

Co trzeci pacjent z cukrzycą typu 1 doświadcza objawów depresji, a wypalenie cukrzycowe podwaja ryzyko powikłań. Dzisiejsze systemy CGM generują dziesiątki alertów dziennie, ale żaden nie mówi lekarzowi: 'Ten pacjent traci motywację'. Technologia TimeSRL zmienia strumień surowych danych w opowieść, która potrafi to wychwycić.
Problem, którego nie widać w wynikach HbA1c
Diabetolog przegląda raport z CGM. Widzi 14-dniowy wykres glikemii, kilka nocnych hipoglikemii, średnią 156 mg/dl. To, czego nie widzi, to fakt, że pacjent od tygodnia śpi po 5 godzin, przestał wychodzić z domu, a każdy alert o wysokim cukrze ignoruje. Wypalenie cukrzycowe - stan wyczerpania psychicznego związany z ciągłym zarządzaniem chorobą - rozwija się poza zasięgiem standardowych metryk. Kwestionariusze PHQ-4 są wypełniane raz na kwartał, jeśli w ogóle. Tymczasem pacjent z nierozpoznaną depresją ma dwukrotnie wyższe ryzyko hospitalizacji z powodu kwasicy ketonowej.
Od strumienia liczb do opowieści dnia
TimeSRL to dwustopniowy framework oparty na dużym modelu językowym, który naśladuje pracę doświadczonego edukatora diabetologicznego. W pierwszym etapie pobiera 14-dniowe okno danych - nie tylko z CGM, ale też z noszonych urządzeń mierzących sen, aktywność i inne pasywne sygnały - i generuje zwięzłą narrację w języku naturalnym. Brzmi to mniej więcej tak: 'Dwa nocne spadki cukru w ostatnim tygodniu zakłóciły sen. Pacjent miał trudności z utrzymaniem aktywności fizycznej, a godziny posiłków były nieregularne'. W drugim etapie model przewiduje wynik w skali PHQ-4, opierając się wyłącznie na tym opisie - nie na surowych liczbach.
Kluczowa jest metoda uczenia. TimeSRL nie dostał ani jednej ręcznie napisanej przykładowej narracji. Zamiast tego, za pomocą algorytmu GRPO, model generuje kilka wersji streszczenia i prognozy dla tego samego pacjenta. Każda wersja dostaje nagrodę opartą wyłącznie na tym, jak blisko prawdziwego wyniku PHQ-4 trafiła. System sam odkrywa, które wzorce - na przykład kombinacja nocnych hipoglikemii i skróconego snu - mają znaczenie predykcyjne dla nastroju.
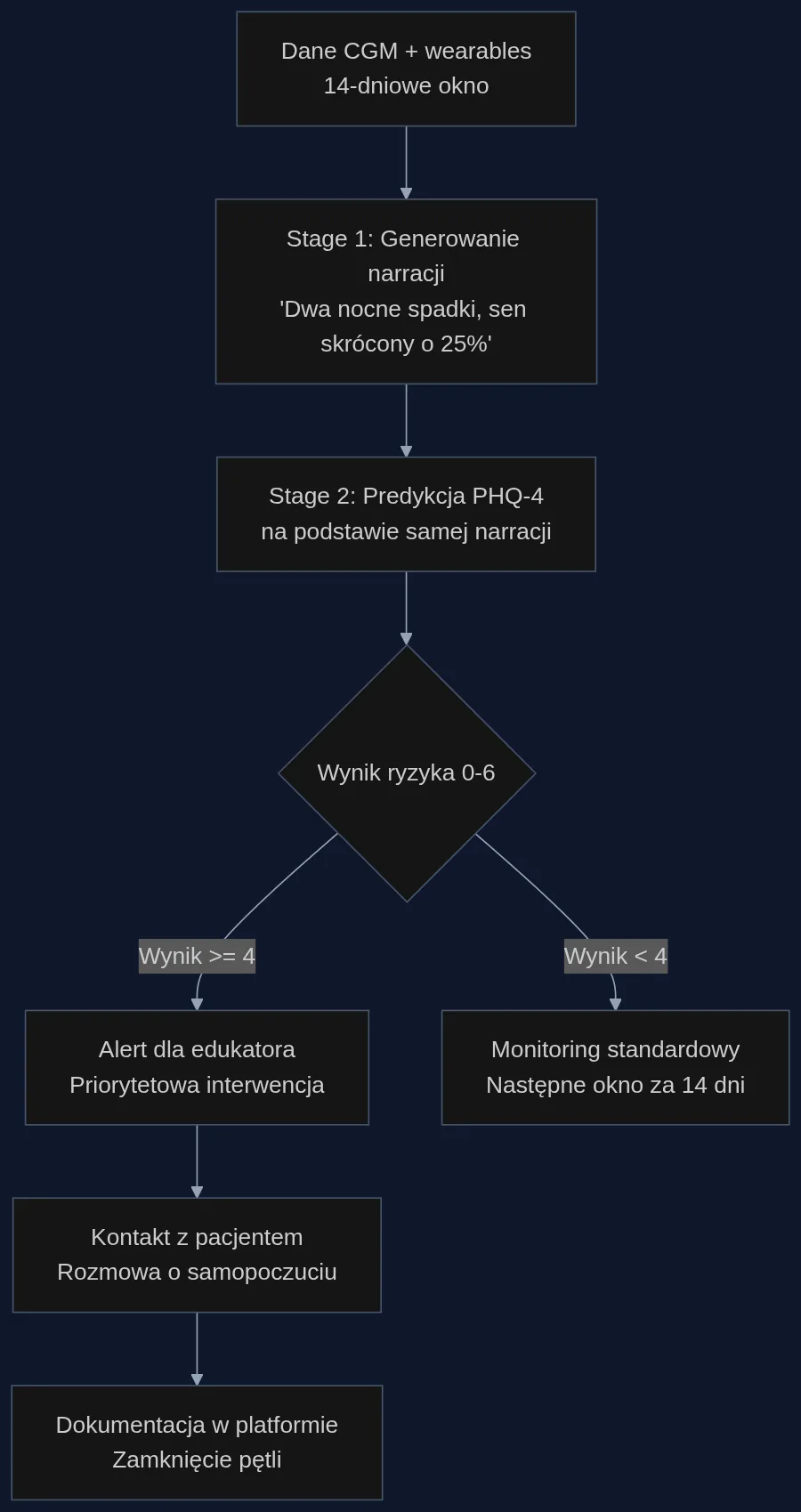
Scenariusz: platforma zdalnego monitorowania pacjentów z cukrzycą
Wyobraźmy sobie platformę telemedyczną obsługującą 5000 pacjentów z cukrzycą typu 1. Każdy pacjent używa sensora CGM (różnych producentów - Dexcom, Abbott, Medtronic) oraz opcjonalnie smartwatcha. Obecnie zespół diabetologów i edukatorów przegląda alerty generowane przez system - hipoglikemie, hiperglikemie, braki danych. Przy 5000 pacjentów to około 300 alertów dziennie. Zespół cierpi na alarm fatigue, a subtelne sygnały wypalenia giną w szumie.
Z TimeSRL platforma raz na dwa tygodnie generuje dla każdego pacjenta krótki akapit narracji behawioralnej oraz wskaźnik ryzyka obniżenia nastroju (skala 0-6). Edukator diabetologiczny widzi na dashboardzie nie listę alertów, ale posortowaną listę pacjentów z najwyższym ryzykiem. Klikając w konkretny przypadek, czyta: 'Pacjentka doświadczyła trzech epizodów nocnej hipoglikemii w ciągu ostatnich 10 dni. Dane z akcelerometru pokazują 40-procentowy spadek dziennej liczby kroków. Jakość snu obniżyła się o 25%'. Na tej podstawie edukator może zainicjować kontakt - nie z pytaniem o cukier, ale o samopoczucie i motywację.
Dlaczego to działa przy różnych sensorach
Jednym z największych kosztów wdrożeń AI w diabetologii jest konieczność ponownego trenowania modeli dla każdego nowego typu sensora lub wersji oprogramowania. TimeSRL omija ten problem dzięki semantycznemu wąskiemu gardłu. Model nie operuje na mikrowoltach sygnału z elektrody - operuje na pojęciach takich jak 'nocny spadek', 'posiłkowy wzrost' czy 'przerwa w monitorowaniu'. Te pojęcia są wspólne dla wszystkich systemów CGM. Badania na zbiorach GLOBEM i College Experience pokazały, że nauczone abstrakcje przenoszą się między różnymi pipeline'ami sensorycznymi bez dodatkowego dostrajania, często dorównując wynikom modeli trenowanych od zera na docelowej domenie.
Dla operatora platformy oznacza to jedno: nowy pacjent z nowym typem sensora wchodzi do systemu, a model działa od pierwszego dnia.
Konkretne liczby: od badań do ROI
W badaniach TimeSRL zredukował średni absolutny błąd (MAE) w przewidywaniu depresji o 3,2 do 9,6% w porównaniu z najlepszymi modelami nie-LLM i o 27 do 58% w porównaniu z bezpośrednim użyciem LLM. Co to oznacza w praktyce? Przyjmując konserwatywnie, że w populacji 5000 pacjentów z cukrzycą około 1500 ma podwyższone ryzyko depresji, poprawa dokładności o 5 punktów procentowych oznacza wychwycenie dodatkowych 75 osób, które standardowe metody by przeoczyły.
Koszt jednej hospitalizacji z powodu kwasicy ketonowej u pacjenta z nierozpoznaną depresją to w Polsce około 8000-12000 zł. Zapobiegnięcie nawet 10 takim hospitalizacjom rocznie zwraca koszt wdrożenia systemu. Do tego dochodzi redukcja czasu pracy edukatorów - zamiast przeglądać 300 alertów dziennie, analizują 20-30 priorytetowych przypadków wytypowanych przez model.
Od alertu do rozmowy
Największą wartością TimeSRL w diabetologii nie jest sama predykcja - to zmiana jakości kontaktu z pacjentem. System nie mówi: 'Pacjent XYZ ma 78% ryzyka depresji'. Daje narzędzie do rozmowy: 'Zauważyliśmy, że w ostatnich dwóch tygodniach noce były trudne - cukier spadał, sen był przerywany. Jak się Pani z tym czuje?'. To język, który buduje zaufanie, a nie tylko klasyfikuje ryzyko. Dla pacjenta zmęczonego ciągłymi alertami o wysokim cukrze, komunikat łączący dane metaboliczne z troską o samopoczucie może być pierwszym sygnałem, że ktoś widzi w nim człowieka, nie tylko wykres.
- Redukcja MAE predykcji depresji o 3-10% vs. tradycyjne modele ML
- Transferowalność między sensorami CGM różnych producentów bez dostrajania
- Zastąpienie setek alertów dziennie listą 20-30 priorytetowych przypadków
- Wczesne wykrycie wypalenia cukrzycowego przed eskalacją do hospitalizacji
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: TimeSRL: Generalizable Time-Series Behavioral Modeling via Semantic RL-Tuned LLMs -- A Case Study in Mental Health
Autorzy: Yuang Fan, Lilin Xu, Millie Wu, Jingping Nie, Qingyu Chen i in.
Longitudinal passive sensing enables continuous health prediction, yet models often fail under cross-dataset distribution shifts. Traditional ML overfits cohort-specific artifacts, while Large Language Models (LLMs) struggle to reason reliably over long, heterogeneous time-series. We introduce Ti...
arXiv: arxiv.org/abs/2605.21295
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}