
Wyobraź sobie, że twój telefon przez dwa tygodnie zbiera informacje o twoim śnie, krokach i lokalizacji, a potem - bez żadnych dodatkowych pytań - potrafi ocenić, czy czujesz się przygnębiony. Brzmi jak scenariusz z filmu science fiction? Naukowcy właśnie pokazali, że jest to możliwe, i to z zaskakującą dokładnością, pod warunkiem że model AI najpierw opowie historię twojego tygodnia, zanim postawi diagnozę.
Dlaczego dane sensoryczne to za mało
Modele uczenia maszynowego od lat próbują przewidywać stany emocjonalne na podstawie pasywnie zbieranych danych - liczby kroków, czasu ekranu, rytmu snu. Problem w tym, że gdy taki model, wytrenowany na jednej grupie użytkowników z konkretnymi telefonami, trafia na inną populację lub inne sensory, jego dokładność gwałtownie spada. Dane z akcelerometru w smartfonie Xiaomi różnią się od tych z iPhone'a, a studenci z Kalifornii zachowują się inaczej niż pacjenci kliniki w Teksasie. To sprawia, że wdrożenie uniwersalnego systemu monitorowania zdrowia psychicznego jest bardzo trudne.
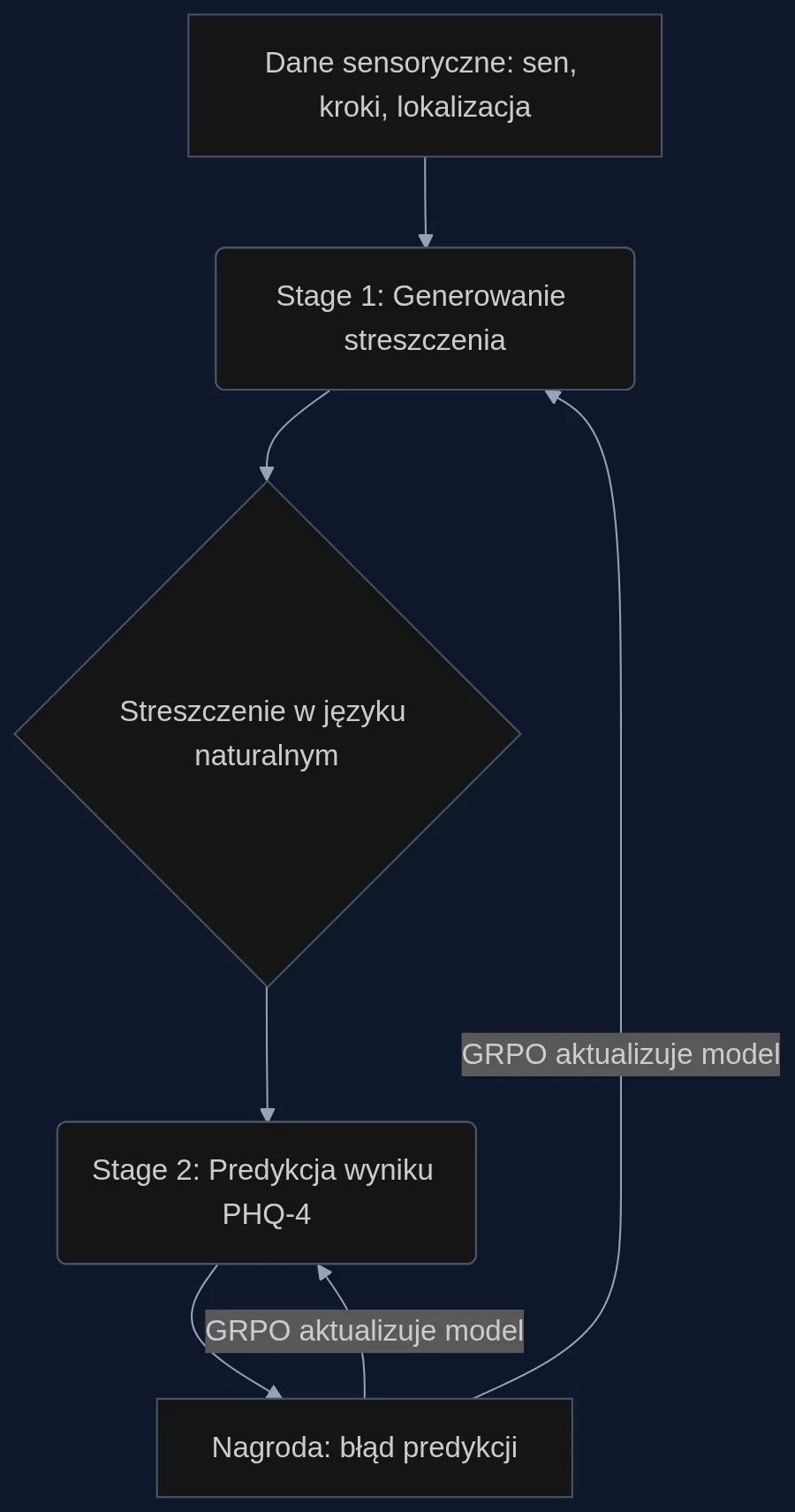
Zespół badaczy z kilku uniwersytetów (m.in. MIT, Dartmouth, University of Washington) zaproponował nowe podejście: zamiast uczyć model bezpośrednio na surowych liczbach, każą mu najpierw opisać zachowanie człowieka w naturalnym języku. Taki opis, nazwany wąskim gardłem semantycznym, staje się jedynym źródłem informacji do dalszej analizy. Dzięki temu model uczy się wyciągać ogólne wzorce, a nie zapamiętywać szczegóły konkretnego czujnika.
Wąskie gardło semantyczne: z danych w opowieść
Architektura TimeSRL składa się z dwóch etapów, które wykonuje ten sam model językowy (LLM). W pierwszym etapie otrzymuje on 14-dniowe okno danych behawioralnych - na przykład: średni czas snu 6,2 godziny, 3400 kroków dziennie, czas spędzony w domu 80%, 2,5 godziny ekranu wieczorem. Na tej podstawie model generuje swobodny opis w kilku zdaniach, coś w stylu: 'Użytkownik miał stabilny rytm snu, ale w weekendy aktywność fizyczna spadała. Większość czasu spędzał w domu, a wieczorami długo korzystał z telefonu.'
Drugi etap to już tylko ten tekst. Model nie widzi żadnych surowych liczb - ma wyłącznie streszczenie i na jego podstawie przewiduje wynik w skali PHQ-4 (od 0 do 6 punktów), który mierzy nasilenie lęku i depresji. To wymuszenie operowania na pojęciach wysokiego poziomu - zamiast na wartościach liczbowych - jest istotne dla uogólniania.
'Uważamy, że solidne wnioskowanie powinno przechodzić przez jawne wąskie gardło semantyczne. Zamiast przewidywać bezpośrednio z surowych danych behawioralnych, model powinien najpierw wydobyć semantyczne spostrzeżenia, przekształcając trajektorię w zwięzłą abstrakcję w języku naturalnym, która uchwyci rozciągnięte w czasie i zależne od kontekstu wzorce istotne dla dalszego wnioskowania.' - Fan et al., TimeSRL paper, Introduction
Można to porównać do pracy lekarza: zanim postawi diagnozę, zbiera wywiad, a potem formułuje w głowie podsumowanie objawów. To podsumowanie jest bardziej uniwersalne niż surowe wyniki badań - dwóch lekarzy z różnych szpitali, posługując się podobnym opisem, dojdzie do podobnych wniosków, nawet jeśli używali innych aparatów do pomiaru ciśnienia.
Uważamy, że solidne wnioskowanie powinno przechodzić przez jawne wąskie gardło semantyczne. Zamiast przewidywać bezpośrednio z surowych danych behawioralnych, model powinien najpierw wydobyć semantyczne spostrzeżenia, przekształcając trajektorię w zwięzłą abstrakcję w języku naturalnym, która uchwyci rozciągnięte w czasie i zależne od kontekstu wzorce istotne dla dalszego wnioskowania.
Fan et al.
TimeSRL paper, Introduction
Uczenie przez nagrodę: GRPO zamiast ręcznych opisów
Największym wyzwaniem w takim podejściu jest brak gotowych streszczeń - nikt nie opisał słowami tygodniowego zachowania tysięcy uczestników badań. TimeSRL rozwiązuje to za pomocą uczenia ze wzmocnieniem, konkretnie algorytmu GRPO (Group Relative Policy Optimization). Model podczas treningu dla każdego okna danych generuje kilka (K=8) kandydatów - kompletnych trajektorii zawierających streszczenie i predykcję. Każda taka trajektoria dostaje nagrodę, która jest tym wyższa, im bliższa prawdziwemu wynikowi PHQ-4 była predykcja. Używana jest gaussowska funkcja nagrody, która daje płynny sygnał nawet przy dużych błędach.
Następnie GRPO porównuje nagrody w obrębie grupy i aktualizuje parametry modelu, faworyzując te trajektorie, które wypadły lepiej niż średnia. Jednocześnie mechanizm regularyzacji pilnuje, by model nie odbiegł zbyt daleko od swojego pierwotnego, płynnego języka - inaczej zacząłby produkować bełkot. Nie ma tu ręcznie tworzonych wzorcowych streszczeń. Sygnał uczenia pochodzi wyłącznie z tego, czy końcowa predykcja była trafna.
'Wąskie gardło semantyczne można postrzegać jako formę samonadzorowanego uczenia reprezentacji, które operuje w języku naturalnym, a nie w wyuczonej przestrzeni wektorowej. Cel RL działa jako sygnał kształtujący zgodny z zadaniem: nie wymaga od praktyka określania, co streszczenie powinno zawierać, ale pozwala optymalizacji odkryć, które właściwości semantyczne są użyteczne decyzyjnie dla docelowego zadania.' - Fan et al., TimeSRL paper, Discussion
Wyniki: mniejszy błąd i lepsza przenośność
Testy przeprowadzono na dwóch dużych zbiorach danych: GLOBEM (zebrany podczas pandemii COVID-19) oraz College Experience (dane studentów). W obu przypadkach TimeSRL osiągnął najniższy średni błąd bezwzględny (MAE) w przewidywaniu zarówno lęku, jak i depresji. W porównaniu z najlepszymi modelami nie korzystającymi z LLM redukcja MAE wyniosła od 3,1% do 10,1% dla lęku i od 3,2% do 9,6% dla depresji. W zestawieniu z bezpośrednim użyciem modeli GPT-5.0 czy Qwen3-4B (gdzie LLM widzi surowe dane i od razu przewiduje wynik) poprawa sięgała nawet 44,1% dla lęku i 57,6% dla depresji.
Streszczenia wygenerowane przez TimeSRL okazały się przenośne między zestawami danych. Model wytrenowany na GLOBEM i testowany na College Experience (bez żadnego dostrajania) często dorównywał wynikom uzyskanym wewnątrz tej samej domeny. To sugeruje, że abstrakcje semantyczne są uniwersalne - opis 'nieregularny sen i mało aktywności' znaczy to samo niezależnie od tego, czy dane pochodzą z iPhone'a czy z Android Wear.
'Te wyniki pokazują, że abstrakcje semantyczne są wielokrotnego użytku i wskazują nowy kierunek dla uogólnialnego modelowania zachowań za pomocą LLM dostrajanych przez RL.' - Fan et al., TimeSRL paper, Abstract
Jakościowa analiza streszczeń ujawniła jeszcze jedną zaletę: modele bez strojenia (np. GPT-5.0) miały tendencję do wyolbrzymiania negatywnych aspektów - jeśli w ciągu dwóch tygodni zdarzył się jeden dzień z bardzo krótkim snem, streszczenie koncentrowało się na nim, przewidując wysoki poziom lęku. TimeSRL natomiast tworzył zrównoważone opisy, umieszczając pojedyncze incydenty na tle ogólnej stabilności. Dzięki temu predykcje były bliższe rzeczywistości.
- TimeSRL redukuje błąd predykcji lęku o 3-10% w porównaniu do najlepszych modeli nie-LLM i o 9-44% w porównaniu do bezpośredniego użycia LLM.
- Model uczy się generować streszczenia bez ręcznych adnotacji - sygnałem jest tylko dokładność końcowej predykcji.
- Streszczenia semantyczne są przenośne między różnymi zestawami danych i sensorami, co otwiera drogę do uniwersalnych modeli behawioralnych.
- Technika działa z wieloma LLM (Qwen, Llama, GPT-oss, Nemotron), redukując błąd od 38% do 62%.
Praktyczne zastosowania
Aby lepiej zrozumieć opisywaną innowację, przygotowaliśmy cztery przykłady praktycznego zastosowania tej technologii w różnych branżach:




Podsumowanie
Podsumowując, TimeSRL pokazuje, że wymuszenie na modelu operowania na abstrakcjach językowych może radykalnie poprawić jego zdolność do uogólniania na nowe populacje i urządzenia. W praktyce takie podejście może znaleźć zastosowanie w systemach monitorowania zdrowia psychicznego, gdzie dane pochodzą z różnych smartfonów i sensorów, a także w innych dziedzinach, gdzie dane czasowe mają złożoną strukturę - na przykład w diagnostyce medycznej opartej na wearables czy predykcji awarii maszyn z danych IoT. Wspólny mianownik to sytuacje, w których taniej i bezpieczniej jest nauczyć model rozumieć zachowanie w kategoriach semantycznych niż dopasowywać go do każdego nowego źródła danych.
Metryka artykułu źródłowego
Tytuł oryginalny: TimeSRL: Generalizable Time-Series Behavioral Modeling via Semantic RL-Tuned LLMs -- A Case Study in Mental Health
Autorzy: Yuang Fan, Lilin Xu, Millie Wu, Jingping Nie, Qingyu Chen, Yuzhe Yang, Zhuo Zhang, Xin Liu, Subigya Nepal, Xiaofan Jiang, Xuhai "Orson" Xu
Data publikacji: 21 maja 2026
arXiv: arxiv.org/abs/2605.21295
Napisanie tego artykułu zostało wspomagane przez sztuczną inteligencję. Treść opiera się na oryginalnym artykule naukowym, a jej dokładność została zweryfikowana automatycznie.