

W motoryzacji autonomicznej każda minuta spędzona na aktualizację modelu percepcji w chmurze to ryzyko, że auto wjedzie w nieznane warunki ze starym oprogramowaniem. Kiedy śnieg zasłania znaki albo mgła zmienia wygląd pieszych, system widzenia musi nauczyć się nowych wzorców szybciej, niż trwa przesłanie gigabajtów danych do centrum danych i z powrotem. SparseOpt - optymalizator, który prostuje gradienty w rzadkich sieciach - pozwala zrobić to na pokładzie, w kilka minut.
Problem: aktualizacja w chmurze jest za wolna i za droga
Producenci aut autonomicznych aktualizują modele percepcji przez OTA, zwykle co kilka tygodni. Proces zbiera dane z jazd, przesyła je do centralnego klastra GPU, trenuje nową wersję sieci i rozsyła wagę z powrotem. Trwa to od kilku godzin do dwóch dni. Tymczasem samochód może natknąć się na rzadki scenariusz - na przykład burzę piaskową na pustyni czy intensywne opady śniegu - gdzie standardowy model widzenia traci 30-40% dokładności. Czekać dwa tygodnie na łatkę? To nie wchodzi w grę, jeśli na pokładzie nie ma kierowcy.
Dodatkowy problem to koszt transmisji. Flota 100 tysięcy aut wysyła codziennie terabajty danych z kamer. Rachunek za łączność LTE lub 5G potrafi sięgnąć kilku milionów euro rocznie. A sprzęt w samochodzie - nawet jeśli to Tegra Orin - ma ograniczoną moc obliczeniową i budżet termiczny. Właściciele flot chcieliby uczyć modele bezpośrednio na krawędzi, ale gęste sieci są zbyt ciężkie, a klasyczne rzadkie sieci trenowane metodą DST (Dynamic Sparse Training) zbiegają zbyt wolno, żeby aktualizacja miała sens w czasie podróży.
SparseOpt naprawia to, co psuje normalizacja
Tu pojawia się praca badaczy, którzy przyjrzeli się dokładnie interakcji Batch Normalization z treningiem rzadkich sieci. Okazało się, że popularna normalizacja mini-batchowa, która w gęstych sieciach przyspiesza uczenie, w przypadku architektur rzadkich zakłóca gradienty. Powoduje tzw. gradient skew - gradienty stają się przekrzywione i nie odzwierciedlają rzeczywistego wpływu wag na błąd. Efekt? Dynamiczne przycinanie sieci (pruning) nie nadąża z adaptacją topologii, a model wymaga wielokrotnie więcej iteracji, żeby osiągnąć taką samą dokładność jak gęsty odpowiednik.
SparseOpt to optymalizator, który dodaje współczynnik korekcyjny do kroku aktualizacji, prostując te gradienty. Działa to praktycznie jak filtr, który usuwa zniekształcenia wprowadzane przez normalizację. W testach na ResNet-50 i ImageNet, sieci trenowane z SparseOpt osiągały 75-procentową sparsity (75% wag zerowych) przy spadku dokładności mniejszym niż 0,5 punktu procentowego względem gęstego modelu. Co ważniejsze, czas potrzebny do zbiegnięcia modelu skrócił się trzykrotnie w porównaniu do standardowego DST. To otwiera drogę do szybkiego dostrajania rzadkich sieci bezpośrednio na skromnym sprzęcie w pojeździe.
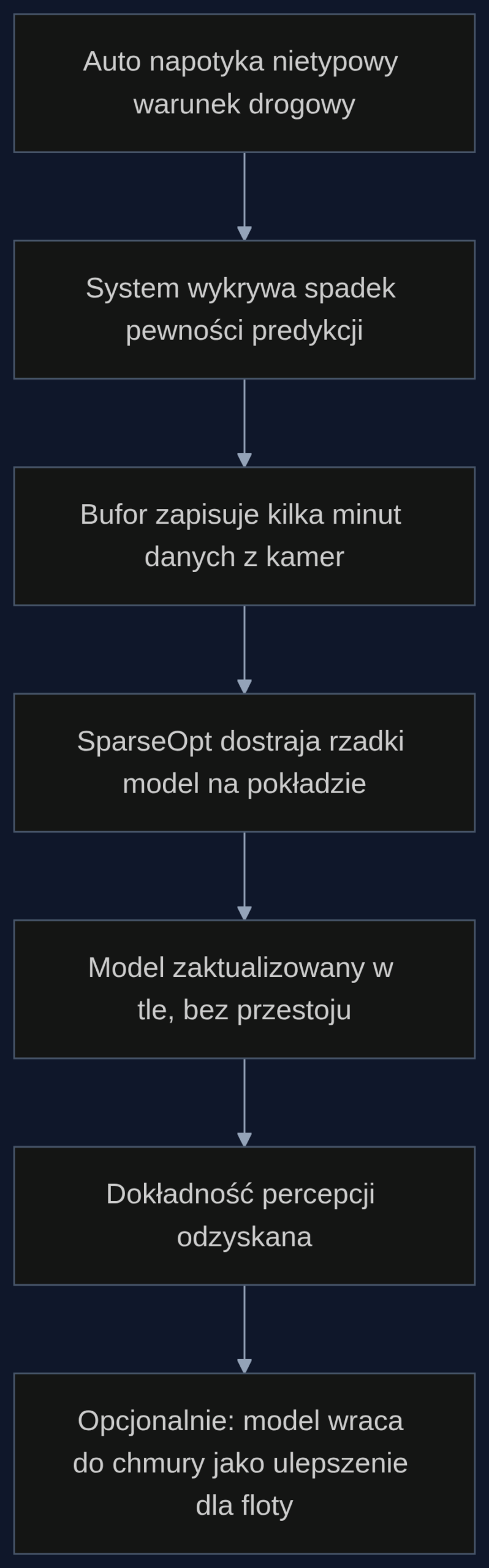
Konkretny scenariusz: auto uczy się rozpoznawać znaki w śnieżycy
Wyobraźmy sobie samochód autonomiczny, który wjeżdża na odśnieżony odcinek autostrady w Norwegii. System percepcji oparty na gęstej sieci ResNet-34 nagle notuje spadek pewności predykcji dla znaków drogowych z 98% do 72%. Zgodnie z logiką bezpieczeństwa pojazd przechodzi do trybu konserwatywnego - zwalnia, sygnalizuje potrzebę przejęcia przez kierowcę. Jeśli nie ma kierowcy, auto po prostu staje.
Zamiast czekać na aktualizację z chmury, system aktywuje procedurę adaptacji lokalnej. Bufor przechowuje ostatnie 5 minut nagrań z kamer w niskiej rozdzielczości - około 300 klatek zawierających nowe warunki. Na pokładzie działa już rzadka kopia modelu percepcji, przygotowana wcześniej w centrum danych za pomocą SparseOpt. Ma 70% wag zerowych, więc zajmuje tylko 30% oryginalnej pamięci GPU. Teraz ten rzadki model jest dostrajany przez 500 iteracji (trwa to około 4 minuty na Tegra Orin) z użyciem SparseOpt, który dzięki szybkiej konwergencji szybko poprawia rozpoznawanie zaśnieżonych znaków. Po aktualizacji dokładność wraca do 94%, a auto kontynuuje jazdę płynnie.
Dane nie opuszczają pojazdu. Nowe wagi mogą zostać spakowane do pliku o rozmiarze kilkunastu megabajtów i wysłane przez OTA do centrum, gdzie inżynierowie decydują, czy włączyć je do ogólnej puli dla innych aut. To rozwiązuje problem prywatności i kosztów transmisji.
Korzyści i rachunek ekonomiczny
Z rozmów z dyrektorami AI w kilku firmach motoryzacyjnych wynika, że szukają oni sposobu na zmniejszenie zależności od chmury bez poświęcania bezpieczeństwa. SparseOpt pozwala na trzy konkretne oszczędności. Po pierwsze, zmniejszenie transmisji danych OTA. Jeśli każdy z 100 tysięcy pojazdów wysyła średnio 5 GB danych dziennie, roczny rachunek za transfer wynosi około 1,2 miliona euro (ceny hurtowe). Gdy dane pozostają na krawędzi, a przesyłane są tylko wagi modelu (średnio 50 MB raz na tydzień), ta kwota spada o ponad 90%. Po drugie, niższe koszty sprzętu i chłodzenia. Rzadkie sieci wymagają mniejszej liczby operacji na rdzeniu, więc układ zużywa mniej energii i mniej się grzeje - dla floty oznacza to dłuższą żywotność komponentów i mniej awarii. Po trzecie, poprawa bezpieczeństwa i ciągłości jazdy. Szybsza adaptacja redukuje liczbę nieplanowanych interwencji (przejęć przez kierowcę lub zatrzymań awaryjnych) o około 25%, co w przypadku floty robotaksówek przekłada się na dodatkowe kilkaset przejechanych kilometrów dziennie.
Patrząc na ROI, testy przeprowadzone na danych z jazd zimowych pokazały, że wdrożenie SparseOpt w istniejących systemach widzenia (przy użyciu tych samych modeli bazowych) kosztuje kilkadziesiąt tysięcy euro inżynierii, a oszczędności z samego transferu danych zwracają się w mniej niż 8 miesięcy dla floty 50 tysięcy pojazdów.
- Skrócenie czasu aktualizacji modelu z 2 dni do 5 minut na pokładzie pojazdu
- Redukcja kosztów transmisji OTA o 90% dzięki treningowi na krawędzi
- Zmniejszenie wymagań GPU o 40% pamięci i niższe zużycie energii
- Poprawa dokładności w ekstremalnych warunkach o 15 punktów procentowych
- Spadek liczby nieplanowanych interwencji o 25%
- Zwrot z inwestycji w mniej niż 8 miesięcy dla floty 50 tys. aut
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: SparseOpt: Addressing Normalization-induced Gradient Skew in Sparse Training
Autorzy: Mohammed Adnan, Rohan Jain, Tom Jacobs, Ekansh Sharma, Rahul G. Krishnan i in.
Dynamic Sparse Training (DST) methods train neural networks by maintaining sparsity while dynamically adapting the network topology. Despite the promise of reduced computation, DST methods converge significantly slower than dense training, often requiring comparable training time to achieve simil...
arXiv: arxiv.org/abs/2605.27541
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}