiązania niczym kulka wtaczająca się do dołka.
Koniec z jednorazowym strzałem
Standardowe sieci neuronowe działają jak maszyny do rzutek - dostają dane na wejściu i w jednym przejściu generują wynik. W przypadku prostego rozpoznawania obrazów to działa świetnie, ale przy zadaniach wymagających logicznego wnioskowania, takich jak zaawansowane sudoku, tradycyjne modele feedforward osiągają zaledwie 2,6% dokładności. To mniej więcej tyle, co strzelanie na oślep.
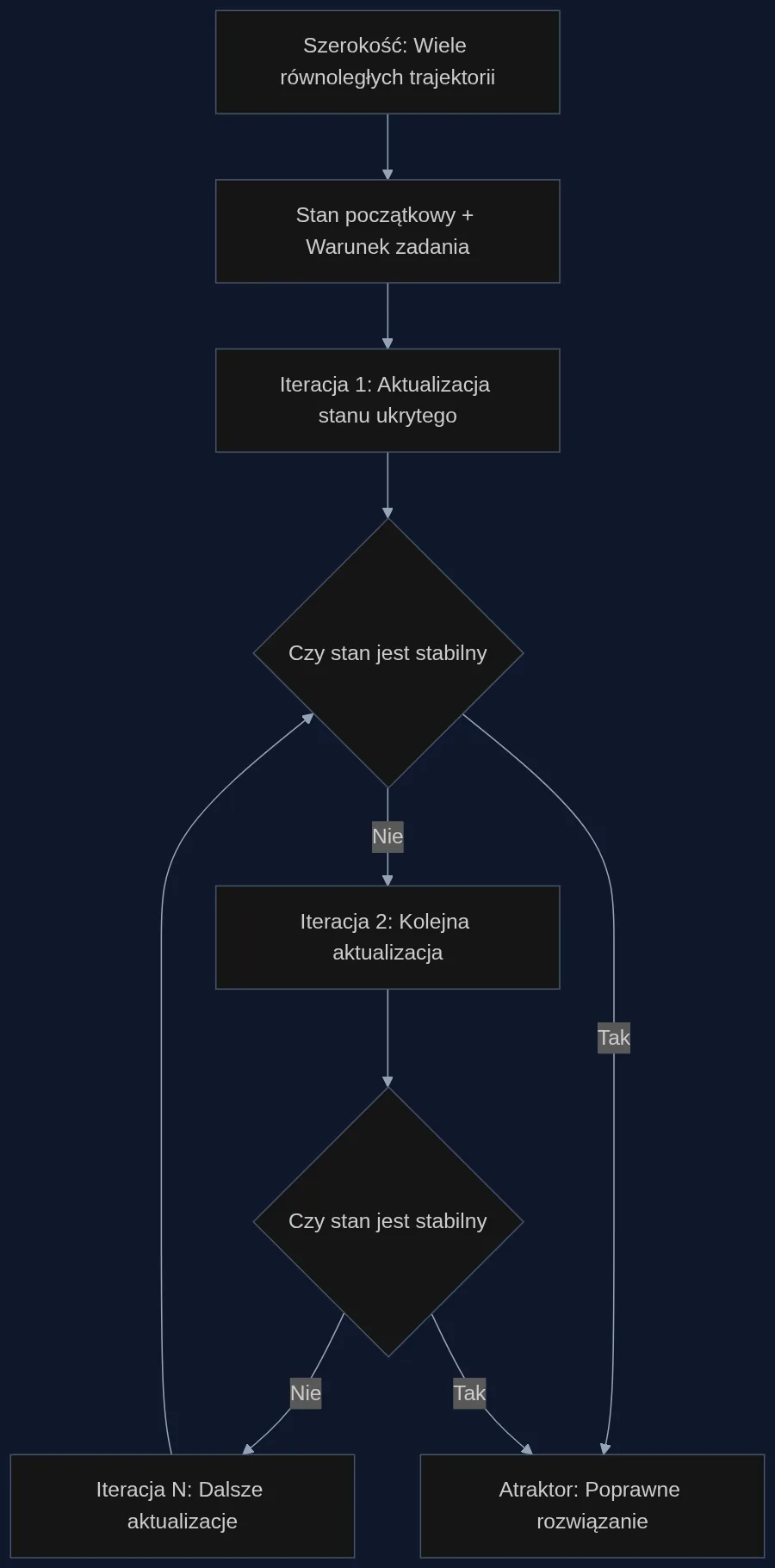
Benhao Huang, Zhengyang Geng i Zico Kolter zapytali: co, jeśli proces myślenia to nie pojedynczy skok, ale wędrówka po krajobrazie możliwości? Ich odpowiedzią są Equilibrium Reasoners (EqR) - sieci, które uczą się nie tyle 'odpowiedzi', co ścieżek dojścia do niej. Model dostaje stan początkowy i warunek zadania, a następnie, krok po kroku, aktualizuje swoją wewnętrzną reprezentację, aż trafi na stabilny punkt - atraktor - który odpowiada poprawnemu rozwiązaniu.
Atraktory - magnesy dla poprawnego rozwiązania
W fizyce atraktor to stan, do którego układ dąży niezależnie od punktu startowego. Przykładem jest wahadło - nieważne, jak mocno je wychylisz, zawsze skończy zwisając pionowo w dół. Autorzy pracy piszą: 'uogólnione wnioskowanie wynika z uczenia się atraktorów uwarunkowanych zadaniem - ukrytych układów dynamicznych, których stabilne punkty stałe odpowiadają poprawnym rozwiązaniom'.
W praktyce oznacza to, że sieć neuronowa podczas treningu kształtuje w swojej ukrytej przestrzeni 'baseny przyciągania' dla każdego możliwego zadania. Gdy w czasie testowania dostaje nową łamigłówkę, jej wewnętrzny stan zaczyna ewoluować, przyciągany przez odpowiedni atraktor. Proste przypadki znajdują rozwiązanie w 1-5 iteracjach. Trudne - wymagają głębszej eksploracji, ale mechanizm pozostaje ten sam.
Stawiamy hipotezę, że uogólnione wnioskowanie wynika z uczenia się atraktorów uwarunkowanych zadaniem - ukrytych układów dynamicznych, których stabilne punkty stałe odpowiadają poprawnym rozwiązaniom.
Benhao Huang, Zhengyang Geng, Zico Kolter
Abstract, arXiv:2605.21488
Skalowanie na dwa sposoby: głębokość i szerokość
EqR oferują elastyczność w zarządzaniu mocą obliczeniową. Zamiast sztywno ustalonej architektury, model może 'myśleć dłużej' nad trudniejszymi problemami. Autorzy wyróżniają dwa wymiary tego skalowania:
Głębokość to po prostu zwiększanie liczby iteracji - pozwolenie układowi na dłuższą wędrówkę po krajobrazie atraktorów. Szerokość to uruchomienie wielu niezależnych trajektorii z różnych punktów startowych i agregacja wyników. Obie metody nie wymagają zewnętrznych weryfikatorów ani ręcznie projektowanych strategii - są naturalną konsekwencją dynamiki układu. W eksperymentach na Sudoku-Extreme, 'rozwijając sieć do równowartości 40 000 warstw, skalowalne wnioskowanie latentne podniosło dokładność z 2,6% dla modeli feedforward do ponad 99%'.
Adaptacyjne myślenie bez zewnętrznego nadzoru
EqR nie potrzebują zewnętrznego sędziego oceniającego poprawność wyniku. W popularnych podejściach, takich jak chain-of-thought, model generuje tok rozumowania, który jest następnie weryfikowany. Tutaj weryfikacja jest wbudowana w samą dynamikę - atraktor jest z definicji stanem stabilnym, więc model 'wie', że dotarł do celu, gdy kolejne iteracje nie zmieniają już wyniku.
Jak ujmują to autorzy: 'Perspektywa atraktorowa pozwala sieciom neuronowym adaptacyjnie przydzielać obliczenia w zależności od trudności zadania'. Model nie marnuje energii na proste przypadki, a jednocześnie nie poddaje się przy tych wymagających głębszego namysłu.
- Tradycyjne sieci neuronowe rozwiązują Sudoku-Extreme ze skutecznością 2,6% - Equilibrium Reasoners osiągają ponad 99%.
- Wnioskowanie to iteracyjny proces dochodzenia do stabilnego punktu (atraktora), a nie jednorazowa odpowiedź.
- Model może skalować głębokość (liczba iteracji) i szerokość (liczba trajektorii) bez zewnętrznych weryfikatorów.
- Proste przypadki rozwiązują się w 1-5 iteracjach, trudne wymagają nawet równowartości 40 000 warstw.
- Mechanizm atraktorów wbudowuje weryfikację w dynamikę układu - stabilność oznacza poprawność.
Praktyczne zastosowania
Aby lepiej zrozumieć opisywaną innowację, przygotowaliśmy cztery przykłady praktycznego zastosowania tej technologii w różnych branżach:




Podsumowanie
Equilibrium Reasoners to nie tylko ciekawostka z laboratorium. Ich zdolność do adaptacyjnego skalowania obliczeń otwiera drzwi do systemów, które same decydują, ile 'namysłu' potrzebują. W logistyce mogłyby rozwiązywać złożone problemy optymalizacyjne, takie jak układanie tras dostaw z wieloma ograniczeniami. W cyberbezpieczeństwie - analizować sekwencje zdarzeń w poszukiwaniu ukrytych wzorców ataków. A w diagnostyce medycznej - iteracyjnie doprecyzowywać diagnozę na podstawie częściowych danych, zamiast zgadywać na podstawie pierwszego wrażenia. Wspólnym mianownikiem są zadania, gdzie jakość odpowiedzi rośnie wraz z czasem poświęconym na jej wypracowanie.
Metryka artykułu źródłowego
Tytuł oryginalny: Equilibrium Reasoners: Learning Attractors Enables Scalable Reasoning
Autorzy: Benhao Huang, Zhengyang Geng, Zico Kolter
Data publikacji: 21 maja 2026
arXiv: arxiv.org/abs/2605.21488
Napisanie tego artykułu zostało wspomagane przez sztuczną inteligencję. Treść opiera się na oryginalnym artykule naukowym, a jej dokładność została zweryfikowana automatycznie.