
Dynamiczny trening rzadki (DST) od dawna obiecywał szybsze uczenie sieci neuronowych przy mniejszym zużyciu zasobów. W praktyce jednak rzadkie sieci uczyły się zauważalnie wolniej niż ich gęste odpowiedniki. Zespół badaczy z Uniwersytetu Calgary i University of Cambridge znalazł winowajcę: normalizację wsadową, która zniekształca gradienty w rzadkich warstwach i spowalnia cały proces uczenia.
Rzadkie sieci i problem, którego nikt wcześniej nie rozpracował
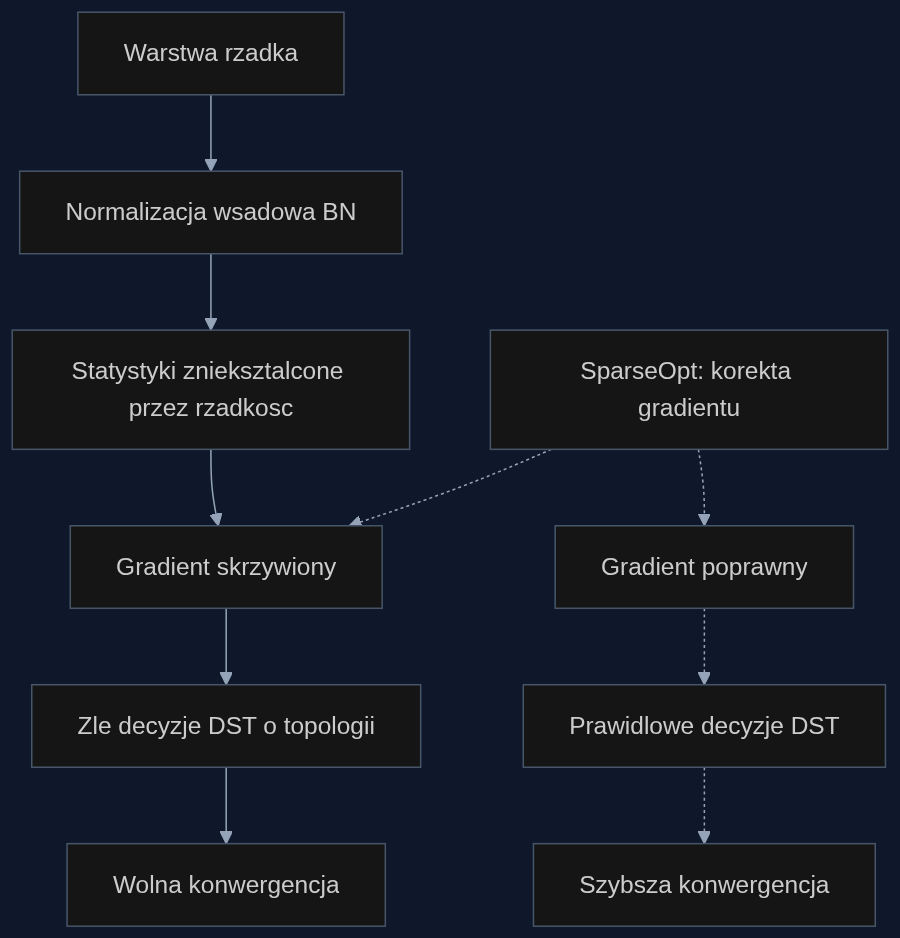
Dynamiczny trening rzadki polega na tym, że sieć neuronowa w trakcie uczenia celowo wyłącza dużą część swoich połączeń, żeby oszczędzać pamięć i moc obliczeniową. Topologia nie jest ustalona raz na zawsze, sieć może przywracać połączenia i wyłączać inne w kolejnych iteracjach. Brzmi to sensownie: po co liczyć wszystko, skoro duża część wag i tak ma wartości bliskie zeru?
Tyle że wyniki nigdy nie dogoniły obietnic. Owszem, zużycie pamięci spadało, ale czas treningu i końcowa dokładność modelu wypadały słabiej niż przy standardowym, gęstym treningu. Przez lata nikt nie potrafił przekonująco wyjaśnić, dlaczego.
Autorzy SparseOpt podeszli do sprawy analitycznie. Wyprowadzili, jak dokładnie normalizacja wsadowa (BN) wpływa na obliczanie gradientów w warstwach rzadkich. Okazało się, że BN, która jest wszędzie, wprowadza systematyczne przekłamanie. Gradienty przestają odzwierciedlać rzeczywisty kierunek optymalizacji i zamiast tego są 'przechylone' w stronę pewnych wzorców, co dezorientuje mechanizm dynamicznej zmiany topologii.
Normalizacja, która niechcący szkodzi
Batch Normalization to technika, która normalizuje dane wejściowe warstwy w obrębie miniserii. Dzięki temu trening głębokich sieci jest stabilniejszy i szybszy. BN stała się standardowym elementem architektur takich jak ResNet i od lat nikt nie kwestionował jej obecności.
Problem pojawia się, gdy warstwa jest rzadka. Normalizacja zakłada, że statystyki liczone są na pełnym zestawie aktywacji neurony. Jeśli duża część neuronów jest wyłączona, statystyki przestają być reprezentatywne. Gradient, który wędruje wstecz przez taką warstwę, zostaje 'skrzywiony' i nie wskazuje już właściwego kierunku poprawy wag. Efekt? Algorytm DST podejmuje złe decyzje o tym, które połączenia przywrócić, a które wyłączyć. Iteracja za iteracją, błędy się kumulują i konwergencja zwalnia.
Co ciekawe, to pierwsza praca, która systematycznie przebadała tę interakcję. Wcześniej zakładano, że rzadkość sama w sobie jest winna spowolnieniu. Tymczasem źródłem jest właśnie normalizacja.
Normalizacja wsadowa, która w gęstych sieciach jest dobrodziejstwem, w warstwach rzadkich systematycznie zniekształca gradienty. Nasza korekta przywraca im właściwy kierunek i pozwala rzadkim sieciom uczyć się tak efektywnie, jak zawsze obiecywano.
Mohammed Adnan
University of Calgary, główny autor badania SparseOpt
SparseOpt: poprawka, a nie rewolucja
Zamiast wymyślać cały optymalizator od nowa, autorzy zaproponowali korektę. SparseOpt to optymalizator uwzględniający rzadkość sieci, który dodaje współczynnik korekcyjny do obliczania gradientów w warstwach z BN. Ten współczynnik kompensuje przekłamanie wprowadzane przez normalizację i przywraca gradientom właściwy kierunek.
Implementacja nie jest skomplikowana. Nie wymaga zmiany architektury sieci ani rezygnacji z BN, która w wielu przypadkach jest niezbędna do stabilnego treningu. Wystarczy podmienić optymalizator na wersję świadomą rzadkości.
Eksperymenty przeprowadzono na ResNetach uczonych na CIFAR-100 i ImageNet. W obu przypadkach SparseOpt osiągał szybszą konwergencję niż standardowe metody DST i lepszą generalizację. Modele trenowane z SparseOpt szybciej dochodziły do wysokiej dokładności i kończyły trening z lepszym wynikiem na zbiorze testowym.
Co to zmienia w praktyce
Znaczenie tego odkrycia wykracza poza akademicką ciekawość. Trening rzadki od lat był postrzegany jako technika 'na wyrost', ciekawa teoretycznie, ale niepraktyczna w realnych zastosowaniach. SparseOpt pokazuje, że problem nie leżał w samej idei rzadkości, tylko w interakcji z powszechną normalizacją.
Jeśli rzadkie sieci zaczną się uczyć tak szybko jak gęste, bilans kosztów i korzyści przestaje być jednostronny. Firmy, które chcą trenować modele na własnym sprzęcie, zamiast wynajmować klastry GPU, dostają realną alternatywę. Mniejsza liczba aktywnych połączeń to mniej obliczeń, mniej transferów pamięci i niższy rachunek za prąd. Różnica robi się szczególnie istotna przy trenowaniu wielu wariantów modelu w krótkim czasie, na przykład przy strojeniu hiperparametrów.
Zespół badawczy udostępnił kod SparseOpt na zasadach open source, więc każdy może przetestować go na własnych architekturach. Nie zdziwię się, jeśli w ciągu roku pojawią się implementacje w popularnych frameworkach.
- Normalizacja wsadowa (BN) wprowadza przekłamanie gradientów w rzadkich warstwach sieci neuronowych, spowalniając konwergencję dynamicznego treningu rzadkiego (DST)
- SparseOpt to optymalizator z współczynnikiem korekcyjnym, który kompensuje to przekłamanie bez zmiany architektury sieci
- Eksperymenty na ResNetach z CIFAR-100 i ImageNet potwierdzają szybszą konwergencję i lepszą generalizację w porównaniu do standardowych metod DST
- To pierwsze systematyczne badanie interakcji między normalizacją wsadową a dynamicznym treningiem rzadkim
Praktyczne zastosowania
Aby lepiej zrozumieć opisywaną innowację, przygotowaliśmy cztery przykłady praktycznego zastosowania tej technologii w różnych branżach:




Podsumowanie
SparseOpt eliminuje glowna przeszkode w praktycznym stosowaniu treningu rzadkiego. Firmy rozwijajace modele na urzadzeniach brzegowych (edge computing) moga trenowac sieci bezposrednio na sprzecie o ograniczonej pamieci, bez kompromisu na dokladnosci. Zespoly ML, ktore szybko iteruja wiele wariantow architektury, skorzystaja na krotszym czasie treningu przy zachowaniu porownywalnej jakosci modelu. Trzecia naturalna domena to urzadzenia mobilne, gdzie kazdy megabajt pamieci i kazda milisekunda inferencji maja znaczenie.
Metryka artykułu źródłowego
Tytuł oryginalny: SparseOpt: Addressing Normalization-induced Gradient Skew in Sparse Training
Autorzy: Mohammed Adnan, Rohan Jain, Tom Jacobs, Ekansh Sharma, Rahul G. Krishnan, Rebekka Burkholz, Yani Ioannou
Data publikacji: 28 maja 2026
arXiv: arxiv.org/abs/2605.27541
Napisanie tego artykułu zostało wspomagane przez sztuczną inteligencję. Treść opiera się na oryginalnym artykule naukowym, a jej dokładność została zweryfikowana automatycznie.