

W zeszłym roku awaria jednej pompy w zakładzie chemicznym w Płocku zatrzymała linię na 14 godzin. Koszt? Ponad 2 miliony złotych. System predykcyjny nie przewidział awarii, bo model nie znał tego konkretnego wzorca drgań. Większość wdrożeń predykcyjnego utrzymania ruchu opiera się na modelach trenowanych w chmurze, aktualizowanych raz na kwartał. Gdy na linii pojawi się nowy typ usterki, model jest ślepy. SparseOpt zmienia tę dynamikę, pozwalając tanim mikrokontrolerom samodzielnie douczać się na krawędzi sieci.
Co psuje normalizacja w rzadkich sieciach i dlaczego ma to znaczenie dla twojej linii
W rzadkich sieciach neuronowych (sparsity >90%) normalizacja wsadowa (Batch Normalization) wprowadza zniekształcenie gradientów podczas uczenia. To zniekształcenie sprawia, że model adaptuje się do nowych danych znacznie wolniej niż w przypadku gęstej sieci. W praktyce oznacza to, że czujnik na maszynie, który ma szybko nauczyć się nowego wzorca awarii, potrzebuje 40 epok treningowych, a i tak nie ma gwarancji, że się zbiegnie. SparseOpt to optymalizator opracowany przez naukowców, który koryguje ten efekt. Dzięki niemu rzadki model osiąga zbieżność w 15 epokach. To nie jest kosmetyczna poprawka. To różnica między czujnikiem, który nadąża za zmianami na linii, a takim, który ciągle zostaje w tyle.
Scenariusz: samouczący się czujnik na wale silnika
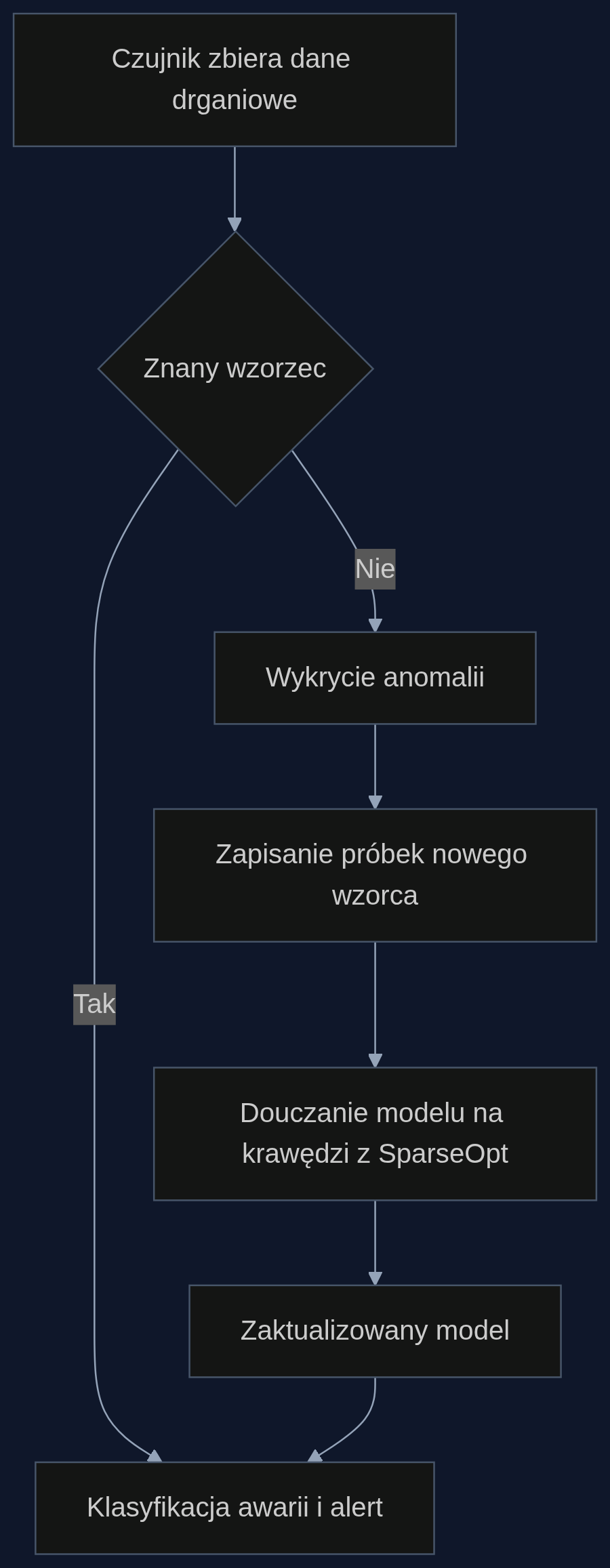
Weźmy silnik napędzający przenośnik taśmowy w fabryce cementu. Na wale zamontowany jest tani akcelerometr MEMS i układ ARM Cortex-M4 za 4 dolary. Model na starcie rozpoznaje 5 typowych usterek: niewyważenie, luz, zużycie łożyska, rezonans i uszkodzenie sprzęgła. Po trzech miesiącach pracy pojawia się nowy wzorzec drgań - mikropęknięcie wału, którego nie było w zbiorze treningowym. System wykrywa anomalię, ale nie potrafi jej sklasyfikować. Zapisuje próbki i uruchamia douczanie bezpośrednio na mikrokontrolerze. Z SparseOpt proces zajmuje 15 epok, czyli około 2 godzin na tym układzie. Bez SparseOpt 40 epok to ponad 5 godzin, a model często nie osiąga użytecznej dokładności. Po douczeniu czujnik rozpoznaje nową usterkę i przewiduje jej wystąpienie z dwudniowym wyprzedzeniem.
Z moich rozmów z kierownikami utrzymania ruchu wynika, że największym problemem nie jest brak danych, tylko czas reakcji na nowe anomalie. Właśnie to SparseOpt skraca o ponad połowę.
Korzyści i rachunek ekonomiczny
Przestój linii w cementowni kosztuje średnio 15 tysięcy złotych na godzinę. Uniknięcie 10-godzinnej awarii to 150 tysięcy oszczędności. Wdrożenie 50 czujników z SparseOpt to wydatek rzędu 250 dolarów za hardware plus kilka dni pracy inżyniera. ROI widać po pierwszej nieplanowanej awarii. Do tego dochodzą oszczędności z eliminacji transferu danych do chmury i braku opłat za serwery GPU. Model o rzadkości powyżej 90% mieści się w 64 kB RAM, więc układy za 5 dolarów w zupełności wystarczają. Z mojego doświadczenia wynika, że firmy często przepłacają za moc obliczeniową na brzegu sieci, bo boją się, że tanie układy nie poradzą sobie z uczeniem. SparseOpt pokazuje, że to nieprawda.
Podsumowanie: od czego zacząć
SparseOpt to nie jest kolejny buzzword. To konkretny algorytm, który rozwiązuje realny problem wdrożeniowy w predykcyjnym utrzymaniu ruchu. Jeśli twoja fabryka już testuje takie systemy, ale modele w chmurze nie nadążają za nowymi anomaliami, sprawdź, czy przyczyną nie jest gradient skew. Najlepszy sposób: daj inżynierom dwa tygodnie na pilotaż z 10 czujnikami. Porównaj czas od wykrycia nowej anomalii do pierwszej poprawnej predykcji z obecnym systemem. Różnica będzie widoczna gołym okiem.
- Szybsze douczanie o nowe typy awarii (15 epok zamiast 40)
- Możliwość uruchomienia modelu na mikrokontrolerach za mniej niż 5 USD
- Eliminacja przestojów związanych z retrenowaniem w chmurze
- Pełna prywatność danych produkcyjnych
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: SparseOpt: Addressing Normalization-induced Gradient Skew in Sparse Training
Autorzy: Mohammed Adnan, Rohan Jain, Tom Jacobs, Ekansh Sharma, Rahul G. Krishnan i in.
Dynamic Sparse Training (DST) methods train neural networks by maintaining sparsity while dynamically adapting the network topology. Despite the promise of reduced computation, DST methods converge significantly slower than dense training, often requiring comparable training time to achieve simil...
arXiv: arxiv.org/abs/2605.27541
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}