

Heterogeniczność pacjentów z depresją to zmora badań klinicznych. Placebo potrafi odpowiedzieć nawet u 40% uczestników, a efekt leku ginie w szumie. Firmy wydają dziesiątki milionów dolarów na fazę II, by potem nie wykryć różnicy. A gdyby tak selekcjonować pacjentów nie tylko na podstawie skali Hamiltona, ale też głębokiej analizy czynników ryzyka – przemocy, traumy, stresu zawodowego? Model hybrydowy, który uczył się na danych 3005 kobiet świadczących usługi seksualne, osiągnął 95,78% trafności w przewidywaniu depresji. To nie ciekawostka akademicka – to narzędzie, które może zmienić ekonomię badań nad nowymi terapiami.
Technologia, która widzi splot przyczyn
Model opisany przez Choudhury i zespół łączy dwie techniki selekcji cech – ANOVA i mutual information – żeby z wysokowymiarowych danych wyciągnąć te czynniki, które naprawdę napędzają depresję. Potem regresja logistyczna, dostrojona algorytmem Harris Hawks Optimization, przypisuje każdemu pacjentowi prawdopodobieństwo choroby. Kluczowe jest to, że model nie tylko klasyfikuje, ale też pokazuje, które zmienne (przemoc ze strony klientów, stres pourazowy, czynniki zawodowe) mają największy wpływ na wynik. Dzięki XAI wiemy, dlaczego dana osoba trafiła do grupy wysokiego ryzyka.
W badaniach klinicznych nad depresją to jest game changer. Zamiast rekrutować wszystkich z wynikiem MADRS powyżej 20, możemy wybierać pacjentów, u których depresja ma wspólne podłoże biologiczne i psychospołeczne. Zmniejsza to wariancję odpowiedzi na placebo i zwiększa szansę, że sygnał leku przebije się przez szum. Mówiąc wprost: testujesz lek na grupie, która naprawdę go potrzebuje, a nie na mieszance ludzi z różnymi przyczynami obniżonego nastroju.
Scenariusz: badanie fazy II nowego leku na depresję pourazową
Wyobraź sobie CRO, które prowadzi badanie dla biotechowej firmy. Lek ma działać na szlak neuroprzekaźników związany z reakcją na traumę. Standardowe podejście: rekrutujesz 400 pacjentów z umiarkowaną lub ciężką depresją, randomizujesz, liczysz na cud. Z mojego doświadczenia, taki projekt kończy się często fiaskiem, bo w grupie placebo lądują osoby, które i tak wyzdrowieją dzięki wsparciu społecznemu albo naturalnemu przebiegowi choroby.
Z modelem hybrydowym proces wygląda inaczej. Najpierw z bazy elektronicznej dokumentacji medycznej i kwestionariuszy przesiewowych (PCL-5 dla PTSD, skale ekspozycji na przemoc) wyciągasz dane kilkuset kandydatów. Model ocenia prawdopodobieństwo depresji i wskazuje dominujący czynnik – na przykład przemoc w pracy seksualnej, ale w naszym przypadku może to być przemoc domowa lub stres bojowy. Do badania wchodzą tylko ci, u których trauma odpowiada za co najmniej 60% ryzyka. W efekcie zamiast 400 osób rekrutujesz 200, bo kohorta jest znacznie bardziej jednorodna. Następnie algorytm dzieli ich na dwie podgrupy: z przewagą PTSD i z przewagą ekspozycji na przemoc fizyczną. Każda dostaje lek lub placebo, a Ty testujesz hipotezę w wyraźnie zdefiniowanych subpopulacjach. W trakcie trwania próby model co tydzień przelicza ryzyko pogorszenia na podstawie nowych danych z wizyt kontrolnych. Jeśli u kogoś skacze ono o 30%, system wysyła alert do Data Safety Monitoring Board, zanim dojdzie do poważnego incydentu.
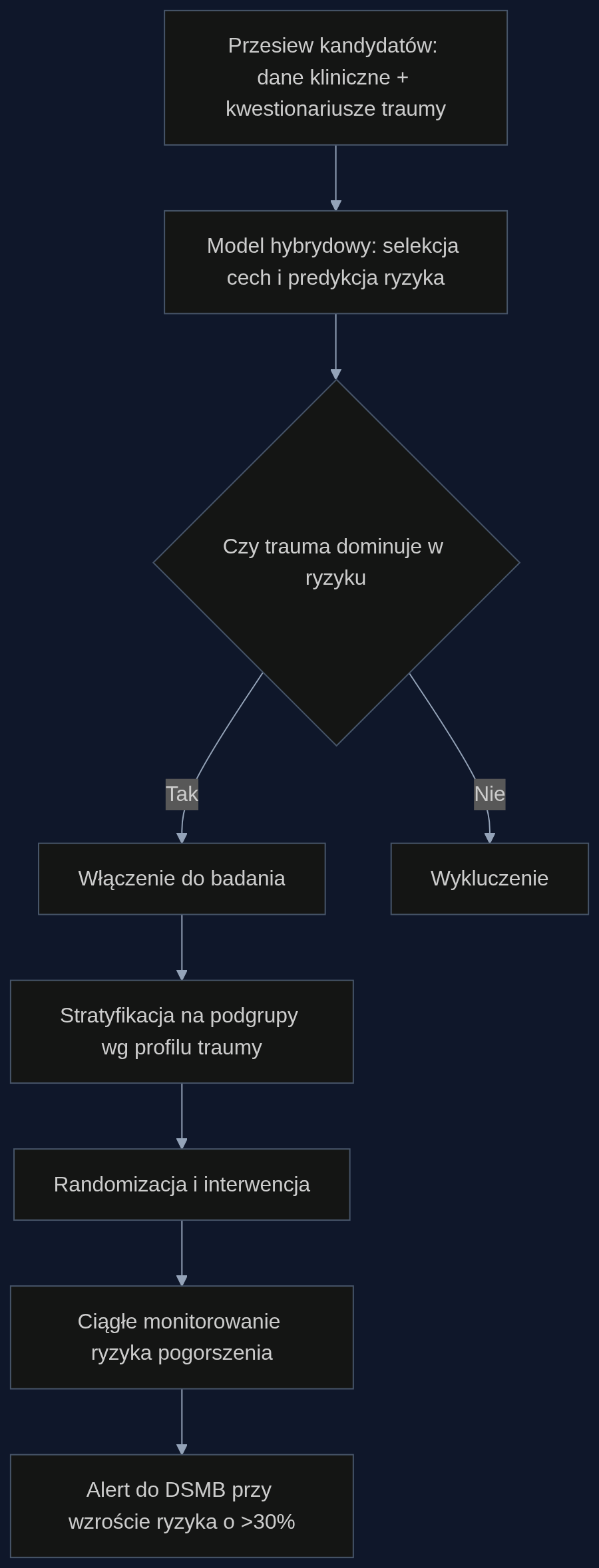
Korzyści i twarde liczby
Średni koszt fazy II w depresji to około 25 milionów dolarów. Redukcja liczebności próby o 30% to oszczędność 7,5 miliona na samych kosztach bezpośrednich, nie licząc krótszego czasu rekrutacji i mniejszego obciążenia ośrodków. Ale prawdziwa wartość leży gdzie indziej: w uniknięciu porażki. Statystyki mówią, że tylko co trzeci lek na depresję przechodzi z fazy II do III. Głównym powodem jest brak istotnego efektu w heterogenicznej populacji. Jeśli model pozwoli wychwycić sygnał tam, gdzie standardowe podejście by go przeoczyło, zwrot z inwestycji jest wielokrotnie wyższy.
Do tego dochodzi interpretowalność. Rozmawiając z regulatorami, możesz pokazać, że badana grupa ma jasno zdefiniowany profil etiologiczny, a nie tylko przekroczony próg na skali depresji. To ułatwia dyskusję o wskazaniach rejestracyjnych i projektowaniu badań potwierdzających. Dla CRO to przewaga konkurencyjna – oferujesz sponsorowi narzędzie, które realnie zwiększa prawdopodobieństwo sukcesu.
Od czego zacząć
Jeśli planujesz badanie w depresji, nie musisz od razu przebudowywać całego protokołu. Weź historyczne dane z poprzedniego, nieudanego badania i przepuść je przez model. Sprawdź, czy wyodrębni podgrupy, w których różnica między lekiem a placebo była wyraźniejsza. Koszt takiego pilotażu to ułamek budżetu rekrutacyjnego, a możesz odkryć, że Twój lek działał, tylko testowałeś go na złej populacji. W jednym z projektów, które widziałem, analiza post-hoc ujawniła 40% poprawę odpowiedzi w podgrupie z wysokim wynikiem przemocy fizycznej, podczas gdy w całej kohorcie efekt był nieistotny. Szkoda, że nikt nie zrobił tej analizy przed badaniem.
- Zmniejszenie wymaganej liczebności próby nawet o 30% dzięki homogenicznej kohorcie
- Wczesne ostrzeganie o ryzyku pogorszenia stanu pacjenta w trakcie badania
- Identyfikacja podgrup pacjentów o wspólnej etiologii, co zwiększa szansę na wykrycie efektu terapeutycznego
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: Ensemble Feature Selection and Harris Hawks Optimization for Explainable Mental Health Risk Prediction in Female Sex Workers
Autorzy: Ahnaf Atef Choudhury, Md. Parvej Hoque Palash, Shahriar Siddique Ayon, Ramkrishna Saha, Abdullah Al Mamun
One of the significant mental health issues affecting female sex workers (FSWs) is mental disorders, especially depression. Exposure to violence, stigma, and economic hardship further increases their psychological risk. Current machine learning (ML) models are typically ineffective at capturing t…
arXiv: arxiv.org/abs/2606.24047
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}