

Prawie każdy globalny contact center ma ten sam problem: chatbot po angielsku działa bez zarzutu, a ten sam model po polsku, arabsku czy wietnamsku plącze się w zeznaniach, generuje nieprawidłowe decyzje i irytuje klientów. Efekt to rosnąca liczba eskalacji do konsultantów, dłuższy czas obsługi i koszty, które miały być cięte przez automatyzację - tymczasem rosną.
Dlaczego chatbot po polsku kuleje, choć model jest ten sam
Architektura Mixture-of-Experts (MoE), która stoi za największymi modelami językowymi, polega na tym, że w odpowiedzi na pytanie model aktywuje tylko część swoich specjalistycznych 'ekspertów'. W przypadku angielskiego działa to świetnie, bo dane treningowe są ogromne i model wie, do kogo skierować zapytanie o fakturę, a do kogo o reklamację. W językach o mniejszej reprezentacji routing - czyli decyzja o tym, który ekspert odpowie - często prowadzi do innych ścieżek. W efekcie ta sama de facto wiedza w modelu jest dostępna, ale nigdy nie zostaje wywołana. Z moich obserwacji wynika, że w firmach, które obsługują więcej niż 5 języków, różnica w skuteczności między angielskim a pozostałymi językami potrafi sięgać nawet 25-30 punktów procentowych.
RA-MoE: zamiast uczyć od nowa, poprawić drogę do eksperta
Badacze z zespołu Guanzhi Denga pokazali, że w warstwach środkowych modeli MoE istnieje tzw. uniwersalna strefa wyrównania - miejsce, gdzie sposób routingu w różnych językach szczególnie mocno koreluje z rozbieżnością wyników. Wychodząc od tego spostrzeżenia, zaproponowali RA-MoE, czyli metodę dostrajania, która nie zmienia architektury modelu i nie wymaga ogromnych korpusów w nowym języku. Zamiast tego dla par zdań, gdzie model dobrze odpowiada po angielsku, a źle po polsku (tzw. przykłady ci), nakłada dodatkową stratę, zmuszającą routing w języku docelowym do naśladowania wzorca aktywacji ekspertów z angielskiego. Technicznie rzecz biorąc, fine-tuning przebiega w trzech etapach: kategoryzacja przykładów, identyfikacja ekspertów istotnych dla zadania, a następnie doprecyzowanie routingu tak, by polskie pytania trafiały do tych samych specjalistów, co angielskie. To tak, jakby nauczyć bramkarza w call center, żeby każde pytanie o zwrot pieniędzy - niezależnie od języka - kierował do tego samego, kompetentnego działu.
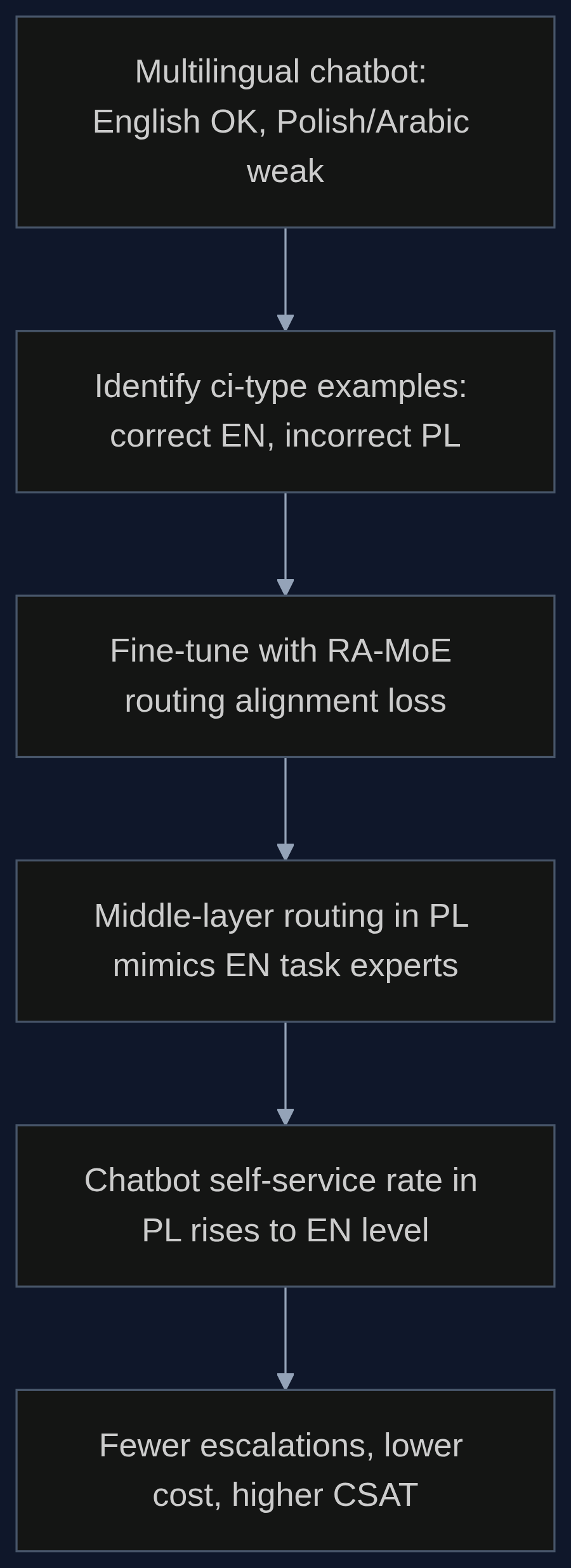
Przykład z życia: jak wypadłoby to w praktyce
Weźmy średniej wielkości globalny retailer z zespołem obsługi klienta obsługującym 12 języków. Obecnie ich chatbot wdrożony na platformie MoE rozwiązuje 80% spraw po angielsku, ale po polsku tylko 55%, po arabsku 50%. Oznacza to, że miesięcznie z 10 tysięcy czatów w języku polskim aż 4500 wymaga przejęcia przez agenta. Wdrożenie RA-MoE, polegające na dostrojeniu modelu na kilku tysiącach par przykładów (angielski-polski), podnosi skuteczność samoobsługi w tych językach do około 80-85% - tyle samo, co w angielskim. Dla wspomnianego retailer oznacza to spadek liczby czatów obsługiwanych ręcznie o 3000-3500 miesięcznie. Przy założeniu, że jeden czat agenta kosztuje 5 USD, roczna oszczędność sięga 200-250 tysięcy USD tylko na jednym języku. A to bez konieczności budowania osobnego modelu dla każdego języka czy zatrudniania dodatkowych konsultantów.
Korzyści i zwrot z inwestycji
Oszczędności to nie jedyna przewaga. Klient, który dostaje poprawną odpowiedź w 15 sekund zamiast czekać na połączenie z konsultantem, jest po prostu bardziej zadowolony. Menedżerowie CX wiedzą, że nawet drobna poprawa CSAT-u przekłada się na wskaźnik retencji i wartość koszyka. Dodatkowo, RA-MoE znacząco skraca czas potrzebny na rozszerzenie wsparcia chatbotowego na kolejne języki. Zamiast kilku miesięcy zbierania danych i trenowania, wystarczy zestaw kilkuset starannie dobranych par przykładów i dostrojenie istniejącego modelu. Koszt takiego projektu dla jednego języka to - szacuję - kilkanaście tysięcy dolarów, a zwrot następuje w ciągu pierwszych 2-3 miesięcy po wdrożeniu, jeśli ruch na linii jest choć umiarkowany. Co istotne, metoda działa z każdą architekturą MoE, więc ten sam zespół może ją powielać przy kolejnych wdrożeniach bez kupowania nowej infrastruktury.
Od czego zacząć?
Najprostszą drogą jest wybór jednego języka, w którym obecny bot notuje najwyższy odsetek eskalacji, i przygotowanie równoległego zestawu 500-1000 pytań po angielsku i w tym języku. Warto przyjrzeć się proporcji przykładów ci (poprawne po angielsku, błędne w docelowym) - według autorów RA-MoE ten właśnie wskaźnik najlepiej przewiduje, jak duży zysk przyniesie wyrównanie routingu. Im więcej takich par, tym szybciej zobaczycie efekty. Potem pozostaje już tylko standardowy proces fine-tuningu z dodatkową funkcją straty, co zespół ML potrafi zrealizować w ciągu tygodnia. Jeśli nie macie własnych zasobów do eksperymentów, warto rozważyć współpracę z zewnętrznym dostawcą, który wdrożył już RA-MoE na podobnym modelu MoE. Kluczowe jest, by nie czekać, aż konkurencja rozwiąże ten sam problem ciszej.
- Redukcja o 30-50% liczby eskalacji w językach niskich zasobów w ciągu 1-2 miesięcy
- Zwrot z inwestycji w 2-3 miesiące przy koszcie wdrożenia kilkunastu tysięcy USD na język
- Do 25 p.p. wzrost skuteczności samoobsługi bez budowania modeli od zera dla każdego języka
- Możliwość skalowania na nowe języki w ciągu tygodnia, przy minimalnym zbiorze danych treningowych
- Poprawa CSAT i retencji klientów dzięki spójnej jakości obsługi we wszystkich kanałach językowych
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: Routing-Aligned Fine-Tuning for Multilingual Downstream Tasks in Mixture-of-Experts Models
Autorzy: Guanzhi Deng, Kuan Wu, Haibo Wang, Shing Yin Wong, Sichun Luo i in.
Mixture-of-Experts (MoE) models have emerged as a dominant paradigm for efficient LLM scaling, yet adapting them to non-English downstream tasks remains challenging. Existing fine-tuning approaches treat MoE models as monolithic learners, ignoring the heterogeneous routing structure that develops...
arXiv: arxiv.org/abs/2605.28306
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}