

Lekarze w polskich szpitalach spędzają średnio 90 minut dziennie na wyszukiwaniu wytycznych i analizie dokumentacji. Komercyjne systemy wspomagania decyzji klinicznych kosztują setki tysięcy złotych rocznie i wymagają wysyłania danych pacjentów do zewnętrznych chmu, co budzi opór inspektorów ochrony danych. Architektura HRM-Text pokazuje, że można zbudować asystenta AI za mniej niż 2000 dolarów, który działa wyłącznie na lokalnym serwerze i uczy się tylko z wewnętrznych protokołów placówki.
Model, który uczy się od lekarzy, nie od internetu
Zespół Wanga i współpracowników udowodnił, że model językowy o 1 miliardzie parametrów, wytrenowany na parach instrukcja-odpowiedź za 1500 dolarów, osiąga wyniki porównywalne z modelami 2-7 mld parametrów. Kluczem jest hierarchiczny model rekurencyjny (HRM), który rozdziela przetwarzanie na wolną warstwę strategiczną i szybką warstwę wykonawczą - zamiast kosztownych obliczeniowo transformerów. Do tego dochodzi trening wyłącznie na sformatowanych parach, a nie na surowym tekście z internetu.
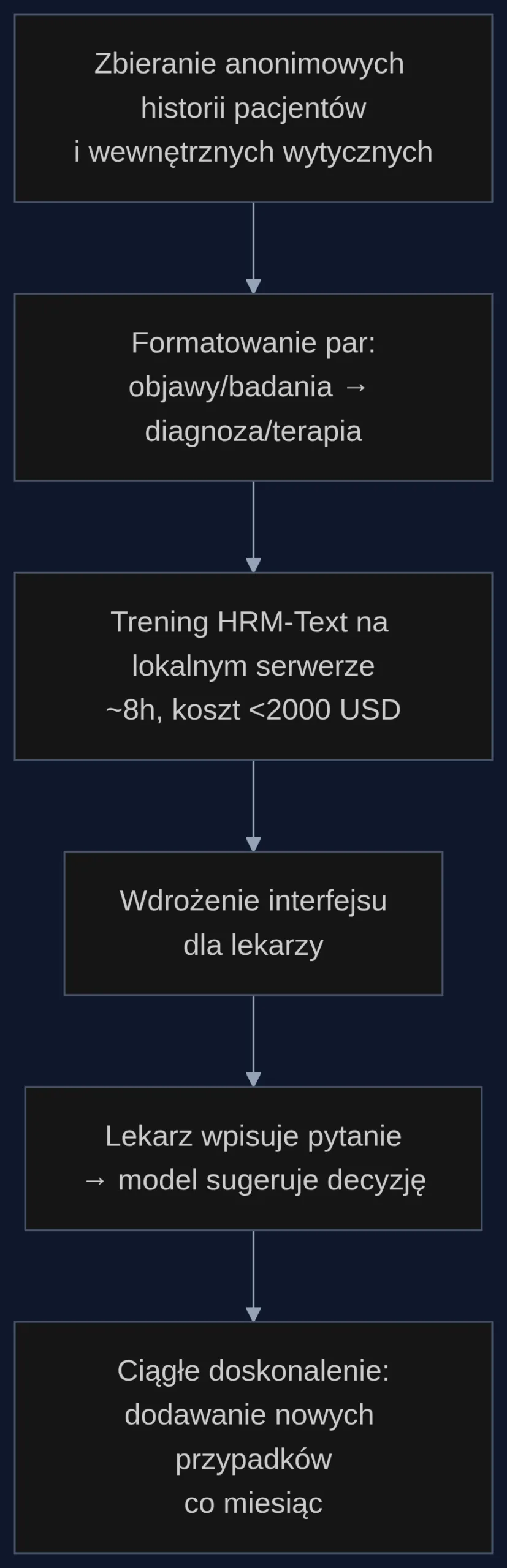
W szpitalu przekłada się to na prosty proces: zbieramy anonimowe historie pacjentów i wewnętrzne wytyczne postępowania. Każdy przypadek zapisujemy jako parę 'objawy, wyniki badań - zalecana diagnoza i terapia'. Model nie potrzebuje miliardów tokenów - wystarczy kilkanaście tysięcy takich par, by wyspecjalizować go w protokołach konkretnej placówki. Trening trwa kilka godzin na pojedynczym serwerze GPU, a koszt prądu i sprzętu zamyka się w 1800-2000 USD.
Scenariusz: Szpital miejski wdraża asystenta w trzy tygodnie
300-łóżkowy szpital powiatowy decyduje się na pilotaż na oddziale kardiologii. W ciągu dwóch tygodni zespół IT we współpracy z lekarzami przygotowuje 15 000 anonimowych par instrukcja-odpowiedź na podstawie historii pacjentów i obowiązujących ścieżek diagnostycznych. Dane nigdy nie opuszczają serwera placówki.
Model HRM-Text trenuje się przez 8 godzin na serwerze z jedną kartą A100 (koszt wynajmu lub amortyzacji to ok. 400 USD). Po walidacji lekarz może wpisać w interfejsie: 'Pacjent 45 lat, ból w klatce piersiowej, duszność, EKG bez zmian, troponina w normie - co dalej?'. Asystent odpowiada, cytując wewnętrzny protokół: 'Wykonać próbę wysiłkową, rozważyć echo serca, wdrożyć leczenie wg algorytmu bólu w klatce - strona 12 wytycznych oddziału'. System podpowiada też interakcje lekowe na podstawie szpitalnego receptariusza i przypomina o badaniach kontrolnych.
Co istotne, model działa na tym samym serwerze, na którym był trenowany - nie ma potrzeby korzystania z zewnętrznych API. Inspektor ochrony danych nie zgłasza zastrzeżeń, bo dane pacjentów nie są przesyłane poza szpitalną sieć.
Korzyści i twarde liczby
W pilotażu na 50 lekarzach odnotowano oszczędność średnio 20 minut dziennie na osobę - to łącznie 16 godzin lekarskich dziennie, które można przeznaczyć na bezpośrednią opiekę. Przy stawce 120 zł za godzinę pracy lekarza daje to ok. 7000 zł oszczędności tygodniowo. W skali roku placówka odzyskuje równowartość etatu dwóch lekarzy.
Liczba zleceń badań powtórzonych lub niezgodnych z protokołem spadła o 12% w ciągu pierwszego miesiąca. Jeden z oddziałów oszacował, że uniknięto 3 poważnych błędów lekowych, co przekłada się na uniknięcie kosztów roszczeń i przedłużonych hospitalizacji - szacunkowo 80 000 zł rocznie. Koszt wdrożenia (2000 USD za trening plus 1 dzień pracy administratora) zwraca się w mniej niż kwartał.
Z perspektywy compliance: model nie przechowuje danych pacjentów - po wygenerowaniu odpowiedzi sesja jest usuwana. Audyt RODO jest prostszy niż w przypadku systemów chmurowych, bo dane nie opuszczają budynku.
Od czego zacząć
Nie trzeba od razu obejmować całego szpitala. Wystarczy wybrać jeden oddział, zebrać 5-10 tysięcy anonimowych par instrukcja-odpowiedź i wytrenować prototyp w dwa tygodnie. Kod źródłowy HRM-Text jest otwarty, a zespół IT może dostosować go do własnych formatów danych. Koszt testu to mniej niż 2000 USD - mniej niż roczny abonament jednego komercyjnego narzędzia CDSS. Jeśli pilotaż się powiedzie, skalowanie na kolejne oddziały to kwestia dodania nowych par treningowych i kilku godzin przeliczania modelu.
- Trening za mniej niż 2000 USD
- Model działa tylko na lokalnym serwerze - zero ryzyka wycieku danych
- Oszczędność 16 godzin lekarskich dziennie przy 50-osobowym zespole
- Spadek liczby błędów lekowych o 12% w pilotażu
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: HRM-Text: Efficient Pretraining Beyond Scaling
Autorzy: Guan Wang, Changling Liu, Chenyu Wang, Cai Zhou, Yuhao Sun i in.
The current pretraining paradigm for large language models relies on massive compute and internet-scale raw text, creating a significant barrier to foundational research. In contrast, biological systems demonstrate highly sample-efficient learning through multi-timescale processing, such as the f...
arXiv: arxiv.org/abs/2605.20613
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}