
Płacisz za każde słowo, nawet jeśli go nie wypowiadasz. Modele językowe rozliczają nas od tokenu, ale token to nie to samo co słowo, a dla niektórych języków ten sam komunikat rozpada się na znacznie więcej tokenów niż dla angielskiego. Olaoye Anthony Somide w nowej pracy pokazuje, że użytkownicy języków afrykańskich płacą ukryty ‘podatek tokenizacyjny’, który może sięgać niemal dziewięciu razy więcej – zanim model w ogóle zacznie przetwarzać pytanie.
Tokenizacja: rozbijanie słów na kawałki
Zanim duży model językowy przeczyta nasze zapytanie, algorytm zwany tokenizerem tnie tekst na mniejsze jednostki – tokeny. Dla angielskiego słowo ‘the’ to często jeden token. Dla polskiego ‘niebieskiego’ może być ich kilka. To, jak drobno siekamy, zależy od słownika podrzędnego wytrenowanego na danych treningowych, a te są zdominowane przez języki o dużych korpusach, głównie angielski.
Problem w tym, że modele komercyjne rozliczają się per token. Opóźnienie i długość kontekstu też skalują się z liczbą tokenów. Jeśli ten sam komunikat w języku X generuje więcej tokenów niż w angielskim, użytkownik X płaci wyższą cenę za to samo znaczenie, a dodatkowo szybciej ‘wyjada’ limit okna kontekstowego. To jakby za litr mleka w jednym sklepie płacić za mililitry, a w drugim za całe opakowanie, choć zawartość jest taka sama.
Somide nazywa to ‘płodnością tokenizacji’ (token-fertility) i mierzy ją jako stosunek liczby tokenów do tego samego znaczenia w porównaniu z angielskim. Im wyższy wskaźnik, tym większy ukryty podatek.
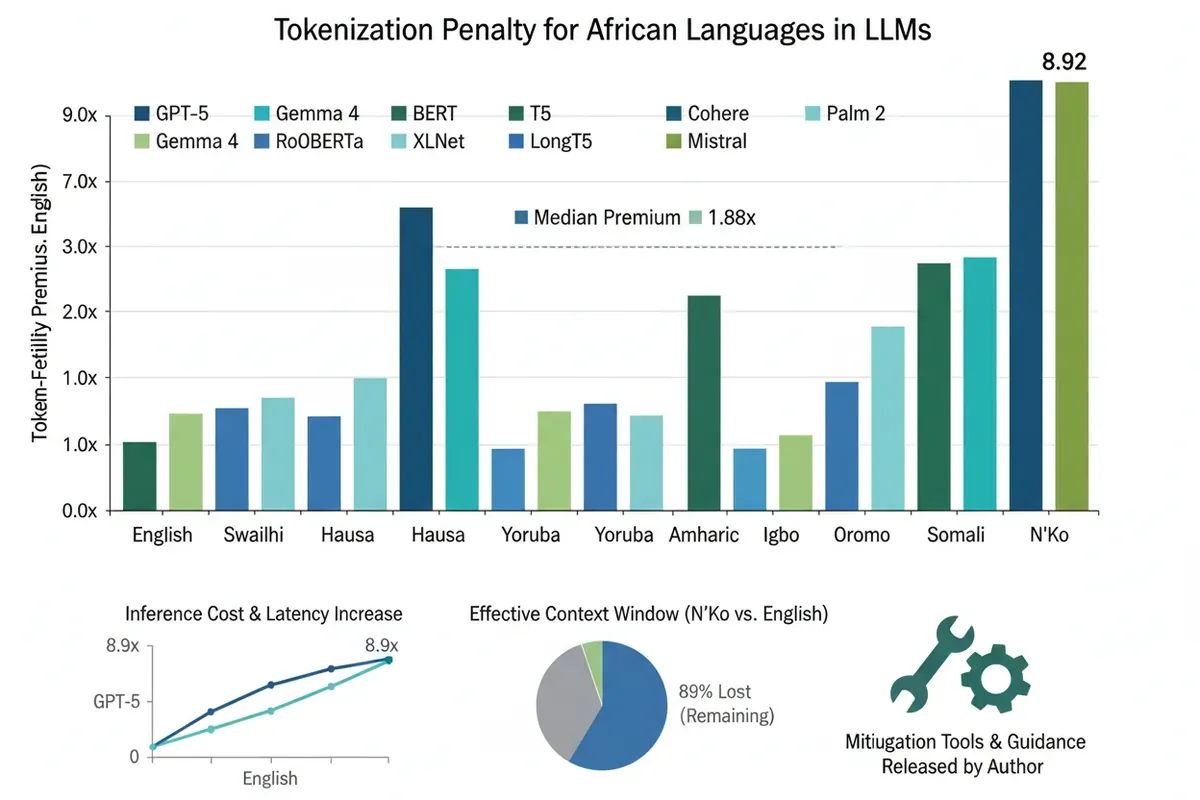
Mediana 1,88, ekstrema do 8,92 razy więcej
W badaniu użyto równoległych korpusów (FLORES-200+ i SIB-200), aby porównać dokładnie te same zdania w 20 językach afrykańskich i 11 tokenizerach, w tym najnowszym o200k_base z GPT-5. Wyniki są druzgocące. Względem angielskiego każdy testowany język afrykański ma premię tokenizacyjną. Mediana na tokenizerze GPT-5 to 1,88 – czyli prawie dwa razy więcej tokenów na tę samą treść. Dla języków zapisywanych pismem n’ko (jak mandinka) premia sięga 8,92.
To nie jest efekt jednego korpusu. Korelacja między wynikami z FLORES i SIB-200 wyniosła 0,9998. Innymi słowy, strukturalny problem tkwi w tokenizerze, nie w konkretnym zestawie zdań. Nawet języki z alfabetem łacińskim, jak suahili czy joruba, notują premie rzędu 1,5-2,5 razy. Pisma etiopskie (ge’ez) i n’ko windowane są najbardziej.
Somide pisze: ‘Komercyjne duże modele językowe rozliczają się, skalują opóźnienia i budżetują kontekst na token. Ale tokenizery przypisują więcej tokenów podrzędnych temu samemu znaczeniu w niektórych językach niż w innych, więc użytkownicy języków o wysokiej płodności tokenów płacą strukturalną karę, zanim model w ogóle zostanie uruchomiony’.
Komercyjne duże modele językowe rozliczają się, skalują opóźnienia i budżetują kontekst na token. Ale tokenizery przypisują więcej tokenów podrzędnych temu samemu znaczeniu w niektórych językach niż w innych, więc użytkownicy języków o wysokiej płodności tokenów płacą strukturalną karę, zanim model w ogóle zostanie uruchomiony.
Olaoye Anthony Somide
arXiv:2606.24460
Konsekwencje w praktyce: koszty, opóźnienie, utrata kontekstu
Co te liczby oznaczają w realnym użytkowaniu? Jeśli premia tokenizacji wynosi 8,9x, to koszt wnioskowania i opóźnienie rosną w tym samym stosunku. Model, który dla angielskiego może obsłużyć zapytanie w pół sekundy, dla języka n’ko będzie potrzebował kilku sekund. W systemach produkcyjnych, gdzie liczy się każda milisekunda, to poważna bariera.
Jeszcze dotkliwsze jest kurczenie się efektywnego okna kontekstowego. Modele mają ograniczoną liczbę tokenów, które mogą przetworzyć naraz (np. 128 tysięcy). Jeśli tekst w języku n’ko wymaga dziewięciu razy więcej tokenów niż po angielsku, realnie można zmieścić tylko 11% oryginalnej pojemności – około 14 tysięcy tokenów. To oznacza, że długie dokumenty, podręczniki czy historie rozmów nie mieszczą się w pamięci modelu, co drastycznie ogranicza funkcjonalność dla tych społeczności.
‘Kara spada najciężej na języki, których użytkownicy najmniej mogą sobie na nią pozwolić. To cyfrowy podział zakodowany bezpośrednio w słowniku podrzędnym’ – podsumowuje autor. Faktycznie, w krajach o niższych dochodach, gdzie dopiero buduje się cyfrową infrastrukturę, dodatkowe koszty i słabsza wydajność modeli mogą pogłębić wykluczenie.
Czy jest jakaś nadzieja?
Testowano wiele tokenizerów. Najlepszy z obecnie dostępnych, Gemma 4, obniża średnią premię z 3,31 (dla starszego cl100k_base) do 2,38. To postęp, ale nadal nie eliminuje problemu. Żaden z 11 badanych tokenizerów nie zrównał języków afrykańskich z angielskim.
Źródło problemu nie leży w złośliwości, lecz w danych. Tokenizery uczą się statystyk podziału na podstawie korpusów treningowych, a te są przytłaczająco angielskocentryczne. Skrypty używane przez małe społeczności – jak n’ko, które ma zaledwie kilkadziesiąt lat i jest używane przez kilka milionów osób – prawie nie występują w danych. Model po prostu nie wie, jak efektywnie pokroić te znaki, więc dzieli je na bardzo małe kawałki.
Somide udostępnia narzędzia i wskazówki, jak minimalizować skutki: świadome skracanie promptów, wybór tokenizera przyjaznego danemu językowi, czy post-processing, który ogranicza powtarzanie. To protezy, nie lekarstwo. Prawdziwa naprawa wymagałaby włączenia większej ilości tekstów afrykańskich do korpusów treningowych już na etapie budowania słownika tokenizera.
- Każdy testowany język afrykański ma premię tokenizacyjną powyżej angielskiego, mediana na GPT-5 to 1,88x, a maksimum 8,92x dla n’ko.
- Premia przekłada się bezpośrednio na koszt i opóźnienie – do 8,9 razy wyższe – oraz na drastyczne skrócenie efektywnego okna kontekstowego (do 11% pojemności angielskiego).
- Najlepszy istniejący tokenizer (Gemma 4) redukuje średnią premię z 3,31 do 2,38, ale żaden nie likwiduje nierówności.
- Problem wynika z niedoreprezentowania afrykańskich skryptów w danych treningowych tokenizerów.
- Autor udostępnia narzędzia do mitygacji, ale podkreśla, że trwałe rozwiązanie wymaga włączenia tych języków do procesów treningowych.
Praktyczne zastosowania
Aby lepiej zrozumieć opisywaną innowację, przygotowaliśmy cztery przykłady praktycznego zastosowania tej technologii w różnych branżach:



Podsumowanie
Firmy wdrażające chatboty, analizę dokumentów czy tłumaczenia maszynowe na rynkach afrykańskich muszą liczyć się z wyższymi kosztami i gorszą wydajnością, jeśli korzystają z domyślnych tokenizerów. Dla e-commerce obsługującego klientów w joruba czy suahili oznacza to wyższe rachunki za API i wolniejsze odpowiedzi. W tłumaczeniach automatycznych ograniczone okno kontekstowe może zmniejszać jakość długich tekstów. Świadomość problemu pozwala już dziś wybierać lepsze tokenizery (jak Gemma 4) lub optymalizować długość promptów, a w dłuższej perspektywie – domagać się od dostawców modeli sprawiedliwszej reprezentacji językowej już na etapie treningu.
Metryka artykułu źródłowego
Tytuł oryginalny: The African Language Tax: Quantifying the Cost, Latency, and Context Penalty of Tokenizing African Languages in Frontier LLMs
Autorzy: Olaoye Anthony Somide
Data publikacji: 24 czerwca 2026
arXiv: arxiv.org/abs/2606.24460
Napisanie tego artykułu zostało wspomagane przez sztuczną inteligencję. Treść opiera się na oryginalnym artykule naukowym, a jej dokładność została zweryfikowana automatycznie.
{kind=link}