
Systemy RAG (Retrieval-Augmented Generation) miały pomóc modelom językowym w dostępie do faktów, ale często komplikują infrastrukturę i nie eliminują halucynacji. Nowa praca proponuje odwrót od wektorowych baz danych na rzecz prostoty - to LLM sam konstruuje precyzyjne zapytania logiczne, a wyszukiwarka oparta na starym dobrym indeksie odwróconym je realizuje. Efekt: niższe koszty i odpowiedzi bardziej osadzone w rzeczywistości.
Problem z dzisiejszymi RAG: za dużo warstw, za mało kontroli
Kiedy Retrieval-Augmented Generation weszło do mainstreamu, obiecywało uziemić modele w faktach. W praktyce wiele wdrożeń przypomina wielopiętrowy tort: embeddingi, przeszukiwanie hybrydowe, reranking, a na koniec i tak LLM potrafi wymyślić nieistniejący artykuł. Agentowe RAG, gdzie model wielokrotnie dopytuje system, dodaje tylko kolejną warstwę, ale jądro problemu zostaje: wyszukiwanie opiera się na podobieństwie wektorowym, które jest ślepe na precyzyjne kryteria.
Wyobraź sobie bibliotekarza, który na pytanie o książkę o historii Gdańska po 1945 roku podaje wszystko, co zawiera słowa 'Gdańsk' i 'historia', nie rozróżniając epok. Cosinus między wektorami jest wysoki, ale odpowiedź nietrafiona. Autorzy pracy zauważają, że dawanie modelowi większej kontroli nad tym, czego dokładnie szuka, może być skuteczniejsze niż budowanie coraz bardziej złożonych pipeline'ów.
Rozwiązanie: logiczny interfejs do wyszukiwania
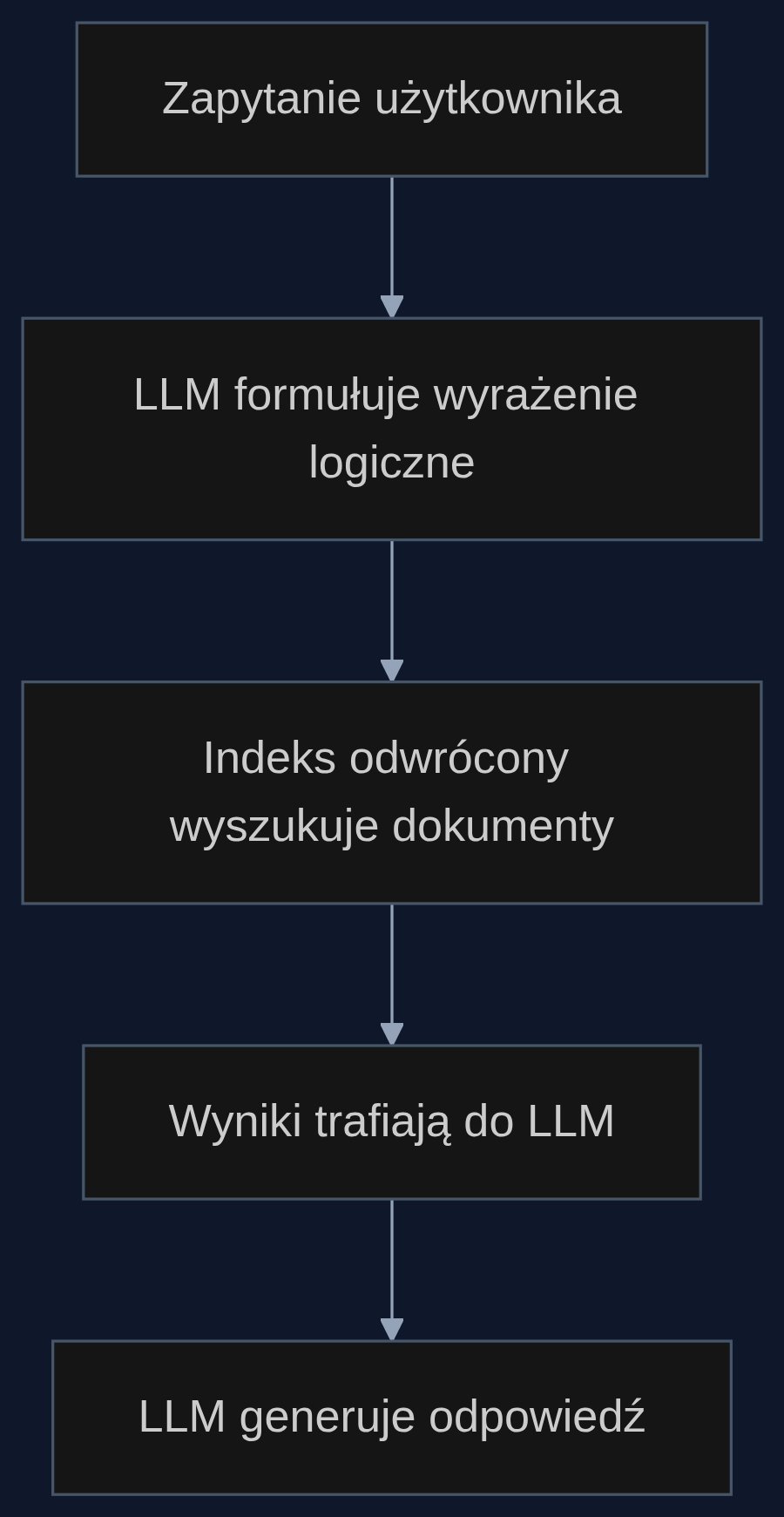
Zamiast przekształcać zapytanie w wektor i liczyć podobieństwa, autorzy proponują, by LLM sam generował wyrażenia logiczne, na przykład dokumenty zawierające frazę 'emisja CO2' ORAZ '2024' ALE NIE 'prognoza'. Te zapytania trafiają do prostego systemu opartego na indeksie odwróconym, technologii sprzed dekad, która błyskawicznie znajduje dokumenty spełniające warunki.
'Powinniśmy przekazać większą kontrolę modelowi LLM, aby kierował procesem wyszukiwania, opierając się na lekkim interfejsie, który zapewnia precyzyjną kontrolę i wiernie wykonuje ustrukturyzowane intencje LLM', piszą Yuqi Zeng i współautorzy. Indeks odwrócony to nic innego jak spis słów z listą miejsc, gdzie występują; działa szybko, nie wymaga GPU i jest tani w utrzymaniu.
Ramka jest agentowa, bo LLM może iteracyjnie poprawiać zapytanie, widząc wyniki. Ale zamiast grzebania w wektorowej czarnej skrzynce, dostaje przejrzysty interfejs. To trochę jak różnica między zamawianiem jedzenia przez aplikację, która sama dobiera restauracje podobne do tych, które lubisz, a samodzielnym filtrowaniem po kuchni, cenie i ocenie.
Powinniśmy przekazać większą kontrolę modelowi LLM, aby kierował procesem wyszukiwania, opierając się na lekkim interfejsie, który zapewnia precyzyjną kontrolę i wiernie wykonuje ustrukturyzowane intencje LLM.
Yuqi Zeng et al.
Abstrakt
Wyniki: tanio, skutecznie i bez zmyślania
Testy wypadły obiecująco. System z logicznym sterowaniem dorównał wydajnością mocnej hybrydowej bazie (agentowej, z embeddingami i rerankerem), ale koszty budowy i działania były znacznie niższe. Co ważniejsze, odpowiedzi rzadziej zawierały halucynacje, bo każde twierdzenie dało się prześledzić do konkretnego dokumentu, który spełnił wyrażenie logiczne.
'Zakotwiczenie wyszukiwania w zapytaniach logicznych znacząco redukuje halucynacje', podkreślają autorzy. To ma sens: jeśli model wie, że pytanie dotyczy dokumentów z frazą 'umowa najmu' I 'wypowiedzenie' z ostatnich 2 lat, nie będzie przypadkiem cytował regulaminu sprzed dekady tylko dlatego, że cosinusy były podobne.
Zespół nie twierdzi, że embeddingi są złe. Raczej, że w wielu zastosowaniach biznesowych, gdzie mamy do czynienia z ustrukturyzowanymi dokumentami i konkretnymi pytaniami, prostsze narzędzie może dać lepsze efekty. I to bez armii inżynierów do strojenia pipeline'ów.
- Modele LLM potrafią skutecznie formułować intencje wyszukiwawcze w formie wyrażeń logicznych.
- Prosty system oparty na indeksie odwróconym dorównuje wydajnością złożonym hybrydowym wyszukiwarkom, gdy steruje nim LLM.
- Koszty wdrożenia i utrzymania są znacząco niższe niż w architekturach dense/hybrid.
- Precyzyjne zapytania logiczne ograniczają halucynacje w generowanych odpowiedziach.
Praktyczne zastosowania
Aby lepiej zrozumieć opisywaną innowację, przygotowaliśmy cztery przykłady praktycznego zastosowania tej technologii w różnych branżach:



Podsumowanie
Technologia może sprawdzić się w firmowych bazach wiedzy, gdzie pytania dotyczą konkretnych regulaminów, umów czy procedur - wystarczy, że LLM zapyta o dokumenty z klauzulą 'siła wyższa' i datą po 2023 roku. Podobnie w wyszukiwarkach prawniczych lub medycznych, gdzie precyzja przesądza o bezpieczeństwie decyzji.
Metryka artykułu źródłowego
Tytuł oryginalny: Rethinking Agentic RAG: Toward LLM-Driven Logical Retrieval Beyond Embeddings
Autorzy: Yuqi Zeng, Qixiang Deng, Yulei Wan, Ruiquan Jiang, Xiaoqing Zheng, Xuanjing Huang
Data publikacji: 27 maja 2026
arXiv: arxiv.org/abs/2605.27123
Napisanie tego artykułu zostało wspomagane przez sztuczną inteligencję. Treść opiera się na oryginalnym artykule naukowym, a jej dokładność została zweryfikowana automatycznie.